
Que vous développiez une application naissante ou que vous exécutiez déjà un service à fort trafic, vous pouvez tirer parti des informations et des recommandations de ce guide pour évoluer en douceur avec FCM. Ces concepts et pratiques peuvent vous aider à éviter les impacts négatifs lorsque vous devez envoyer de gros volumes de messages.
Termes et concepts clés
Demande de message : demande de message FCM. Ce terme est utilisé de manière interchangeable avec "demande", "message" ou "requête".
Requêtes par seconde (RPS) : métrique décrivant le taux de requêtes entrantes vers FCM. Elle est utilisée de manière interchangeable avec les requêtes par seconde (QPS).
Jetons de quota, buckets de jetons et recharges : lorsque vous envoyez des messages à l'aide de l'API FCM HTTP v1, chaque requête consomme un jeton de quota alloué dans un intervalle de temps donné. Cette fenêtre, appelée Token Bucket, se remplit complètement à la fin de la période. Par exemple, l'API HTTP v1 alloue 600 000 jetons de quota pour chaque bucket de jetons d'une minute, qui se remplit complètement à la fin de chaque période d'une minute.
Limitation du débit côté serveur : lorsque le volume de trafic dépasse la capacité du service FCM, les requêtes au-delà de la capacité de diffusion sont refusées pour limiter le débit du flux entrant. Des réponses d'erreur 429 avec des en-têtes retry-after peuvent être renvoyées pour indiquer que vous devez attendre une certaine période avant de réessayer d'envoyer la requête.
