
ไม่ว่าคุณจะกำลังพัฒนาแอปที่เพิ่งเริ่มต้นหรือให้บริการที่มีการเข้าชมสูงอยู่แล้ว คุณจะได้รับประโยชน์จากข้อมูลเชิงลึกและคำแนะนำในคู่มือนี้เกี่ยวกับวิธีปรับขนาด ได้อย่างราบรื่นด้วย FCM แนวคิดและแนวทางปฏิบัติเหล่านี้จะช่วยให้คุณหลีกเลี่ยงผลกระทบด้านลบได้เมื่อต้องส่งข้อความจำนวนมาก
คำและแนวคิดสำคัญ
คำขอข้อความ: คำขอข้อความ FCM ใช้สลับกับ "คำขอ" "ข้อความ" หรือ "คำค้นหา"
คำขอต่อวินาที (RPS): เมตริกที่อธิบายอัตราของคำขอขาเข้า ไปยัง FCM ซึ่งใช้สลับกับคำค้นหาต่อวินาที (QPS)
โทเค็นโควต้า, บัคเก็ตโทเค็น และการเติม: เมื่อส่งข้อความเทียบกับ FCM HTTP v1 API คำขอแต่ละรายการจะใช้โทเค็นโควต้าที่จัดสรรไว้ในช่วงเวลาที่กำหนด ช่วงเวลานี้เรียกว่า "บัคเก็ตโทเค็น" ซึ่งจะเติมจนเต็มเมื่อสิ้นสุดช่วงเวลา ตัวอย่างเช่น HTTP v1 API จัดสรรโทเค็นโควต้า 600,000 รายการสำหรับบัคเก็ตโทเค็น 1 นาทีแต่ละรายการ ซึ่งจะเติมจนเต็มเมื่อสิ้นสุดช่วงเวลา 1 นาทีแต่ละช่วง
การจำกัดอัตราฝั่งเซิร์ฟเวอร์: เมื่อปริมาณการเข้าชมเกินความจุของบริการ FCM ระบบจะปฏิเสธคำขอที่เกินความจุในการให้บริการเพื่อจำกัดอัตราการไหลเข้า ระบบอาจแสดงการตอบกลับข้อผิดพลาด 429 พร้อมส่วนหัว retry-after เพื่อระบุว่าคุณควรรอระยะเวลาที่กำหนดก่อนที่จะลองส่งคำขออีกครั้ง
