
1. 概要
|
|

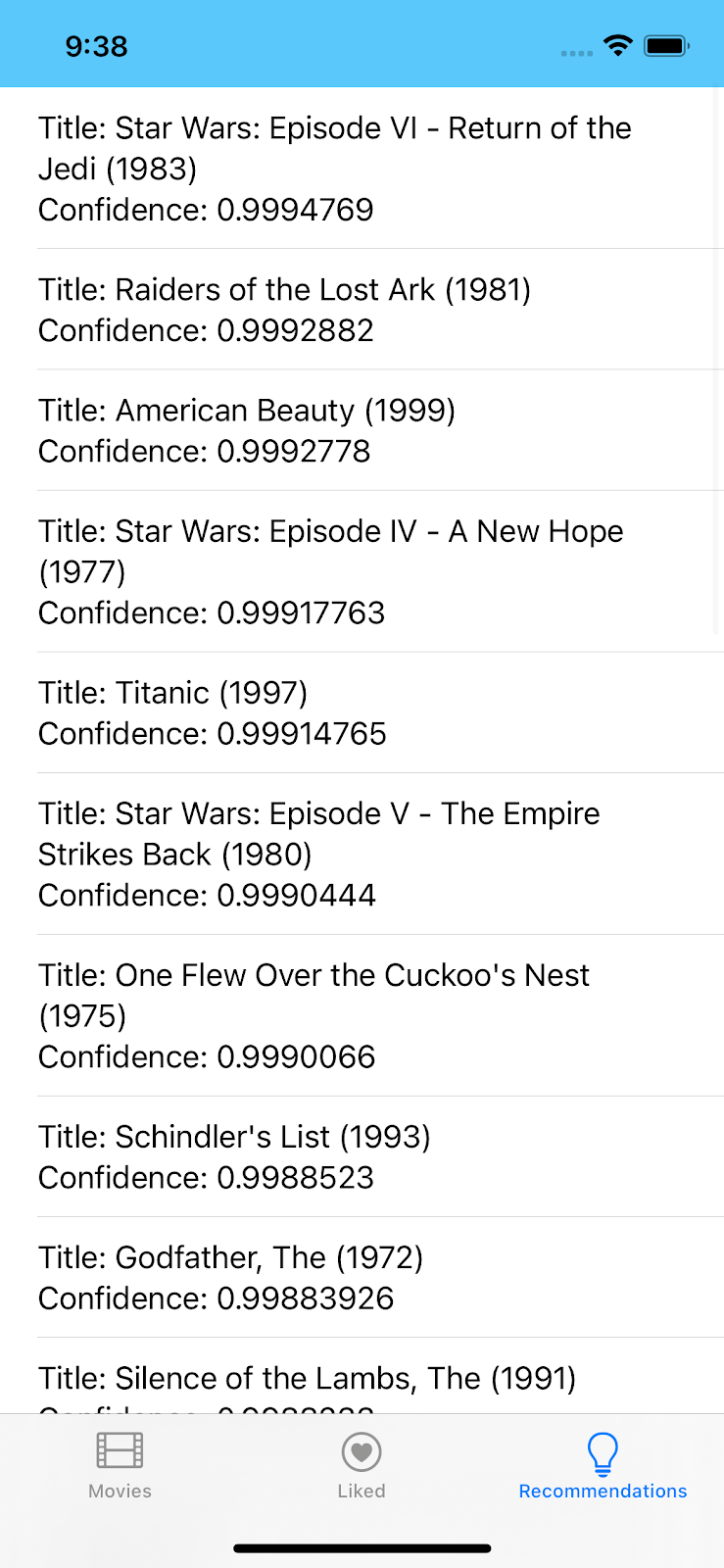
TensorFlow Lite と Firebase を使用したレコメンデーションの Codelab へようこそ。この Codelab では、TensorFlow Lite と Firebase を使用して、おすすめモデルをアプリにデプロイする方法について説明します。この Codelab は、この TensorFlow Lite の例に基づいています。
レコメンデーションを使用すると、アプリは機械学習を使用して、各ユーザーに最も関連性の高いコンテンツをインテリジェントに提供できます。過去のユーザー行動を考慮して、他の多数のユーザーの行動を集計してトレーニングしたモデルを使用し、ユーザーが今後操作する可能性のあるアプリのコンテンツを提案します。
このチュートリアルでは、Firebase アナリティクスを使用してアプリのユーザーからデータを取得し、そのデータからレコメンデーション用の機械学習モデルを構築して、そのモデルを iOS アプリで使用して推論を実行し、レコメンデーションを取得する方法について説明します。特に、おすすめでは、ユーザーが以前に高評価した映画のリストに基づいて、ユーザーが視聴する可能性が最も高い映画を提案します。
学習内容
- Firebase アナリティクスを Android アプリに統合してユーザー行動データを収集する
- そのデータを Google Big Query にエクスポートする
- データを前処理して TF Lite レコメンデーション モデルをトレーニングする
- TF Lite モデルを Firebase ML にデプロイし、アプリからアクセスする
- モデルを使用してオンデバイス推論を実行し、ユーザーに推奨事項を提案する
必要なもの
- Xcode 11(以降)
- CocoaPods 1.9.1 以降
このチュートリアルをどのように使用されますか?
iOS アプリ作成のご経験についてお答えください。
2. Firebase コンソール プロジェクトを作成する
プロジェクトに Firebase を追加する
- Firebase コンソールに移動します。
- [Create New Project] を選択し、プロジェクトに「Firebase ML iOS Codelab」という名前を付けます。
3. サンプル プロジェクトを取得する
コードのダウンロード
まず、サンプル プロジェクトのクローンを作成し、プロジェクト ディレクトリで pod update を実行します。
git clone https://github.com/FirebaseExtended/codelab-contentrecommendation-ios.git cd codelab-contentrecommendation-ios/start pod install --repo-update
git をインストールしていない場合は、GitHub ページからサンプル プロジェクトをダウンロードするか、このリンクをクリックしてダウンロードすることもできます。プロジェクトをダウンロードしたら、Xcode で実行して、おすすめを試して動作を確認します。
Firebase を設定する