Limitation du débit côté client : lorsque les clients constatent des échecs de requêtes, une latence élevée ou des erreurs 429, ils doivent volontairement limiter le débit de sortie pour éviter d'aggraver la congestion.
Intervalle exponentiel entre les tentatives : lorsque vous réessayez après une erreur, ajoutez des délais de plus en plus longs. Par exemple : 1 s, 2 s, 4 s, 8 s, 16 s, 32 s, etc.
Jittering : évitez de relancer les requêtes à intervalles exacts. Avec le jittering, vous variez les délais de nouvelle tentative par le biais d'un processus aléatoire pour les répartir uniformément dans le temps (par exemple : 0,9 s, 2,3 s, 4,1 s, 8,5 s, 17,9 s, 34,7 s).
Amplification des tentatives : lorsque les requêtes ayant échoué sont relancées sans intervalle exponentiel entre les tentatives ni gigue, elles s'accumulent souvent et s'ajoutent à la charge de trafic en cours, ce qui peut "amplifier" et exacerber les problèmes de congestion du trafic.
Le problème : les pics de trafic
FCM traite des millions de requêtes par seconde. Les pics de trafic sont la principale cause de congestion systémique, de problèmes de latence et d'indisponibilité.
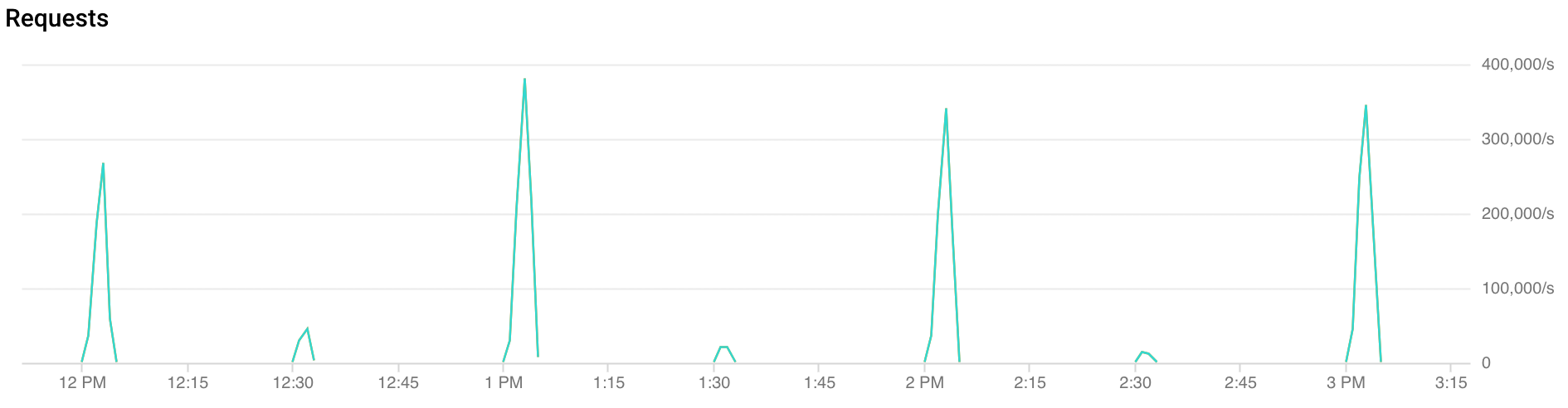
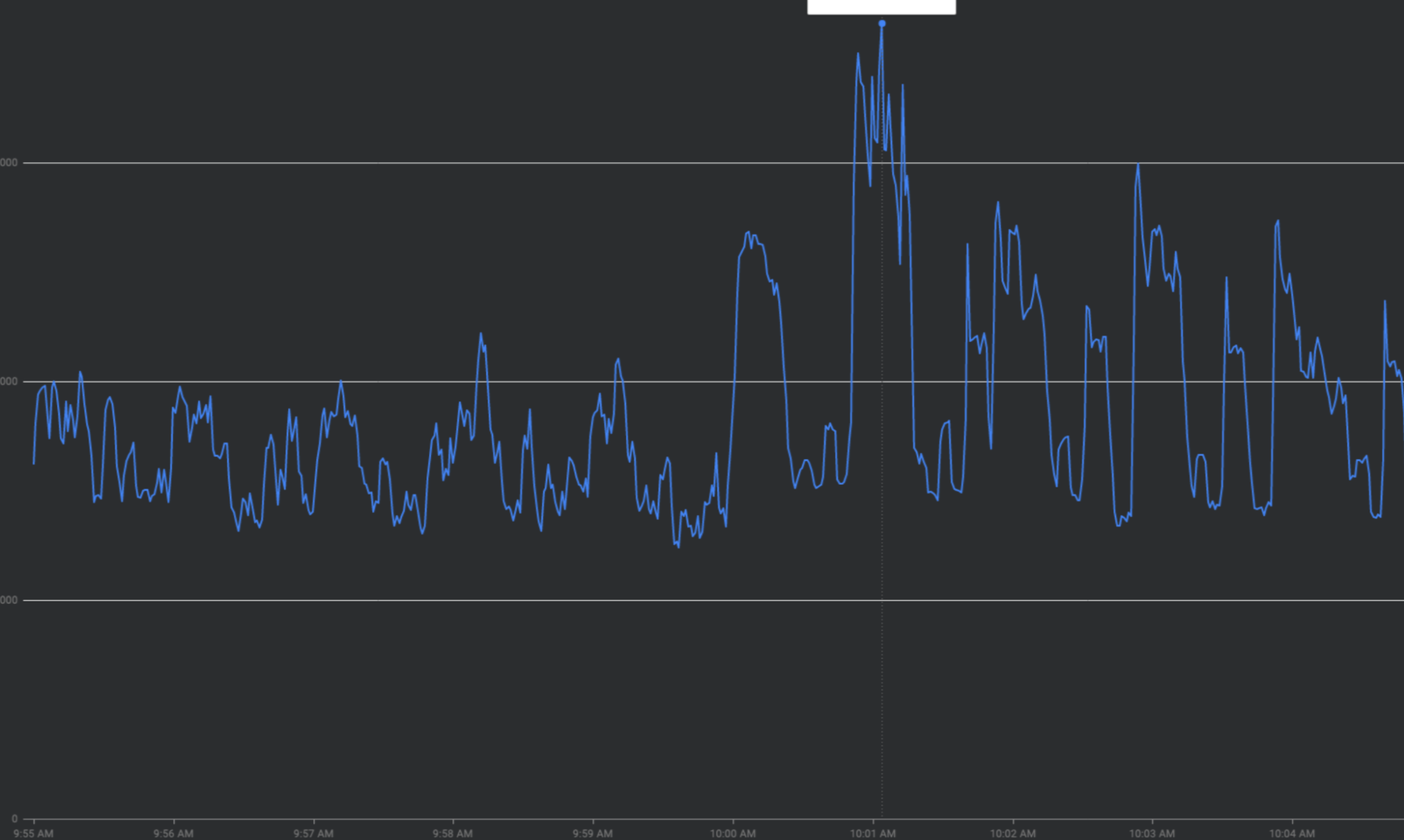
Qu'est-ce que le trafic irrégulier ?