การควบคุมอัตราฝั่งไคลเอ็นต์: เมื่อไคลเอ็นต์พบคำขอที่ไม่สำเร็จ เวลาในการตอบสนองสูง
หรือข้อผิดพลาด 429 ไคลเอ็นต์ควรจำกัดอัตราการไหลออกโดยสมัครใจเพื่อหลีกเลี่ยงการเพิ่มความ
แออัด
Exponential Backoff: เมื่อลองส่งข้อผิดพลาดอีกครั้ง ให้เพิ่มความล่าช้าของเวลาแบบทวีคูณ เช่น 1 วินาที 2 วินาที 4 วินาที 8 วินาที 16 วินาที 32 วินาที และอื่นๆ
การสุ่มเวลา: หลีกเลี่ยงการลองส่งคำขออีกครั้งในช่วงเวลาที่แน่นอน การสุ่มเวลาหน่วง จะทำให้คุณเปลี่ยนเวลาหน่วงในการลองใหม่ผ่านกระบวนการสุ่มเพื่อกระจายเวลาหน่วงอย่างสม่ำเสมอ เมื่อเวลาผ่านไป (เช่น 0.9 วินาที, 2.3 วินาที, 4.1 วินาที, 8.5 วินาที, 17.9 วินาที, 34.7 วินาที)
การขยายการลองใหม่: เมื่อมีการลองส่งคำขอที่ล้มเหลวอีกครั้งโดยไม่มี Exponential Backoff/Jittering คำขอเหล่านั้นมักจะสะสมและเพิ่มภาระการเข้าชมที่กำลังดำเนินการอยู่ ซึ่งอาจเป็นการ "ขยาย" และทำให้ปัญหาการจราจรติดขัดรุนแรงขึ้น
ปัญหา: การเข้าชมเพิ่มขึ้นอย่างฉับพลัน
FCM ประมวลผลคำขอหลายล้านรายการต่อวินาที (RPS) สาเหตุหลักที่ทำให้เกิด ความหนาแน่นของระบบ ปัญหาเวลาในการตอบสนอง และการหยุดทำงานคือการเข้าชมที่เพิ่มขึ้น
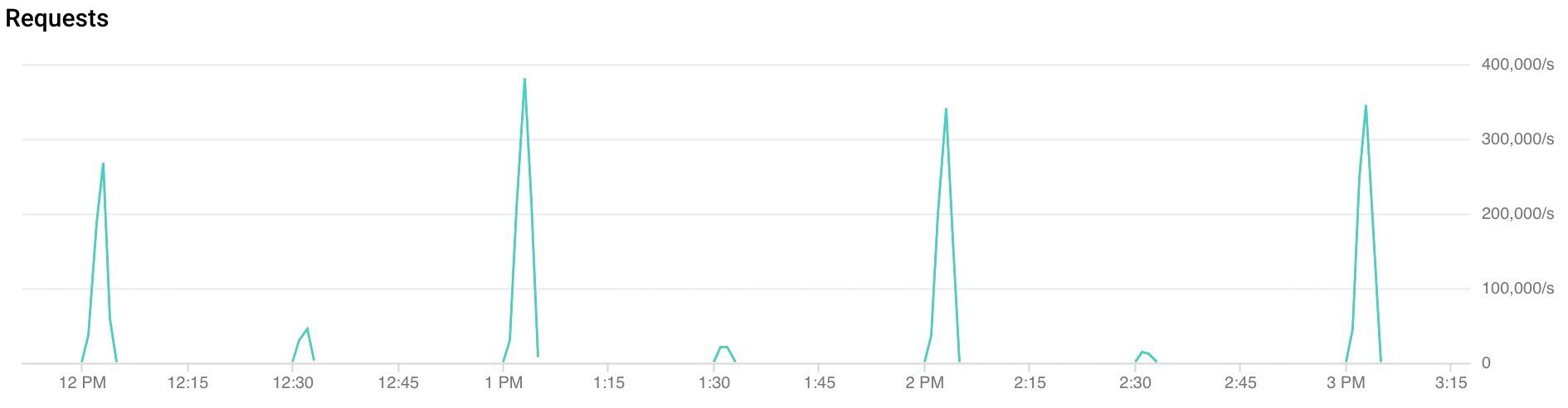
การเข้าชมที่เพิ่มขึ้นอย่างรวดเร็วคืออะไร
การเข้าชมที่เพิ่มขึ้นมีหลายประเภท