ドキュメントに沿って、新しい Firebase プロジェクトを作成します。プロジェクトを取得したら、Firebase コンソールからプロジェクトの GoogleService-Info.plist ファイルをダウンロードし、Xcode プロジェクトのルートにドラッグします。

Podfile に Firebase を追加して、pod install を実行します。
pod 'FirebaseAnalytics' pod 'FirebaseMLModelDownloader', '9.3.0-beta' pod 'TensorFlowLiteSwift'
AppDelegate の didFinishLaunchingWithOptions メソッドで、ファイルの先頭に Firebase をインポートします。
import FirebaseCore
また、Firebase を構成する呼び出しを追加します。
FirebaseApp.configure()
プロジェクトを再度実行して、アプリが正しく設定されており、起動時にクラッシュしないことを確認します。
- [このプロジェクトで Google アナリティクスを有効にする] が有効になっていることを確認します。
- Firebase コンソールで残りの設定手順を実施した後、[プロジェクトを作成](既存の Google プロジェクトを使用する場合は [Firebase を追加])をクリックします。
4. アプリに Firebase 向け Google アナリティクスを追加する
この手順では、Firebase 向け Google アナリティクスをアプリに追加して、ユーザーの行動データ(この場合はユーザーがどの映画を気に入ったか)を記録します。このデータは、今後の手順で集計され、おすすめモデルのトレーニングに使用されます。
アプリで Firebase 向け Google アナリティクスを設定する
LikedMoviesViewModel には、ユーザーが気に入った映画を保存する関数が含まれています。ユーザーが新しい映画を高く評価するたびに、その評価を記録する分析ログイベントも送信します。
ユーザーが映画に「いいね」をクリックしたときにアナリティクス イベントを登録するコードを以下に追加します。
AllMoviesCollectionViewController.swift
import FirebaseAnalytics
//
override func collectionView(_ collectionView: UICollectionView, didSelectItemAt indexPath: IndexPath) {
//
if movie.liked == nil {
movie.liked = true
Analytics.logEvent(AnalyticsEventSelectItem, parameters: [AnalyticsParameterItemID: movie.id])
} else {
movie.liked?.toggle()
}
}
5. アナリティクス統合をテストする
このステップでは、アプリでアナリティクス イベントを生成し、Firebase コンソールに送信されていることを確認します。
アナリティクスのデバッグ ロギングを有効にする