Il existe plusieurs types de pics de trafic.
Pics à chaque heure : FCM reçoit plus du double du trafic pendant les 30 premières secondes à 2 minutes de chaque heure. Des pics similaires, mais moins importants, sont également observés à chaque quart d'heure et demi-heure (par exemple, 00:15, 00:30, 00:45).
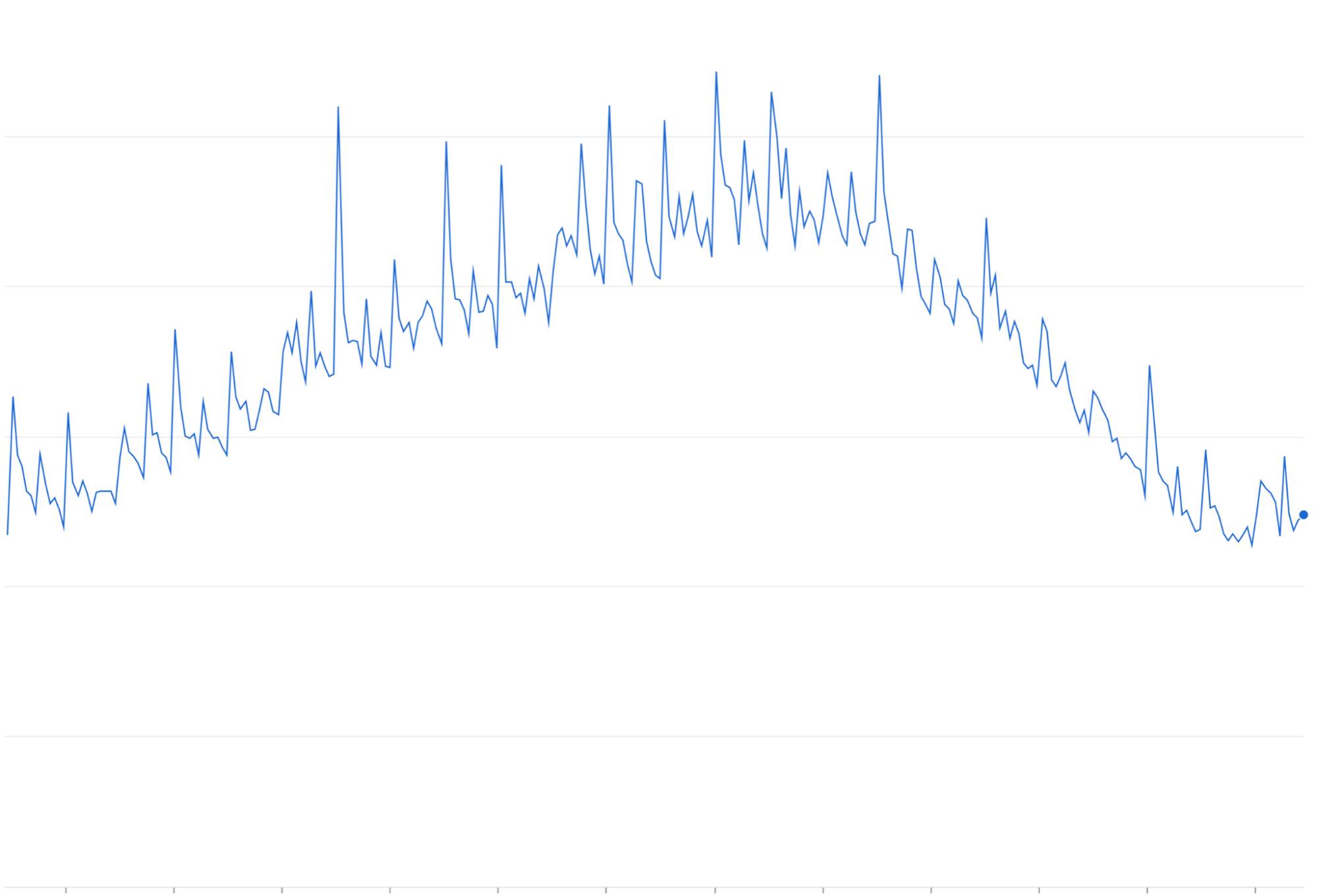
Amplification des nouvelles tentatives : le fait de réessayer les requêtes ayant