การเพิ่มขึ้นทุกชั่วโมง: FCM ได้รับการเข้าชมมากกว่า 2 เท่าในช่วง 30 วินาทีแรกถึง 2 นาทีของแต่ละชั่วโมง นอกจากนี้ยังพบการเพิ่มขึ้นที่คล้ายกันแต่มีปริมาณน้อยกว่าที่ช่วงครึ่งชั่วโมงและช่วง 15 นาที (ตัวอย่างเช่น 00:15, 00:30, 00:45)
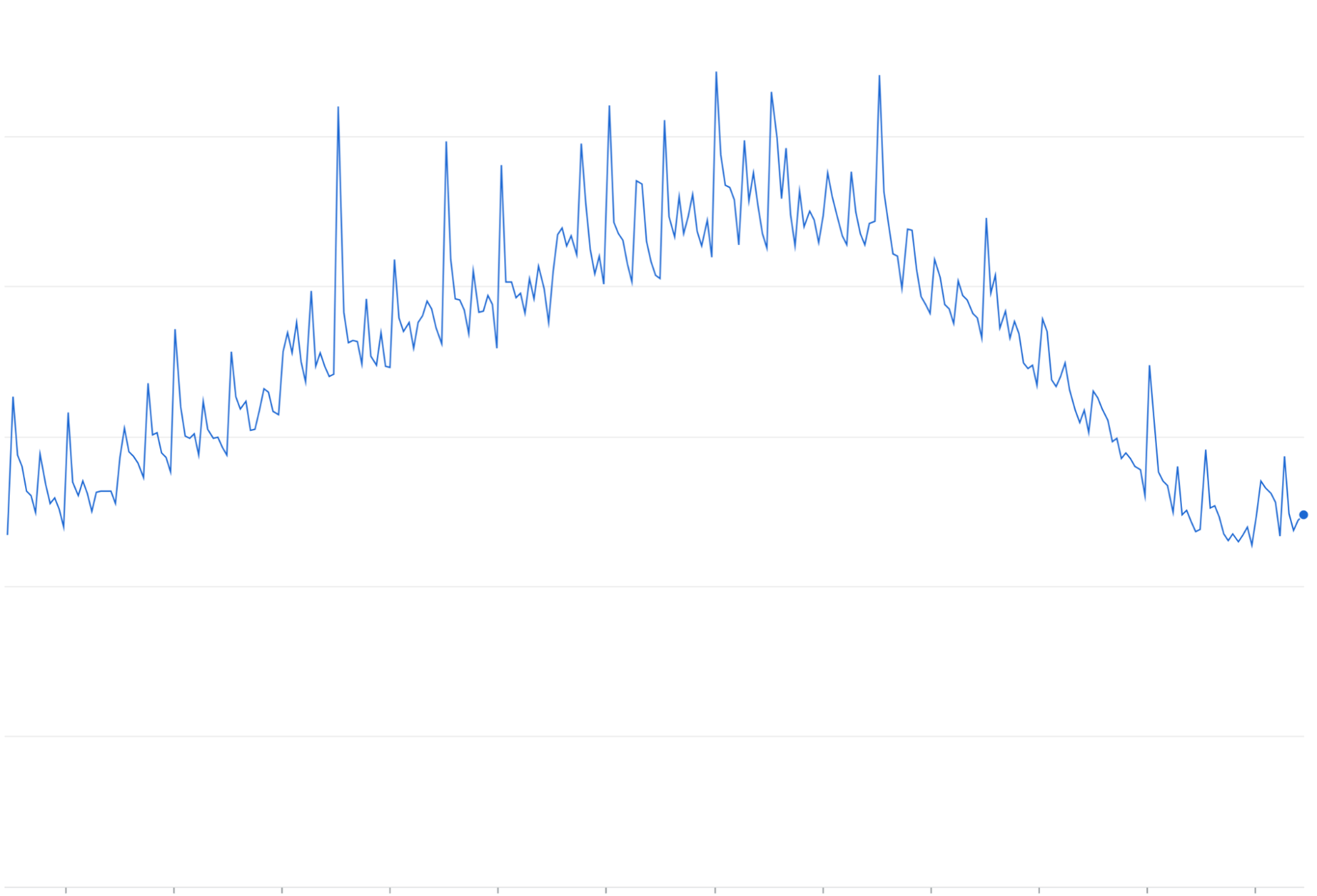
การขยายการลองใหม่: การลองส่งคำขอที่ไม่สำเร็จหรือหมดเวลาอีกครั้งโดยไม่มีExponential Backoffอาจทำให้เกิดการรับส่งข้อมูลซ้ำๆ เป็นระลอกๆ นอกเหนือจากการรับส่งข้อมูลที่เพิ่มขึ้นอยู่แล้ว
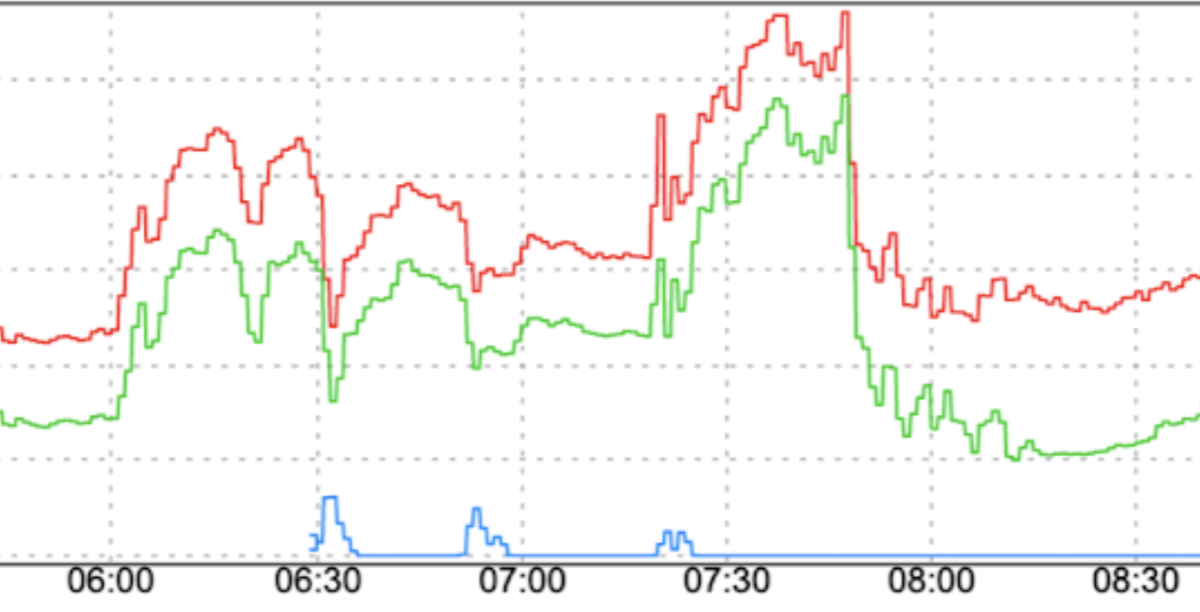
การเปลี่ยนแปลงรูปแบบการเข้าชมอย่างฉับพลัน: การนำการเข้าชมใหม่ไปยัง FCM หรือการย้ายการเข้าชมไปยัง FCM ในภูมิภาคต่างๆ โดยไม่มีปัจจัยที่ทำให้ราบรื่น เช่น การเพิ่มขึ้นแบบค่อยเป็นค่อยไป อาจทำให้เกิดการเพิ่มขึ้นอย่างรวดเร็ว
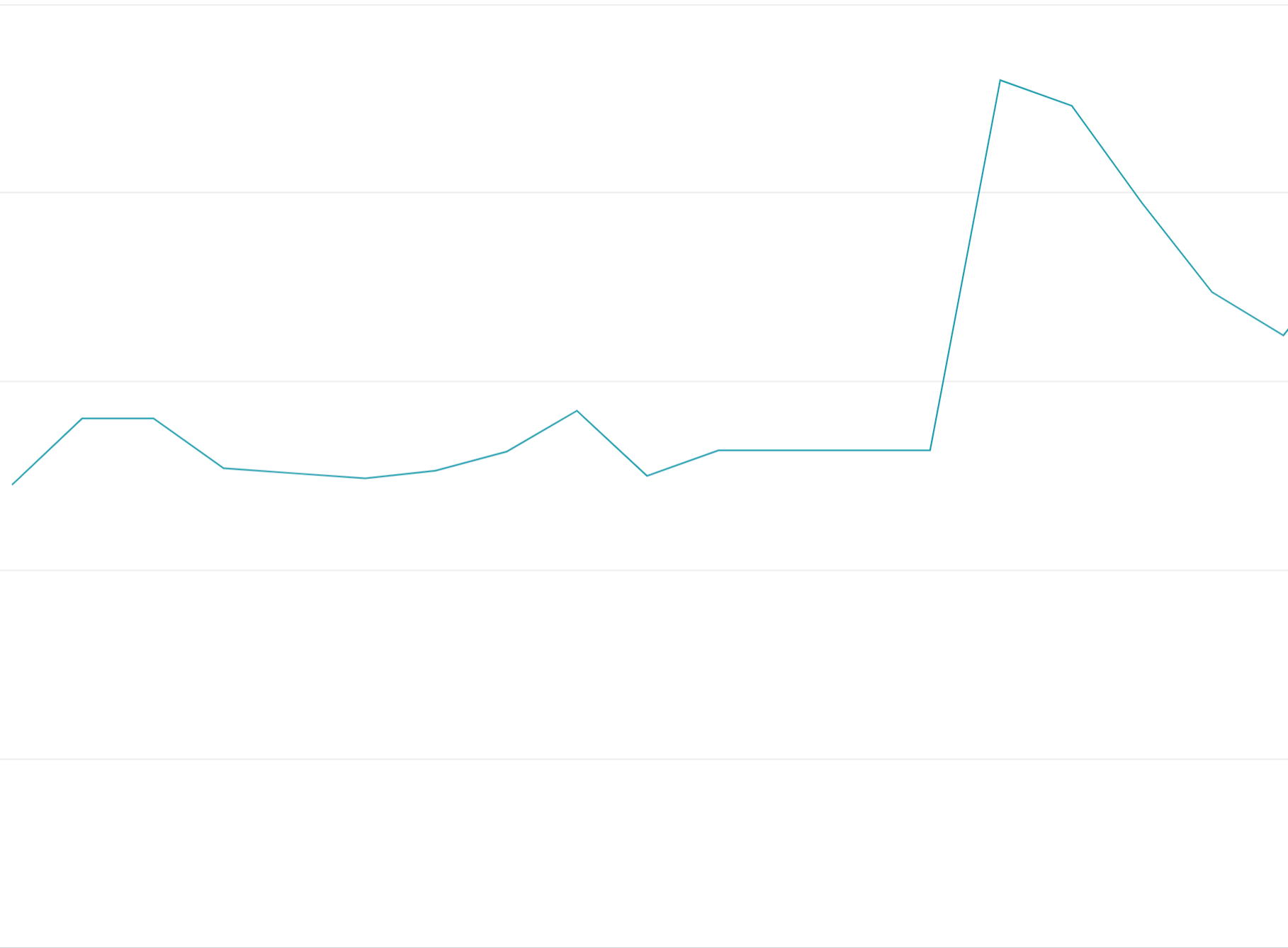
การใช้โทเค็นโควต้าล่วงหน้า: การใช้โทเค็นโควต้าทั้งหมดในช่วงเริ่มต้นของกรอบเวลาโควต้าแทนที่จะกระจายคำขออย่างสม่ำเสมอในกรอบเวลาโควต้าจะทำให้เกิดการแกว่งขึ้นๆ ลงๆ ซึ่งยากและมีค่าใช้จ่ายสูงในการปรับสมดุลโหลด
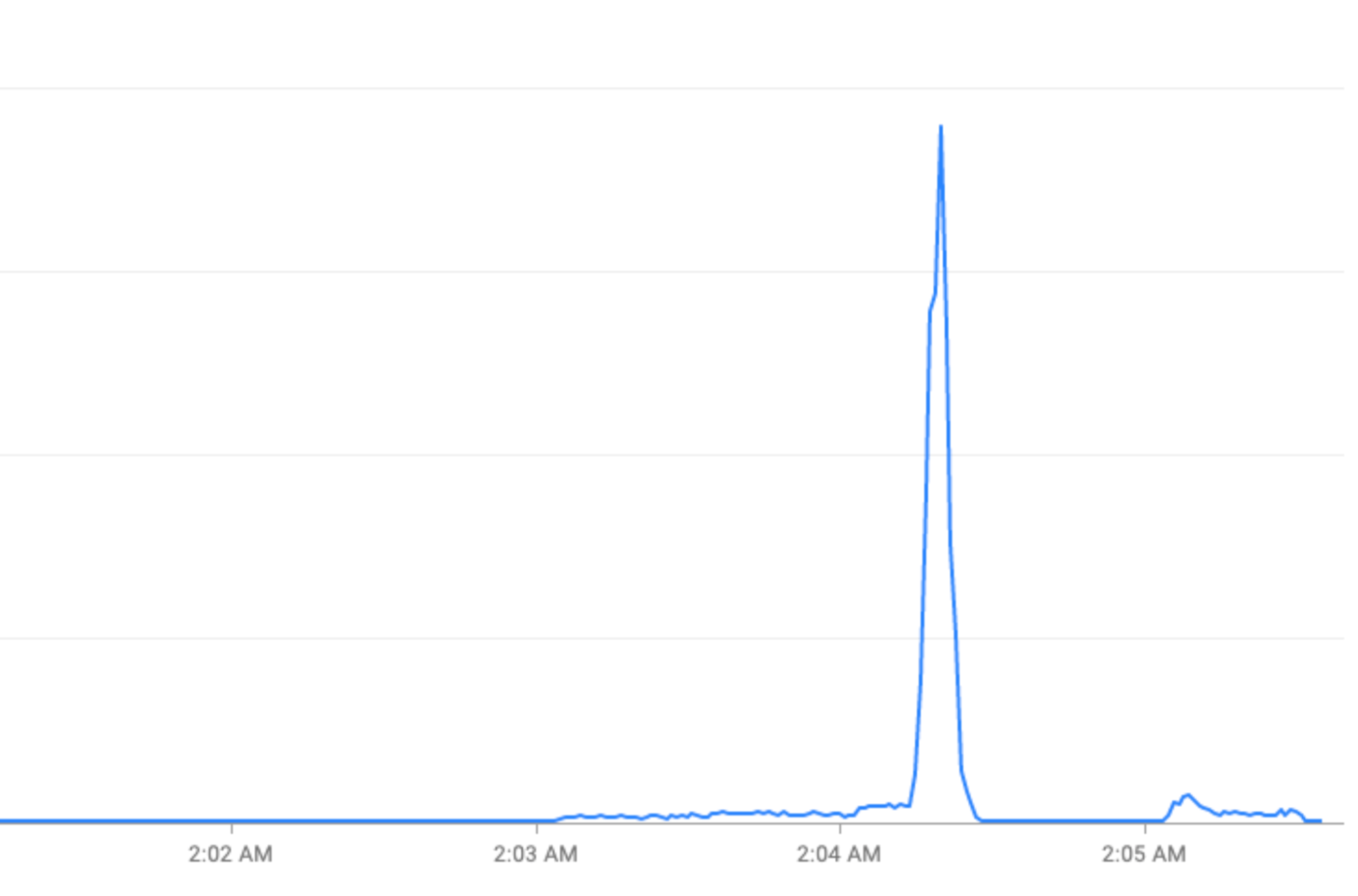
กิจกรรมพิเศษ: การเข้าชมที่เพิ่มขึ้นในช่วงวันหยุด (วันส่งท้ายปีเก่า) หรือการแข่งขันกีฬา (ฟุตบอลโลก FIFA)
