
無論您是剛開始開發應用程式,還是已在執行高流量服務,本指南的洞察資料和建議都能協助您順利擴大規模,充分運用 FCM。如果您需要傳送大量訊息,這些概念和做法可協助您避免負面影響。
重要詞彙與概念
訊息要求:FCM 訊息要求,可與「要求」、「訊息」或「查詢」互換使用。
每秒要求數 (RPS):用來描述 FCM 接收要求的速率,與每秒查詢次數 (QPS) 可互換使用。
配額權杖、權杖儲存區和補充:透過 FCM HTTP v1 API 傳送訊息時,每個要求都會在指定時間範圍內耗用分配到的配額權杖。這個時間範圍稱為「權杖儲存區」,會在時間範圍結束時「重新填滿」。舉例來說,HTTP v1 API 會為每個 1 分鐘的權杖儲存區分配 60 萬個配額權杖,並在每個 1 分鐘時間視窗結束時重新填滿。
伺服器端節流:當流量超過 FCM 服務的容量時,系統會拒絕超出服務容量的要求,以限制傳入流量的速率。系統可能會傳回含有 retry-after 標頭的 429 錯誤回應,表示您應等待一段時間,再重試要求。
用戶端節流:如果用戶端發現要求失敗、延遲時間過長或發生 429 錯誤,應主動限制輸出流量,避免加劇壅塞情形。
指數輪詢: 重試錯誤時,請加入指數遞增的時間延遲。例如:1 秒、2 秒、4 秒、8 秒、16 秒、32 秒等。
抖動:避免以固定間隔重試要求。使用隨機延遲時,您會透過隨機程序變更重試延遲,以便將延遲時間平均分配到一段時間內 (例如:0.9 秒、2.3 秒、4.1 秒、8.5 秒、17.9 秒、34.7 秒)。
重試放大:如果重試失敗的要求時沒有指數輪詢/抖動,這些要求通常會累積並增加持續的流量負載,可能「放大」並加劇流量壅塞問題。
問題:流量高峰
FCM 每秒可處理數百萬個要求 (RPS)。流量尖峰是造成系統性壅塞、延遲問題和中斷的最大原因。
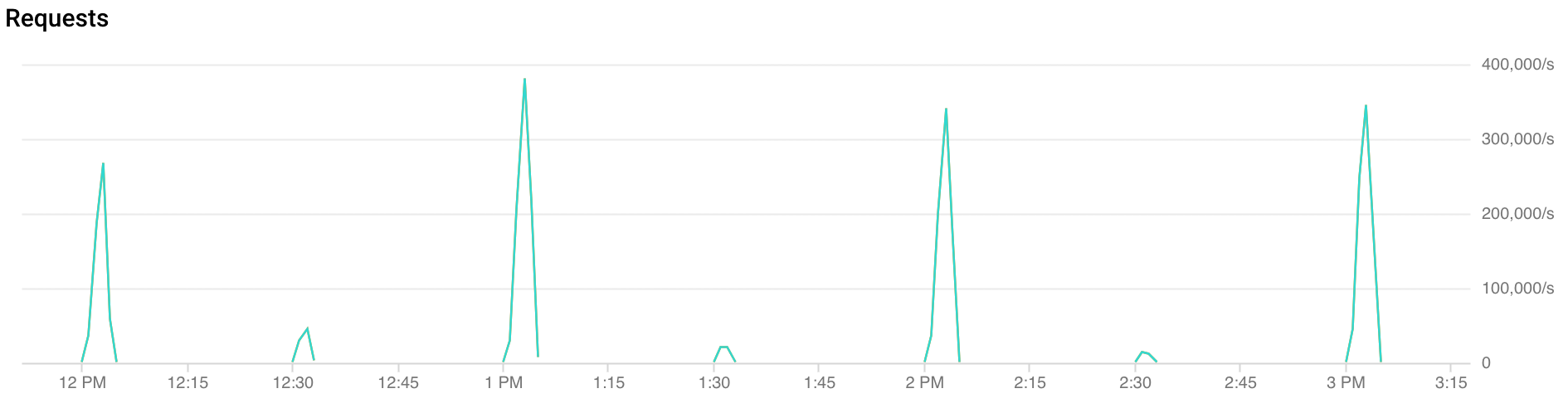
什麼是流量尖峰?