échoué ou ayant expiré sans intervalle exponentiel entre les tentatives peut entraîner des vagues de trafic répétées en plus des pics de trafic existants.
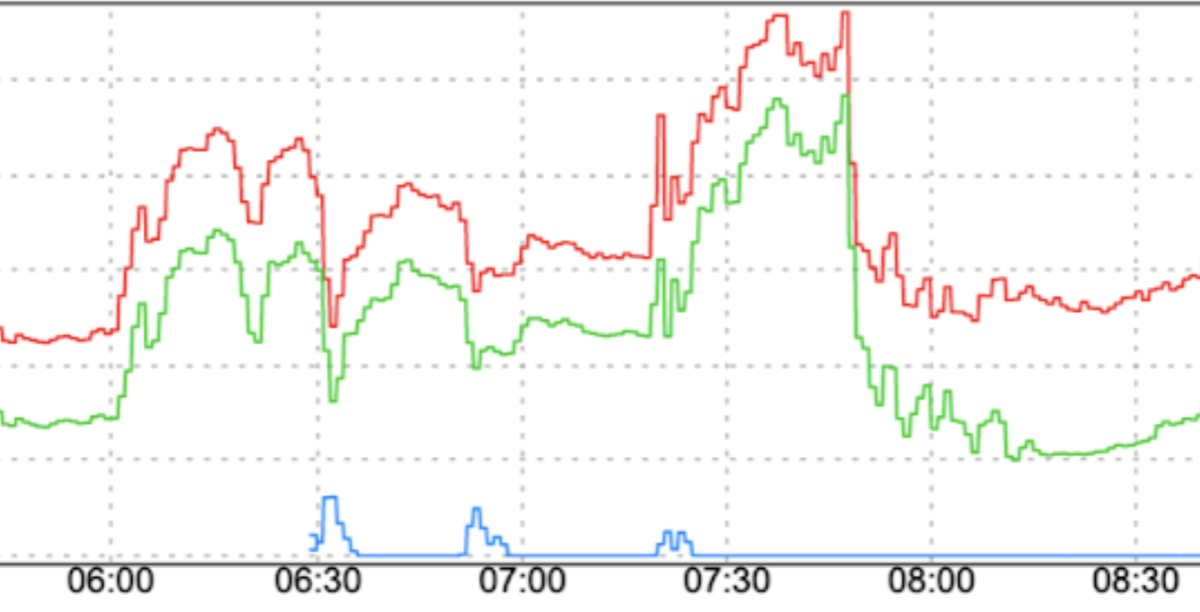
Changements brusques dans les schémas de trafic : rediriger du nouveau trafic vers FCM ou déplacer du trafic vers FCM dans différentes régions sans facteurs de lissage tels qu'une augmentation progressive peut entraîner des pics.