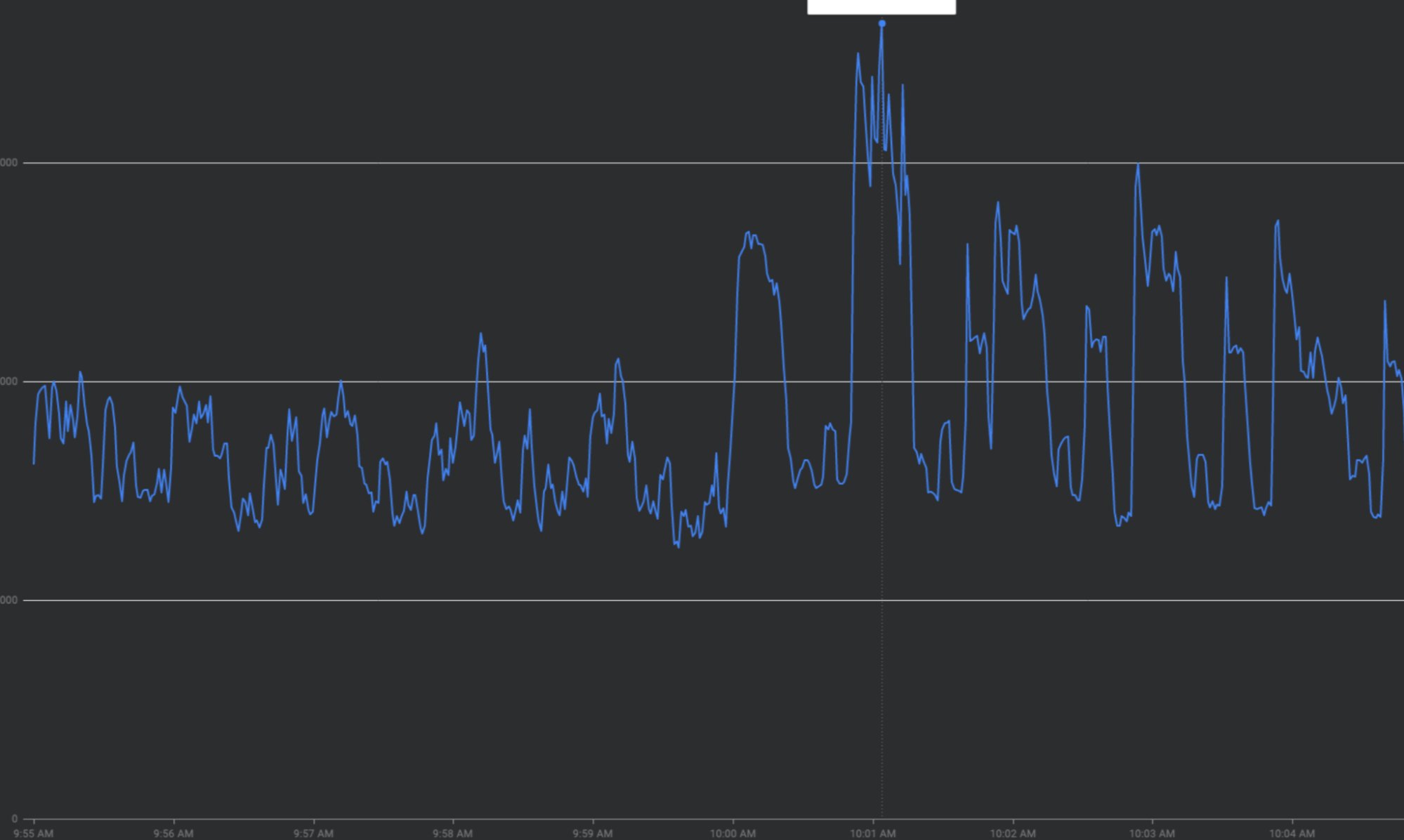
แก้ไขปัญหาการรับส่งข้อมูลที่เพิ่มขึ้นอย่างรวดเร็วด้วยการ "ลดความชันของกราฟ"
ส่วนนี้อธิบายกลยุทธ์ในการลดการเข้าชมที่เพิ่มขึ้นอย่างรวดเร็วเมื่อเป็นไปได้ ซึ่งเป็นกลยุทธ์ในการ "ลดความชันของกราฟ"
ใช้ FCM เฉพาะในกรณีการใช้งานที่เหมาะสม
ในบางกรณีการใช้ FCM เพื่อส่งการแจ้งเตือนอาจไม่จำเป็นหรือไม่เหมาะสม
เช่น สำหรับการแจ้งเตือนกิจกรรมในปฏิทิน คุณสามารถตั้งเวลางานในเครื่องใน แอปเพื่อแสดงการแจ้งเตือนในเวลาที่เหมาะสมแทนที่จะส่ง จากเซิร์ฟเวอร์ของแอป จำกัดข้อความ FCM ให้ซิงค์กับปฏิทิน
หลีกเลี่ยงการเพิ่มขึ้นอย่างรวดเร็ว
รูปแบบการปรับขนาดที่ไม่ควรทำอย่างหนึ่งคือการส่งการแจ้งเตือน FCM โดยเร็วที่สุดเท่าที่ระบบจะอนุญาต แทนที่จะใช้การควบคุมอัตราที่ฝั่งเซิร์ฟเวอร์ โปรดพิจารณาสิ่งต่อไปนี้
- ลูกค้าทั้งหมดของคุณจำเป็นต้องได้รับการแจ้งเตือนเดียวกันภายในช่วงเวลา 1 นาทีหรือไม่ ช่วงเวลาการนำส่ง 5 นาทีจะยังคงตอบสนองความต้องการทางธุรกิจของคุณได้ไหม
- คุณแบ่งกลุ่มลูกค้าตามลำดับความสำคัญเพื่อลดการเพิ่มขึ้นอย่างรวดเร็วได้ไหม
- คุณตั้งเวลาการแจ้งเตือนล่วงหน้าได้ไหม