一般的に、アプリによってロギングされるイベントは、約 1 時間の周期でバッチ処理され、まとめてアップロードされます。このアプローチにより、エンドユーザーのデバイスのバッテリーを節約し、ネットワーク データの使用量を削減します。ただし、アナリティクスの実装を検証する(また、DebugView レポートでアナリティクスを確認する)目的では、開発デバイスでデバッグモードを有効にすることで、最小限の遅延でイベントをアップロードできます。
開発用デバイスでアナリティクスのデバッグモードを有効にするには、Xcode で次のコマンドライン引数を指定します。
-FIRDebugEnabled
これで、Firebase 向け Google アナリティクスがアプリに統合されました。ユーザーがアプリを使用して映画に「いいね」すると、その「いいね」が集計されて記録されます。この Codelab の以降の部分では、この集計データを使用してレコメンデーション モデルをトレーニングします。次の手順は、Logcat で確認したアナリティクス イベントが Firebase コンソールにもストリーミングされることを確認するための省略可能な手順です。次のページに進んでください。
省略可: Firebase コンソールでアナリティクス イベントを確認する
- Firebase コンソールに移動します。
- [アナリティクス] で [DebugView] を選択します。
- Xcode で [実行] を選択してアプリを起動し、[高評価] リストに映画を追加します。
- Firebase コンソールの DebugView で、アプリに映画を追加する際にこれらのイベントが記録されていることを確認します。
6. アナリティクス データを BigQuery にエクスポートする
BigQuery は、大量のデータを検査して処理できる Google Cloud プロダクトです。このステップでは、Firebase コンソール プロジェクトを BigQuery に接続して、アプリで生成されたアナリティクス データが BigQuery に自動的にエクスポートされるようにします。
BigQuery エクスポートを有効にする
- Firebase コンソールに移動します。
- [プロジェクトの概要] の横にある設定の歯車アイコンを選択し、[プロジェクトの設定] を選択します。
- [統合] タブを選択します。
- [BigQuery] ブロック内で [リンク](または [管理])を選択します。
- [Firebase と BigQuery のリンクについて] の手順で、[次へ] を選択します。
- [統合を構成] セクションで、スイッチをクリックして Google アナリティクス データの送信を有効にし、[BigQuery にリンク] を選択します。
これで、Firebase コンソール プロジェクトで Firebase アナリティクス イベント データを BigQuery に自動的に送信できるようになりました。この処理は自動的に行われますが、BigQuery に分析データセットを作成する初回のエクスポートは 24 時間以内に行われない場合があります。データセットが作成されると、Firebase は新しいアナリティクス イベントを BigQuery の当日テーブルに継続的にエクスポートし、過去のイベントをイベント テーブルにグループ化します。
レコメンデーション モデルのトレーニングには大量のデータが必要です。大量のデータを生成するアプリはまだないため、次のステップでは、このチュートリアルの残りの部分で使用するサンプル データセットを BigQuery にインポートします。