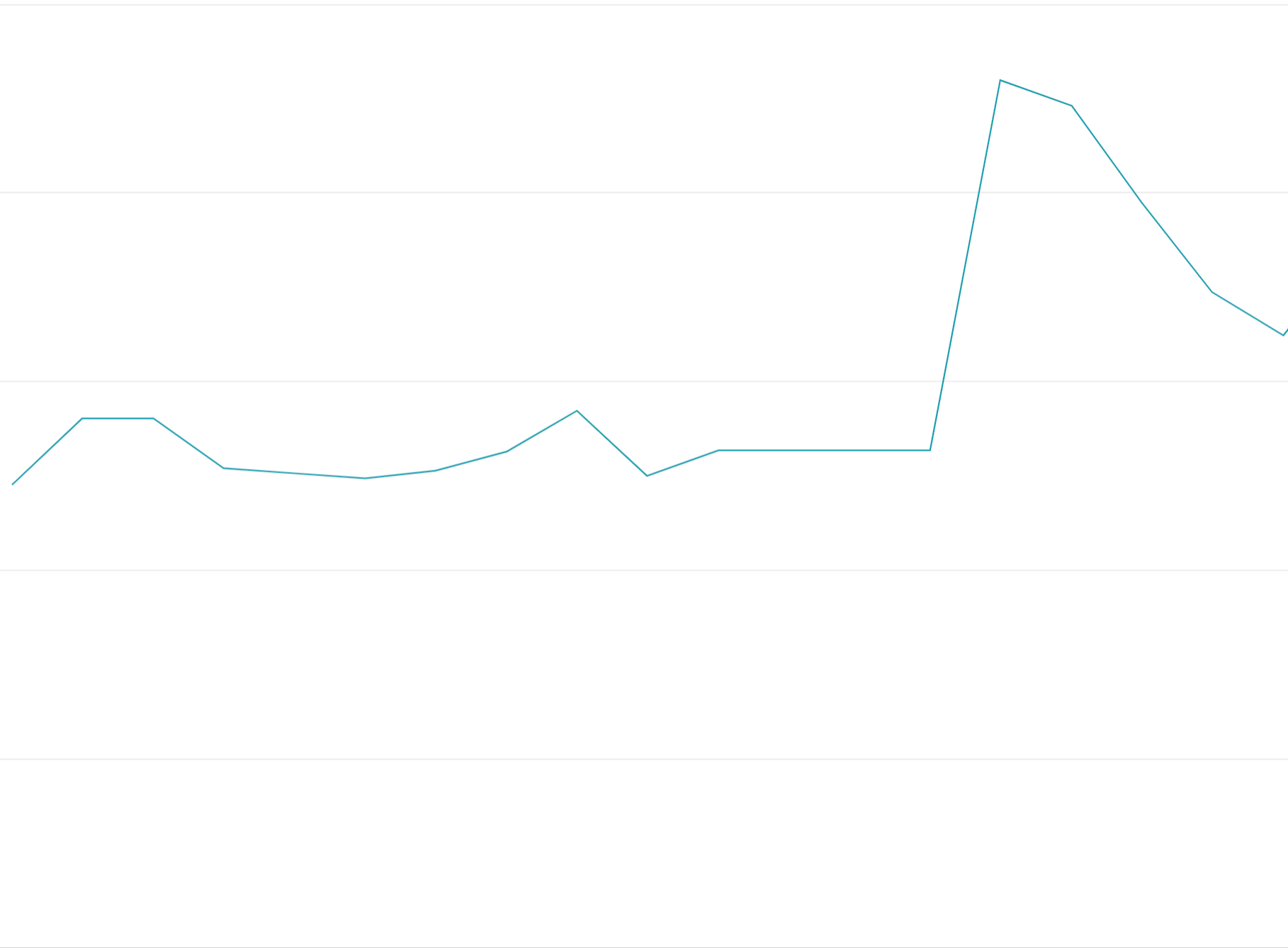
Utilisation des jetons de quota en début de période : si vous épuisez tous les jetons de quota au début des périodes de quota au lieu de répartir les requêtes de manière uniforme sur les périodes de quota, vous créerez des oscillations marche/arrêt difficiles et coûteuses à équilibrer.