หากเป็นไปได้ ให้หลีกเลี่ยงกลยุทธ์ที่ทำให้โควต้าการส่ง FCM หมดลงทันที แล้วกลับมาทำซ้ำรูปแบบเดิมทันทีที่ Bucket โทเค็น เติมเต็ม รูปแบบการเข้าถึงนี้ ทำให้เกิดปัญหาการปรับสมดุลโหลดสำหรับ FCM และระบบที่ขึ้นอยู่กับ FCM ค่อยๆ เพิ่มการเข้าชมทีละน้อย อย่างน้อยที่สุด ให้เพิ่มจาก 0 เป็น RPS สูงสุดภายในกรอบเวลา 60 วินาที แนะนำให้ใช้กรอบเวลาที่นานขึ้นเพื่อให้ได้ RPS ที่สูงขึ้น
หลีกเลี่ยงการจราจร "ทุกชั่วโมง"
หากเป็นไปได้ ให้หลีกเลี่ยงการส่งข้อความภายในช่วง 2 นาทีของเครื่องหมาย :00, :15, :30 และ :45 นาที
ใช้การควบคุมอัตราฝั่งเซิร์ฟเวอร์
ใช้การควบคุมอัตราฝั่งเซิร์ฟเวอร์เพื่อตรวจสอบและจัดการการเข้าชมที่ไปยัง FCM
การจัดการการลองใหม่
แม้ว่า FCM จะพยายามให้บริการอย่างต่อเนื่อง แต่บางครั้งคำขออาจหมดเวลา หรือล้มเหลวได้ แม้ว่าเหตุผลจะแตกต่างกันไป แต่แนวทางปฏิบัติแนะนำต่อไปนี้จะเพิ่มประสิทธิภาพการลองใหม่ เพื่อให้ส่งข้อความได้โดยเร็วที่สุดพร้อมทั้งลดผลกระทบต่อ การจราจรที่หนาแน่น
หมดเวลา
ตั้งค่าการหมดเวลาอย่างน้อย 10 วินาทีในคำขอส่งก่อนที่จะลองอีกครั้ง การเรียกกระบวนการระยะไกลภายในของ FCM ส่วนใหญ่ใช้การหมดเวลา 10 วินาที
ข้อผิดพลาด
- สำหรับข้อผิดพลาด 400, 401, 403, 404 ให้ยกเลิกและไม่ต้องลองอีก
- สำหรับข้อผิดพลาด 429 ให้ลองอีกครั้งหลังจากรอระยะเวลาที่ตั้งไว้ในส่วนหัว retry-after หากไม่ได้ตั้งค่าส่วนหัว retry-after ไว้ ให้ใช้ค่าเริ่มต้นเป็น 60 วินาที