7. BigQuery を使用してモデルのトレーニング データを取得する
Firebase コンソールを BigQuery へのエクスポートに接続したので、アプリ分析のイベントデータはしばらくすると BigQuery コンソールに自動的に表示されます。このチュートリアルで使用する初期データを取得するため、このステップでは、既存のサンプル データセットを BigQuery コンソールにインポートして、レコメンデーション モデルのトレーニングに使用します。
サンプル データセットを BigQuery にインポートする
- Google Cloud コンソールの BigQuery ダッシュボードに移動します。
- メニューでプロジェクト名を選択します。
- BigQuery の左側のナビゲーションの下部にあるプロジェクト名を選択して、詳細を表示します。
- [データセットを作成] を選択して、データセット作成パネルを開きます。
- [データセット ID] に「firebase_recommendations_dataset」と入力し、[データセットを作成] を選択します。
- 新しいデータセットが左側のメニューのプロジェクト名の下に表示されます。これをクリックします。
- [テーブルを作成] を選択して、テーブル作成パネルを開きます。
- [テーブルの作成元] で [Google Cloud Storage] を選択します。
- [GCS バケットからファイルを選択] フィールドに「gs://firebase-recommendations/recommendations-test/formatted_data_filtered.txt」と入力します。
- [ファイル形式] プルダウンで [JSONL] を選択します。
- [テーブル名] に「recommendations_table」と入力します。
- [スキーマ > 自動検出 > スキーマと入力パラメータ] のチェックボックスをオンにします。
- [テーブルを作成] を選択します。
サンプル データセットを探索する
この時点で、必要に応じてスキーマを探索し、このデータセットをプレビューできます。
- 左側のメニューで [firebase-recommendations-dataset] を選択して、含まれているテーブルを開きます。
- recommendations-table テーブルを選択して、テーブル スキーマを表示します。
- [プレビュー] を選択すると、このテーブルに含まれる実際のアナリティクス イベント データが表示されます。
サービス アカウントの認証情報を作成する
次のステップでは、Google Cloud コンソール プロジェクトにサービス アカウントの認証情報を作成し、Colab 環境で使用して BigQuery データにアクセスして読み込みます。
- Google Cloud プロジェクトの課金が有効になっていることを確認します。
- BigQuery API と BigQuery Storage API を有効にします。<こちらをクリック>
- [サービス アカウント キーの作成] ページに移動します。
- [サービス アカウント] リストから [新しいサービス アカウント] を選択します。
- [サービス アカウント名] フィールドに名前を入力します。
- [役割] リストで、[プロジェクト] > [オーナー] を選択します。