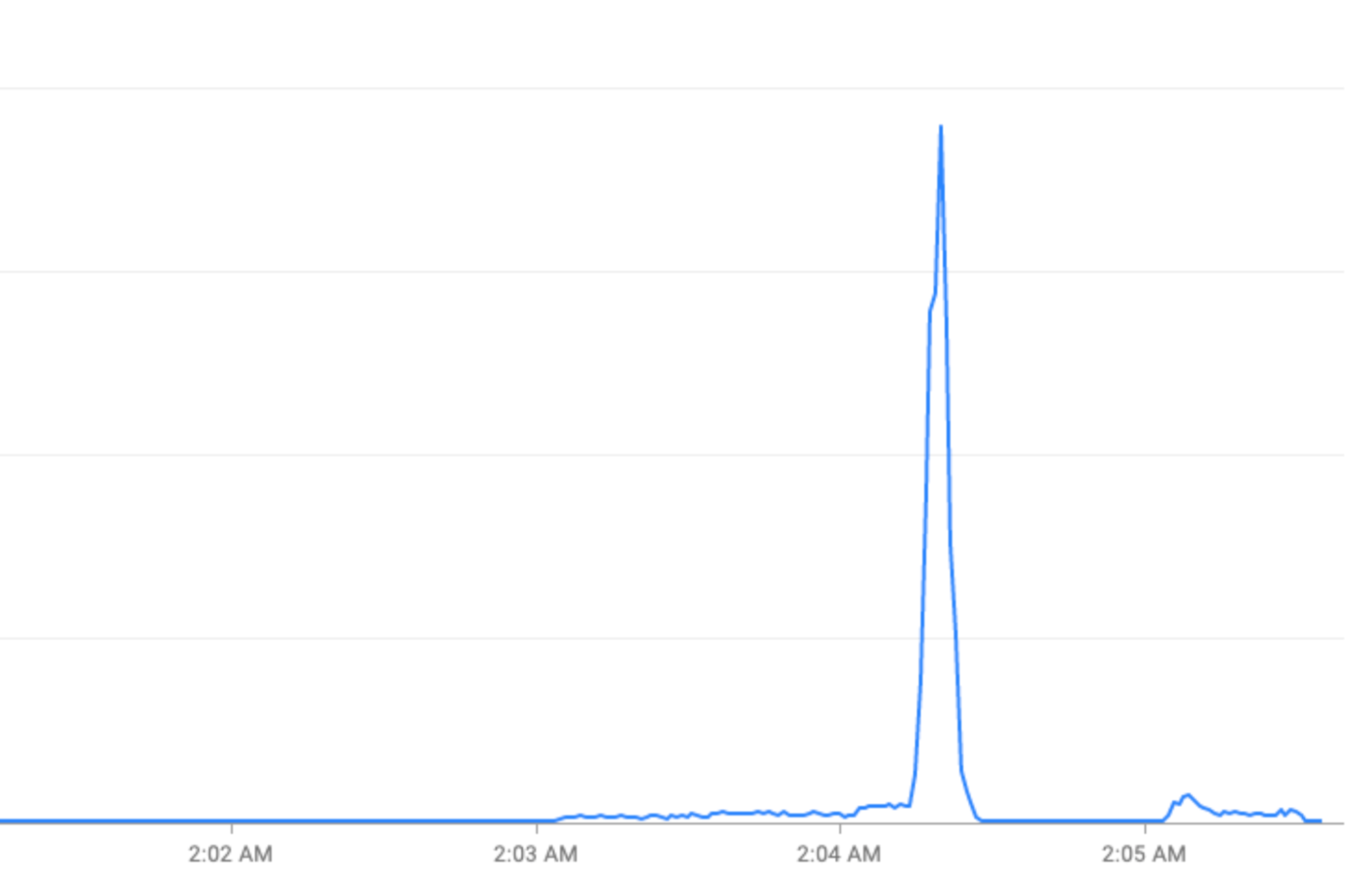
Événements spéciaux : pics de trafic pendant les fêtes (Nouvel An) ou les événements sportifs (Coupe du monde de la FIFA).