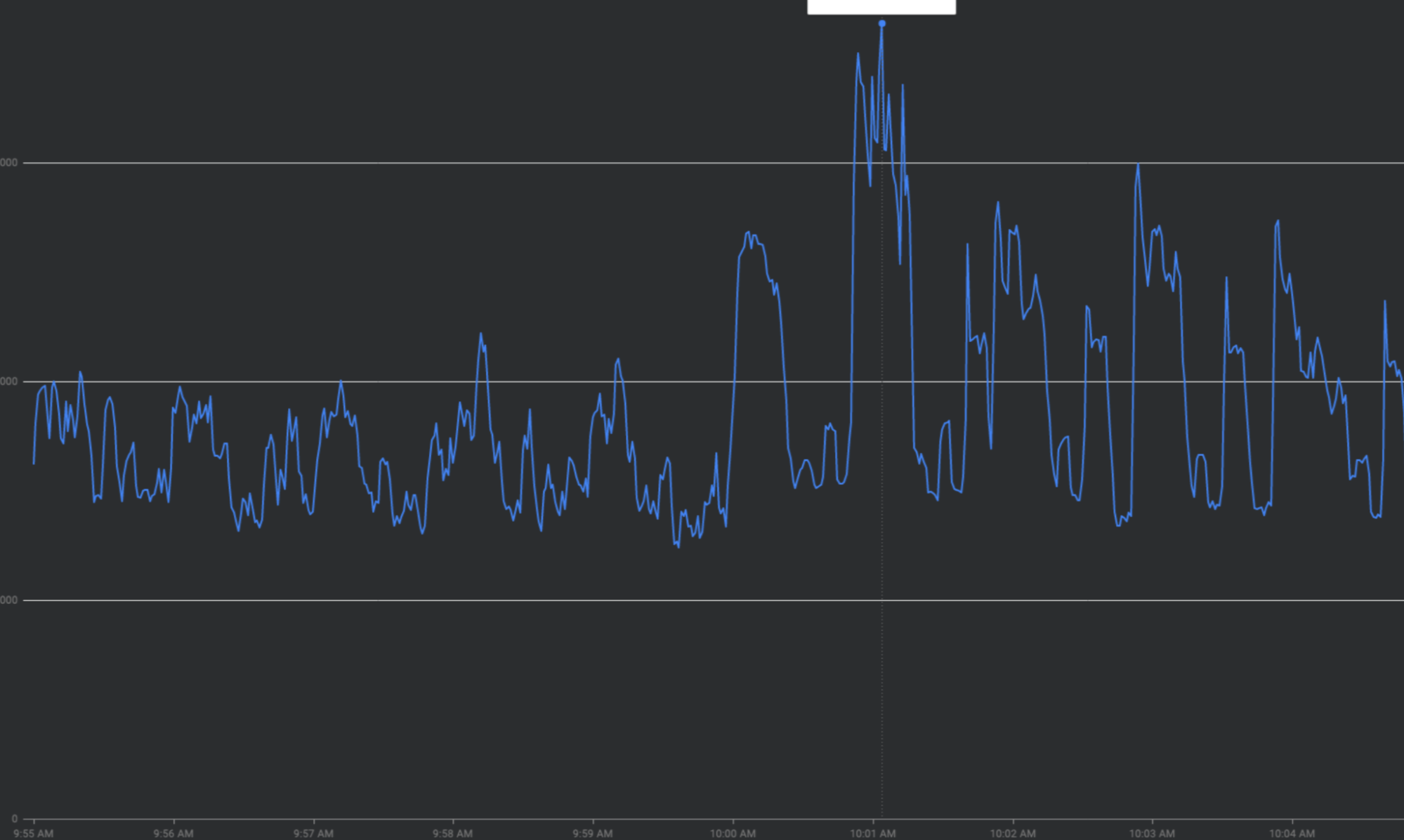
流量暴增的類型有很多種。
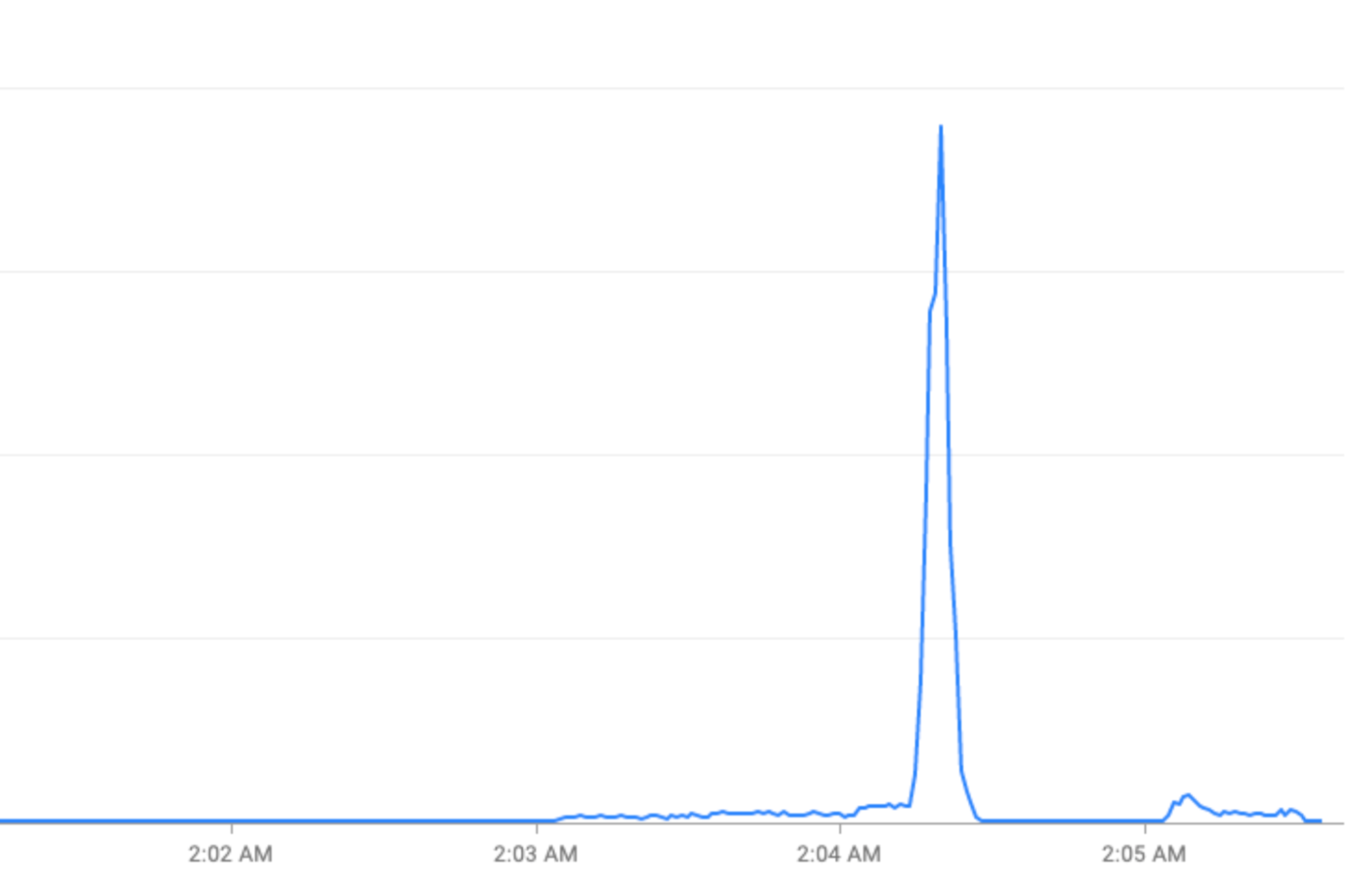
每小時的尖峰時段:在每小時的前 30 秒到 2 分鐘內,FCM 收到的流量會超過兩倍。在半小時和一刻鐘的時間點 (例如 00:15、00:30、00:45),也會出現類似但較小的尖峰