- [作成] をクリックします。キーを含む JSON ファイルがパソコンにダウンロードされます。
次のステップでは、Google Colab を使用してこのデータを前処理し、レコメンデーション モデルをトレーニングします。
8. データを前処理してレコメンデーション モデルをトレーニングする
このステップでは、Colab ノートブックを使用して次の手順を行います。
- BigQuery データを Colab ノートブックにインポートする
- モデルのトレーニング用にデータを前処理する
- 分析データでレコメンデーション モデルをトレーニングする
- モデルを TF Lite モデルとしてエクスポートする
- アプリで使用できるように、モデルを Firebase コンソールにデプロイする
Colab トレーニング ノートブックを起動する前に、まず Firebase Model Management API を有効にして、Colab がトレーニング済みモデルを Firebase コンソールにデプロイできるようにします。
Firebase Model Management API を有効にする
ML モデルを保存するバケットを作成する
Firebase コンソールで、[Storage] に移動して [始める] をクリックします。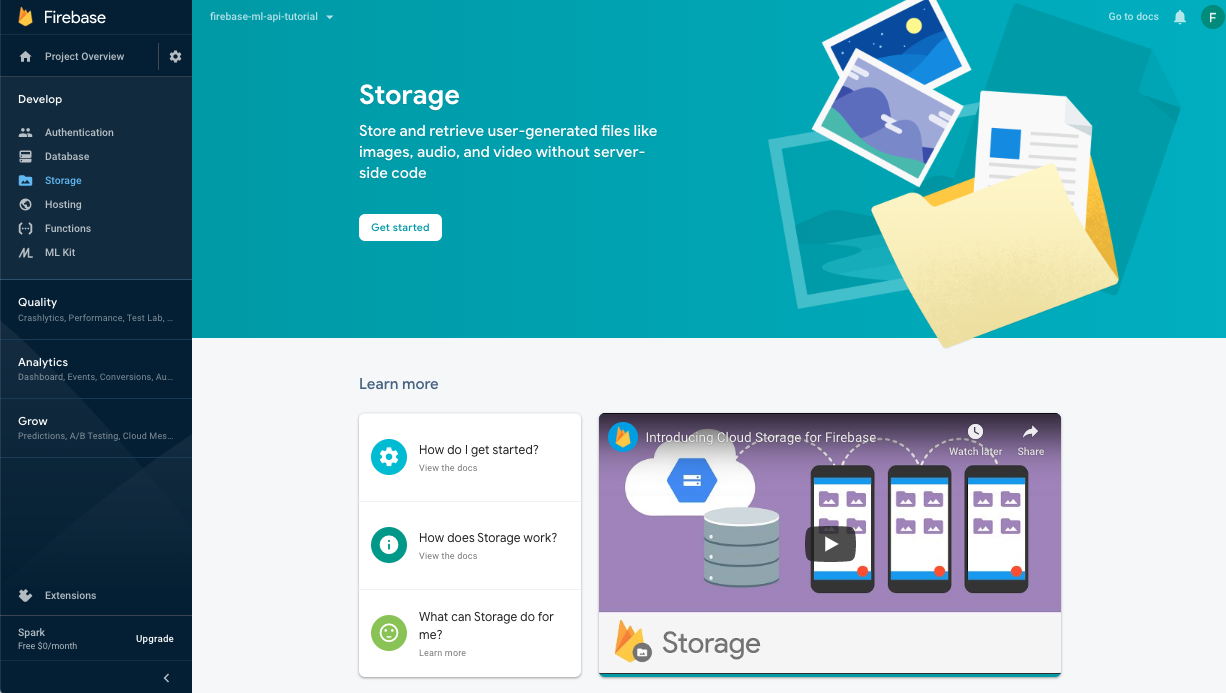
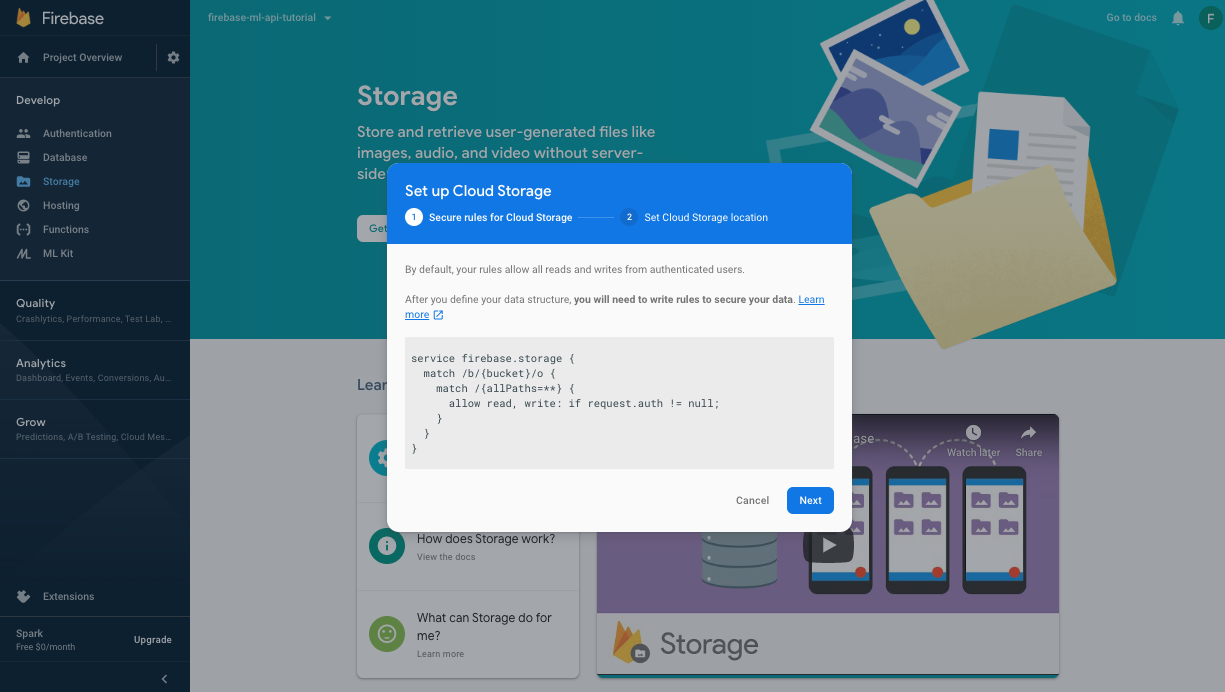
ダイアログに沿ってバケットを設定します。
Firebase ML API を有効にする
Google Cloud コンソールで Firebase ML API ページに移動し、[有効にする] をクリックします。
Colab ノートブックを使用してモデルをトレーニングしてデプロイする
次のリンクを使用して Colab ノートブックを開き、手順を完了します。Colab ノートブックの手順を完了すると、Firebase コンソールに TF Lite モデルファイルがデプロイされ、アプリに同期できるようになります。
Colab で開く
9. アプリでモデルをダウンロードする
このステップでは、先ほど Firebase Machine Learning でトレーニングしたモデルをダウンロードするようにアプリを変更します。
Firebase ML の依存関係を追加する
アプリで Firebase ML モデルを使用するには、次の依存関係が必要です。これはすでに追加されているはずです(確認してください)。
Podfile
import FirebaseCore
import FirebaseMLModelDownloader
Firebase Model Manager API を使用してモデルをダウンロードする
次のコードを ModelLoader.swift にコピーして、モデルのダウンロードが発生する条件を設定し、リモートモデルをアプリに同期するダウンロード タスクを作成します。
ModelLoader.swift
static func downloadModel(named name: String,
completion: @escaping (CustomModel?, DownloadError?) -> Void) {
guard FirebaseApp.app() != nil else {