- สำหรับข้อผิดพลาด 500 ให้ลองอีกครั้งโดยใช้ Exponential Backoff
Exponential Backoff
หากต้องการหลีกเลี่ยงการขยายการลองใหม่ ให้ใช้ Exponential Backoff พร้อม Jittering สำหรับการลองส่งคำขออีกครั้ง ตัวอย่างเช่น Firebase Admin SDK ใช้ Exponential Backoff
การตั้งค่าที่แนะนำเพิ่มเติมมีดังนี้
- ช่วงเวลาขั้นต่ำ: อย่าลองส่งคำขอที่ล้มเหลวด้วย FCM อีกครั้งทันที โปรดรออย่างน้อย 10 วินาทีก่อนลองส่งคำขอที่ล้มเหลวอีกครั้ง
- ช่วงเวลาสูงสุด: กำหนดช่วงเวลาสูงสุดสำหรับการทิ้งคำขอที่ล้าสมัยแล้วแทนที่จะลองใหม่ไปเรื่อยๆ
หากมีการลองส่งคำขอซ้ำอย่างต่อเนื่องโดยใช้ Exponential Backoff และยังคง ล้มเหลวหลังจากผ่านไป 60 นาที แสดงว่าอาจมีการจัดหมวดหมู่ข้อผิดพลาดเป็นข้อผิดพลาดที่ลองใหม่ได้ไม่ถูกต้อง หรือ FCM ประสบปัญหาหยุดทำงาน ซึ่งการลองใหม่โดยไม่ตั้งใจอาจทำให้สถานการณ์ แย่ลง
สร้างแผนการเปิดตัวและการย้อนกลับ รวมถึงทำการเปลี่ยนแปลงทีละน้อย
เมื่อทำการเปลี่ยนแปลงการรับส่งข้อมูลในวงกว้าง เช่น การเพิ่มการรับส่งข้อมูลไปยัง FCM หรือ การเปลี่ยนการรับส่งข้อมูลในภูมิภาคหรือเครือข่ายต่างๆ การออกแบบแผนการเปิดตัว/ย้อนกลับ และการใช้การเปลี่ยนแปลงแบบค่อยเป็นค่อยไปจะช่วยปกป้องผู้ใช้ บริการ และ FCM ของคุณ