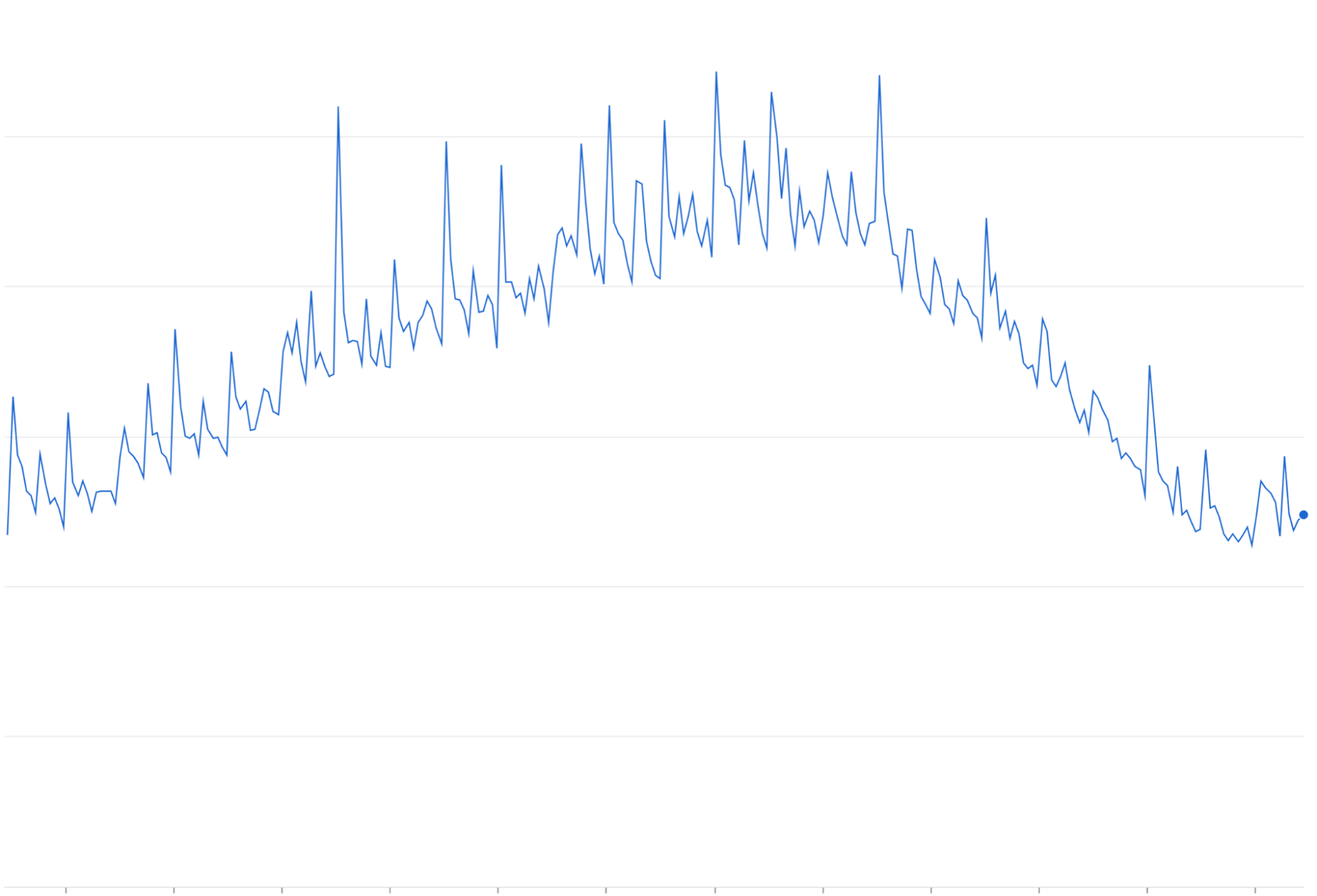
重試放大:如果沒有指數輪詢,重試失敗或逾時的要求可能會在現有流量高峰上,累積成重複的流量波。
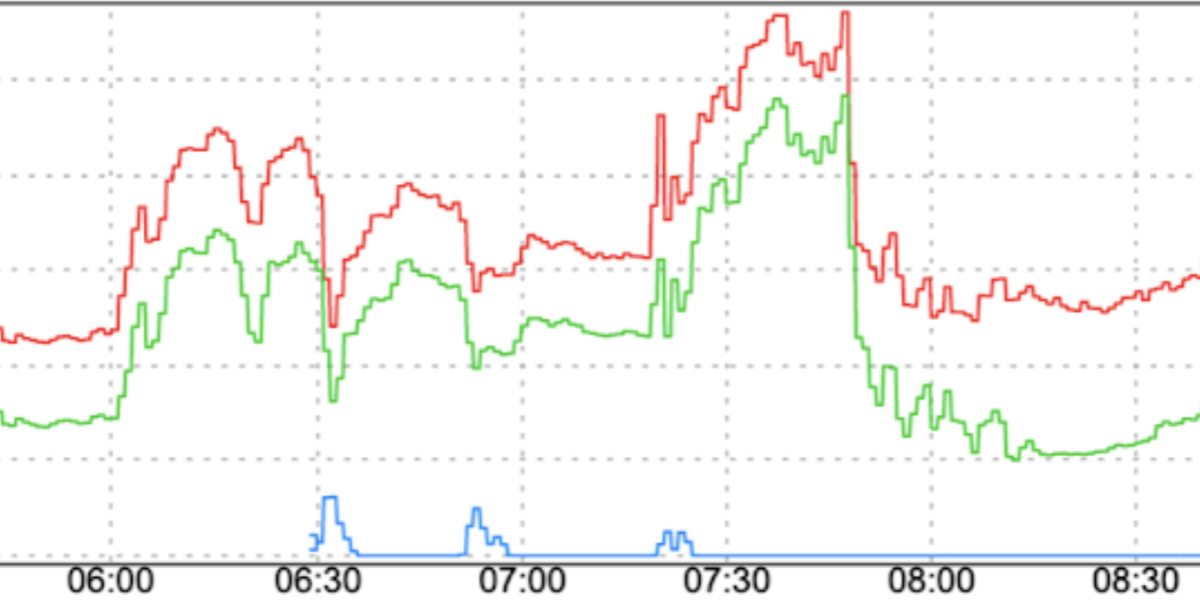