Remédier aux pics de trafic en "aplatissant la courbe"
Cette section décrit les stratégies permettant d'atténuer les pics de trafic dans la mesure du possible, c'est-à-dire de "lisser la courbe".
N'utilisez FCM que pour les cas d'utilisation appropriés.
Dans certains cas d'utilisation, il n'est pas nécessaire ni approprié d'utiliser FCM pour envoyer une notification.
Par exemple, pour les notifications d'événements d'agenda, vous pouvez planifier une tâche locale dans votre application pour afficher une notification aux heures appropriées au lieu de l'envoyer depuis le serveur de votre application. Limitez les messages FCM aux synchronisations d'agenda.
Éviter les pics
Un anti-pattern de scaling consiste à envoyer des notifications FCM aussi rapidement que les systèmes le permettent, au lieu d'appliquer une limitation côté serveur. Réfléchissez aux éléments suivants :
- Tous vos clients doivent-ils recevoir la même notification dans un délai d'une minute ? Par exemple, une plage de livraison de cinq minutes répondrait-elle toujours à vos besoins commerciaux ?
- Pouvez-vous segmenter vos clients en fonction de leur priorité pour lisser les pics ?
- Vos notifications peuvent-elles être programmées à l'avance ?
Dans la mesure du possible : évitez les stratégies qui épuisent immédiatement votre quota d'envoi FCM, pour répéter le même schéma dès que votre bucket de jetons est rechargé. Ce modèle d'accès crée des problèmes d'équilibrage de charge pour FCM et ses systèmes dépendants. Augmentez le trafic aussi progressivement que possible. Au minimum, passez de 0 au nombre maximal de RPS sur une période de 60 secondes. Privilégiez les fenêtres plus longues pour un RPS plus élevé.
Éviter les embouteillages "à l'heure pile"
Si possible, évitez d'envoyer des messages dans les deux minutes précédant ou suivant les heures rondes (:00), les quarts d'heure (:15), les demi-heures (:30) et les trois quarts d'heure (:45).
Implémenter la limitation du débit côté serveur
Implémentez la limitation côté serveur pour surveiller et gérer le flux de trafic vers FCM.
Gérer les nouvelles tentatives
Bien que FCM s'efforce d'être hautement disponible, il arrive que certaines requêtes expirent ou échouent. Bien que les raisons varient, les bonnes pratiques suivantes optimisent le comportement de réessai pour distribuer les messages dès que possible tout en minimisant l'impact sur la congestion du trafic.
Délais avant expiration
Définissez un délai avant expiration d'au moins 10 secondes pour les requêtes d'envoi avant de réessayer. La plupart des appels de procédure à distance internes de FCM utilisent un délai d'inactivité de 10 secondes.
Erreurs
- Pour les erreurs 400, 401, 403 et 404 : abandonnez et ne réessayez pas.
- Pour les erreurs 429 : réessayez après avoir attendu la durée définie dans l'en-tête "retry-after". Si aucun en-tête "retry-after" n'est défini, la valeur par défaut est de 60 secondes.
- Pour les erreurs 500 : réessayez avec un intervalle exponentiel entre les tentatives.
Intervalle exponentiel entre les tentatives
Pour éviter l'amplification des nouvelles tentatives, implémentez un intervalle exponentiel entre les tentatives avec gigue. Le SDK Admin Firebase, par exemple, implémente l'intervalle exponentiel entre les tentatives.
Voici d'autres paramètres recommandés :
- Intervalle minimum : ne relancez pas immédiatement une requête ayant échoué avec FCM. Attendez au moins 10 secondes avant de réessayer d'envoyer une requête ayant échoué.