- แผนการเปิดตัวช่วยให้ผู้มีส่วนเกี่ยวข้องมีความคาดหวังที่สอดคล้องกัน ในบางสถานการณ์ (อธิบายไว้ด้านล่าง) คุณอาจต้องแชร์แผนการเปิดตัวกับทีม FCM ล่วงหน้าเพื่อหลีกเลี่ยงเรื่องไม่คาดฝัน
- แผนการย้อนกลับช่วยให้คุณคำนึงถึงเหตุการณ์ที่ไม่คาดคิดและเตรียมกลไกเพื่อกู้คืนจากความล้มเหลวที่ไม่คาดคิดได้อย่างรวดเร็วและปลอดภัย
- การเปลี่ยนแปลงแบบค่อยเป็นค่อยไปมี 2 ด้าน ดังนี้
- การเพิ่มขึ้นแบบ "ทีละขั้น": ขั้นตอนควรเป็น 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% หรือละเอียดกว่านั้น "Soak" (สังเกตลักษณะการทำงานของระบบภายใต้ภาระงาน) แต่ละขั้นตอนเป็นเวลา 1 วันถึง 1 สัปดาห์ ซึ่งจะช่วยให้คุณเห็นปัญหาที่อาจเกิดขึ้นก่อนที่จะ "ก้าวไป" อีกขั้น
- การเพิ่มการเข้าชมแบบค่อยเป็นค่อยไป: เมื่อทำตาม "ขั้นตอน" แต่ละขั้นตอนเพื่อเพิ่มการเข้าชม ให้กระจายการเข้าชมในช่วงเวลาอย่างน้อย 1 ชั่วโมง ซึ่งจะช่วยให้โครงสร้างพื้นฐานการปรับสมดุลโหลดของ FCM ปรับขนาดการรับส่งข้อมูลใหม่ได้อย่างเหมาะสม พร้อมทั้งลดโอกาสที่จะเกิดฮอตสปอตและความแออัด
ต่อไปนี้เป็นสถานการณ์สมมติสำหรับการย้ายข้อมูล 500,000 RPS ทั่วโลกจาก FCM Legacy HTTP API ไปยัง FCM HTTP v1 API
| สัปดาห์ | Step | กลยุทธ์การเพิ่มประสิทธิภาพแบบค่อยเป็นค่อยไป |
|---|---|---|