流量模式突然改變:如果將新流量導向 FCM,或將流量移至 FCM 跨區域,但沒有逐步增加等平滑化因素,可能會導致流量暴增。
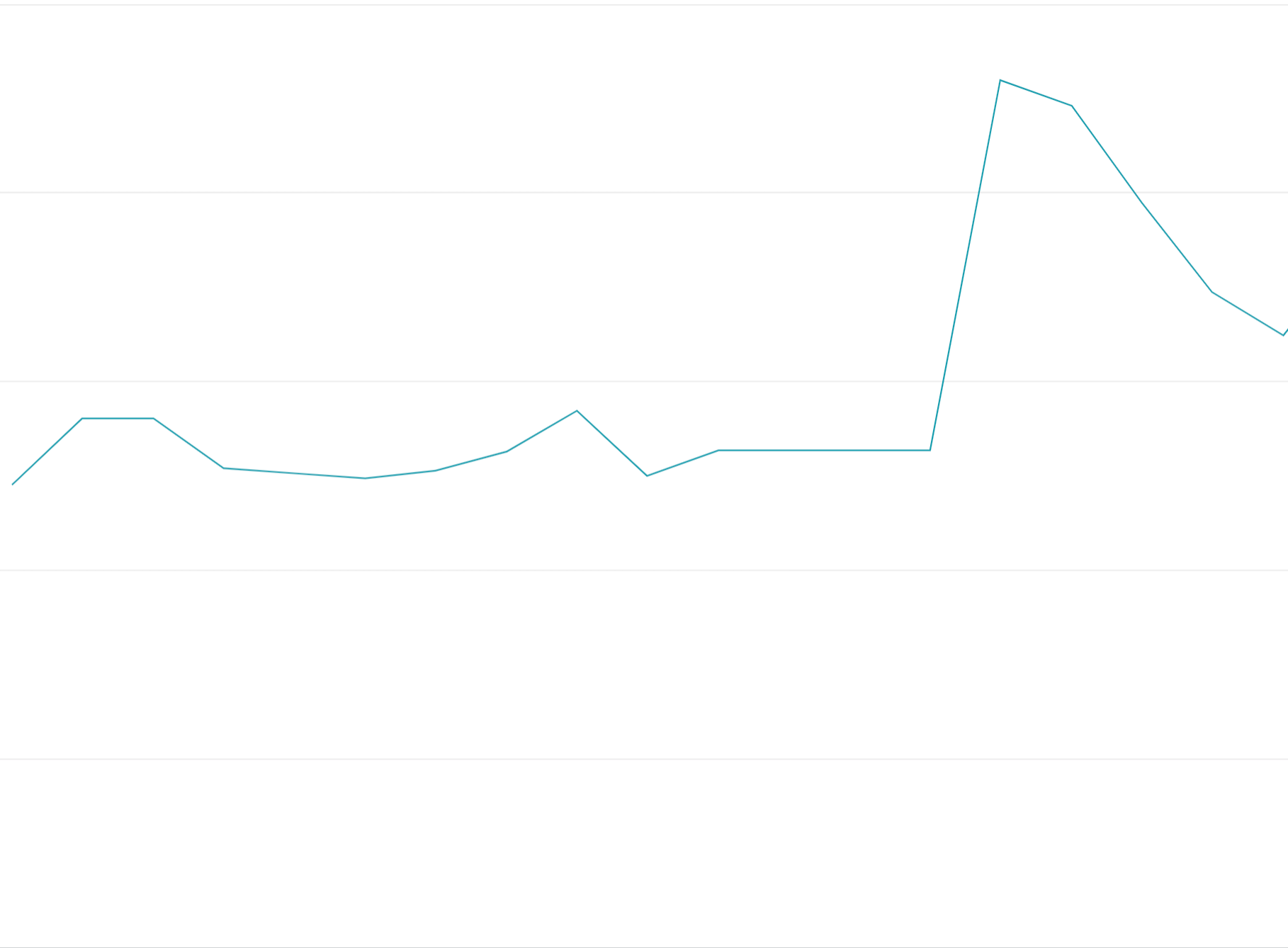
配額權杖用量前置:在配額時間範圍開始時就用盡所有配額權杖,而不是在配額時間範圍內平均分配要求,會造成難以負載平衡的開關震盪,且成本高昂。
特殊活動:節慶 (跨年夜) 或體育賽事 (FIFA 世界盃) 期間的流量高峰。
「拉平曲線」來解決流量高峰問題
本節說明如何盡可能減少流量尖峰,也就是「拉平曲線」的策略。
請僅在適當的用途中使用 FCM
在某些情況下,使用 FCM 傳送通知並非必要或適當。
舉例來說,如果是日曆活動通知,您可以在應用程式中排定本機工作,在適當時間顯示通知,而不是從應用程式伺服器傳送通知。將 FCM 訊息限制為日曆同步。
避免尖峰時段
其中一種反模式是盡快傳送 FCM 通知,而不是套用伺服器端節流。請考量下列事項:
- 是否需要在一分鐘內向所有顧客傳送相同的通知?舉例來說,5 分鐘的送達時間範圍是否仍符合你的業務需求?
- 是否可根據優先順序區隔顧客,以平緩尖峰時段的流量?
- 可以預先排定通知時間嗎?