completion(nil, .firebaseNotInitialized)
return
}
guard success == nil && failure == nil else {
completion(nil, .downloadInProgress)
return
}
let conditions = ModelDownloadConditions(allowsCellularAccess: false)
ModelDownloader.modelDownloader().getModel(name: name, downloadType: .localModelUpdateInBackground, conditions: conditions) { result in
switch (result) {
case .success(let customModel):
// Download complete.
// The CustomModel object contains the local path of the model file,
// which you can use to instantiate a TensorFlow Lite classifier.
return completion(customModel, nil)
case .failure(let error):
// Download was unsuccessful. Notify error message.
completion(nil, .downloadFailed(underlyingError: error))
}
}
}
10. Tensorflow Lite のレコメンデーション モデルをアプリに統合する
Tensorflow Lite ランタイムを使用すると、アプリでモデルを使用して推奨事項を生成できます。前のステップでは、ダウンロードしたモデルファイルを使用して TFlite インタープリタを初期化しました。このステップでは、まず推論ステップでモデルに付随する辞書とラベルを読み込み、次にモデルへの入力を生成する前処理と、推論から結果を抽出する後処理を追加します。
Load Dictionary and Labels
レコメンデーション モデルがレコメンデーション候補の生成に使用するラベルは、アセット フォルダの sorted_movie_vocab.json ファイルに一覧表示されます。次のコードをコピーして、これらの候補を読み込みます。
RecommendationsViewController.swift
func getMovies() -> [MovieItem] {
let barController = self.tabBarController as! TabBarController
return barController.movies
}
前処理を実装する
前処理のステップでは、モデルが想定する形式に合わせて入力データの形式を変更します。ここでは、ユーザーの「いいね」がまだ多く生成されていない場合は、プレースホルダ値で入力長をパディングします。次のコードをコピーします。
RecommendationsViewController.swift
// Given a list of selected items, preprocess to get tflite input.