| 0 | การเพิ่มจำนวน 1% | เพิ่มจาก 0 เป็น 5,000 RPS สำหรับ FCM HTTP v1 อย่างราบรื่นภายใน 1 ชั่วโมง |
| 1 | การเพิ่มจำนวน 5% | ค่อยๆ เพิ่มจาก 5,000 เป็น 25,000 RPS ในช่วง 2 ชั่วโมง |
| 2 | การเพิ่มจำนวน 10% | ค่อยๆ เพิ่มจาก 25,000 เป็น 50,000 RPS ในช่วง 2 ชั่วโมง |
| 3 | การเพิ่มจำนวน 25% | เพิ่มจาก 50,000 เป็น 125,000 RPS ในช่วง 3 ชั่วโมง |
| 4 | การเพิ่มจำนวน 50% | เพิ่มจาก 125,000 เป็น 250,000 RPS ในช่วง 6 ชั่วโมง |
| 5 | การเพิ่มขึ้น 75% | เพิ่มจาก 250,000 เป็น 375,000 RPS ในช่วง 6 ชั่วโมง |
| 6 | การเพิ่มประสิทธิภาพ 100% | เพิ่มจาก 375,000 เป็น 500,000 RPS ในช่วง 6 ชั่วโมง |
แผนการย้อนกลับที่อาจเกิดขึ้น
- หากเวลาในการตอบสนองเปอร์เซ็นไทล์ที่ 95 เพิ่มขึ้นเป็นมากกว่า 500 มิลลิวินาที หรือหากอัตราข้อผิดพลาดเกิน 1% เป็นเวลานานกว่า 1 ชั่วโมงในขั้นตอนใดก็ตาม ให้ใช้การกำหนดค่าแบบไดนามิกเพื่อย้อนกลับไปยังขั้นตอนก่อนหน้าทันที
- ย้อนกลับไปยังขั้นตอนก่อนหน้าต่อไปจนกว่าเวลาในการตอบสนองและอัตราข้อผิดพลาดจะกลับสู่ระดับปกติ
เมื่อใดที่ควรติดต่อ FCM
โปรดติดต่อ FCM ผ่านทีมสนับสนุน Firebase หากมีกรณีต่อไปนี้
- โควต้าเริ่มต้นไม่ตรงตามกรณีการใช้งานของคุณอีกต่อไป
- คุณกำลังเปลี่ยนรูปแบบการส่งภายในกรอบเวลา 3 เดือนที่ ระดับ 100,000 RPS ทั่วโลกหรือ 30,000 RPS ในทวีป