盡可能避免採用會立即用盡 FCM 傳送配額的策略,以免權杖儲值後又重複這種模式。這種存取模式會為 FCM 和其依附系統造成負載平衡問題。盡可能逐步增加流量。至少要以 60 秒的時間範圍,將每秒要求數從 0 提升至上限。建議使用較長的時間範圍,以提高每秒查詢次數。
避開「整點」流量
盡可能:避免在每小時的第 00、15、30 和 45 分鐘前後 2 分鐘內傳送訊息。
實作伺服器端節流
實作伺服器端節流,監控及管理 FCM 的流量。
處理重試
FCM 致力於提供高可用性,但有時部分要求會逾時或失敗。雖然原因各不相同,但下列最佳做法可最佳化重試行為,盡快傳送訊息,同時盡量減少對流量壅塞的影響。
逾時
請在重試前,將傳送要求的逾時時間設為至少 10 秒。FCM 大多數的內部遠端程序呼叫都會使用 10 秒的逾時時間。
錯誤
- 如果是 400、401、403、404 錯誤:中止,不要重試。
- 如果是 429 錯誤,請等待 retry-after 標頭中設定的時間長度,然後再重試。如果未設定 retry-after 標頭,預設值為 60 秒。
- 500 錯誤:以指數輪詢方式重試。
指數輪詢
為避免重試次數增加,請實作指數輪詢,並加入隨機延遲,以重試要求。舉例來說,Firebase Admin SDK 會實作指數輪詢。
以下是其他建議設定:
- 最短間隔:請勿立即使用 FCM 重試失敗的要求。請等待至少 10 秒,再重試失敗的要求。
- 間隔上限:設定間隔上限,以便捨棄不再及時的要求,而不是無限期重試。
如果系統持續以指數輪詢方式重試要求,但 60 分鐘後仍失敗,可能是因為要求錯誤分類為可重試的錯誤,或是 FCM 發生中斷,導致重試作業無意間加劇問題。
制定推出和復原計畫,並逐步進行變更
進行大規模流量變更時 (例如增加 FCM 的流量,或在區域或網路間轉移流量),請設計推出/復原計畫並逐步實施變更,以保護使用者、服務和 FCM。
- 推出計畫可讓利害關係人瞭解相關要求。在特定情況下 (如下所述),您可能需要事先與 FCM 團隊分享推出計畫,以免發生意外。
- 復原計畫可讓您因應突發狀況,並準備好機制,以便從非預期的故障中快速安全地復原。
- 逐步變更有兩個層面:
以下是假設情境,說明如何將全球 500,000 RPS 從 FCM 舊版 HTTP API 遷移至 FCM HTTP v1 API:
| 週 | 步驟 | 逐步增加策略 |
|---|---|---|
| 0 | 1% 增加曝光量 | 在一小時內,從 0 RPS 順利增加至 5,000 RPS,並透過 FCM HTTP v1 傳送訊息。 |
| 1 | 5% 增加曝光量 | 在 2 小時內,從 5,000 RPS 逐步增加至 25,000 RPS。 |
| 2 | 10% 升速 | 在 2 小時內,每秒要求數從 25,000 順利增加到 50,000 |
| 3 | 25% 增加曝光量 | 在 3 小時內,從 50,000 RPS 逐步增加至 125,000 RPS |
| 4 | 50% 升速 | 在 6 小時內,從 125,000 RPS 逐步增加至 250,000 RPS |
| 5 | 75% 升速 | 在 6 小時內,將 RPS 從 250,000 提高至 375,000 |
| 6 | 100% 升級 | 在 6 小時內,從 375,000 RPS 逐步增加至 500,000 RPS |
假設復原計畫:
- 如果 95% 百分位數的延遲時間超過 500 毫秒,或錯誤率在任何步驟中超過 1% 且持續超過一小時,請使用動態設定立即回溯至上一個步驟。
- 繼續回溯至先前的步驟,直到延遲時間和錯誤率恢復正常為止。
何時該聯絡 FCM
如有下列任何情況,請透過 Firebase 支援團隊與 FCM 聯絡:
- 預設配額不再符合您的用途
- 您在 3 個月內變更傳送模式,且規模達到全球 10 萬 RPS 或洲際 3 萬 RPS。