- Intervalle maximal : définissez un intervalle maximal pour abandonner les requêtes qui ne sont plus à jour, au lieu de réessayer indéfiniment.
Si une requête est relancée en continu avec un intervalle exponentiel entre les tentatives et qu'elle échoue toujours 60 minutes plus tard, cela signifie soit qu'elle est mal classée en tant qu'erreur pouvant être relancée, soit que FCM connaît une panne et que les nouvelles tentatives peuvent aggraver la situation par inadvertance.
Créez des plans de déploiement et de rollback, et apportez des modifications progressives.
Lorsque vous apportez des modifications importantes au trafic, par exemple en augmentant le trafic vers FCM ou en le déplaçant entre les régions ou les réseaux, la conception d'un plan de déploiement/rétrogradation et l'implémentation de modifications progressives protégeront vos utilisateurs, votre service et FCM.
- Un plan de déploiement permet d'aligner les attentes des partenaires. Dans certaines situations (décrites ci-dessous), vous pouvez partager votre plan de déploiement à l'avance avec l'équipe FCM pour éviter les surprises.
- Un plan de rollback vous permet de tenir compte des imprévus et de préparer des mécanismes pour récupérer rapidement et en toute sécurité en cas de défaillance inattendue.
- Apporter des modifications progressives comporte deux aspects :
- Augmentations "par étapes" : les étapes doivent être de 1 %, 5 %, 10 %, 25 %, 50 %, 75 % et 100 %, ou plus précises. Imprégnez-vous (observez le comportement du système sous charge) de chaque étape pendant un jour à une semaine. Cela vous permet de repérer les problèmes potentiels avant la prochaine étape.
- Augmentation progressive du trafic : lorsque vous augmentez le trafic à chaque "étape", répartissez-le de manière fluide sur au moins une heure. Cela permet à l'infrastructure d'équilibrage de charge de FCM de faire évoluer correctement votre nouveau trafic tout en minimisant le risque de points chauds et de congestion.
Voici un scénario hypothétique pour migrer 500 000 RPS à l'échelle mondiale de l'ancienne API HTTP FCM vers l'API HTTP v1 FCM :
| Semaine | Step | Stratégie d'activation progressive |
|---|---|---|
| 0 | 1% d'activation progressive | Augmentez progressivement le nombre de requêtes par seconde de 0 à 5 000 pour FCM HTTP/1 au cours d'une heure. |
| 1 | 5% d'activation progressive | Augmentez progressivement le nombre de requêtes par seconde de 5 000 à 25 000 sur deux heures. |
| 2 | Augmentation progressive de 10 % | Augmentez progressivement le nombre de requêtes par seconde de 25 000 à 50 000 sur deux heures. |
| 3 | 25% d'activation progressive | Augmentation progressive de 50 000 à 125 000 RPS en trois heures |
| 4 | Activation progressive à 50 % | Augmentation de 125 000 à 250 000 RPS en six heures |
| 5 | 75% d'activation progressive | Augmentation de 250 000 à 375 000 RPS en six heures |
| 6 | Activation progressive à 100 % | Augmentation de 375 000 à 500 000 RPS en six heures |
Exemple de plan de rollback :
- Si la latence du 95e centile dépasse 500 ms ou si le taux d'erreur dépasse 1% pendant plus d'une heure à une étape quelconque, utilisez la configuration dynamique pour revenir immédiatement à l'étape précédente.
- Continuez à annuler les modifications jusqu'à ce que la latence et le taux d'erreur reviennent à des niveaux nominaux.
Quand contacter FCM
Contactez FCM via l'assistance Firebase si l'un des cas suivants s'applique :
- Les quotas par défaut ne correspondent plus à votre cas d'utilisation
- Vous modifiez vos habitudes d'envoi dans un délai de trois mois à une échelle de 100 000 RPS au niveau mondial ou de 30 000 RPS au niveau continental.