func preProcess() -> Data {
let likedMovies = getLikedMovies().map { (MovieItem) -> Int32 in
return MovieItem.id
}
var inputData = Data(copyingBufferOf: Array(likedMovies.prefix(10)))
// Pad input data to have a minimum of 10 context items (4 bytes each)
while inputData.count < 10*4 {
inputData.append(0)
}
return inputData
}
インタープリタを実行して推奨事項を生成する
ここでは、前のステップでダウンロードしたモデルを使用して、前処理された入力に対して推論を実行します。モデルの入力と出力のタイプを設定し、推論を実行して映画のレコメンデーションを生成します。次のコードをアプリにコピーします。
RecommendationsViewController.swift
import TensorFlowLite
RecommendationsViewController.swift
private var interpreter: Interpreter?
func loadModel() {
// Download the model from Firebase
print("Fetching recommendations model...")
ModelDownloader.fetchModel(named: "recommendations") { (filePath, error) in
guard let path = filePath else {
if let error = error {
print(error)
}
return
}
print("Recommendations model download complete")
self.loadInterpreter(path: path)
}
}
func loadInterpreter(path: String) {
do {
interpreter = try Interpreter(modelPath: path)
// Allocate memory for the model's input `Tensor`s.
try interpreter?.allocateTensors()
let inputData = preProcess()
// Copy the input data to the input `Tensor`.
try self.interpreter?.copy(inputData, toInputAt: 0)
// Run inference by invoking the `Interpreter`.
try self.interpreter?.invoke()
// Get the output `Tensor`
let confidenceOutputTensor = try self.interpreter?.output(at: 0)
let idOutputTensor = try self.interpreter?.output(at: 1)
// Copy output to `Data` to process the inference results.
let confidenceOutputSize = confidenceOutputTensor?.shape.dimensions.reduce(1, {x, y in x * y})
let idOutputSize = idOutputTensor?.shape.dimensions.reduce(1, {x, y in x * y})
let confidenceResults =
UnsafeMutableBufferPointer<Float32>.allocate(capacity: confidenceOutputSize!)
let idResults =
UnsafeMutableBufferPointer<Int32>.allocate(capacity: idOutputSize!)
_ = confidenceOutputTensor?.data.copyBytes(to: confidenceResults)
_ = idOutputTensor?.data.copyBytes(to: idResults)
postProcess(idResults, confidenceResults)
print("Successfully ran inference")
DispatchQueue.main.async {
self.tableView.reloadData()
}
} catch {
print("Error occurred creating model interpreter: \(error)")
}
}
後処理を実装する
最後に、このステップでは、モデルの出力を後処理し、信頼度が最も高い結果を選択して、含まれている値(ユーザーがすでに高評価した映画)を削除します。次のコードをアプリにコピーします。
RecommendationsViewController.swift
// Postprocess to get results from tflite inference.
func postProcess(_ idResults: UnsafeMutableBufferPointer<Int32>, _ confidenceResults: UnsafeMutableBufferPointer<Float32>) {
for i in 0..<10 {
let id = idResults[i]
let movieIdx = getMovies().firstIndex { $0.id == id }
let title = getMovies()[movieIdx!].title
recommendations.append(Recommendation(title: title, confidence: confidenceResults[i]))
}
}
アプリをテストする
アプリを再実行します。映画をいくつか選択すると、新しいモデルが自動的にダウンロードされ、おすすめの生成が開始されます。
11. 完了
TensorFlow Lite と Firebase を使用して、アプリにレコメンデーション機能を組み込んだ。この Codelab で説明する手法とパイプラインは、一般化して他のタイプのレコメンデーションの提供にも使用できます。
学習した内容
- Firebase ML
- Firebase アナリティクス
- 分析イベントを BigQuery にエクスポートする
- 分析イベントを前処理する
- レコメンデーション TensorFlow モデルをトレーニングする
- モデルをエクスポートして Firebase コンソールにデプロイする
- アプリで映画のおすすめを表示する
次のステップ
- アプリに Firebase ML のレコメンデーションを実装します。
詳細
質問がある場合
問題を報告する