
अगर आपको नया ऐप्लिकेशन लॉन्च करना है या आपकी सेवा पर पहले से ही बहुत ज़्यादा ट्रैफ़िक है, तो इस गाइड में दी गई अहम जानकारी और सुझावों से आपको फ़ायदा मिल सकता है. इसमें बताया गया है कि FCM की मदद से, अपने कारोबार को आसानी से कैसे बढ़ाया जा सकता है. इन कॉन्सेप्ट और तरीकों की मदद से, बड़ी संख्या में मैसेज भेजने पर होने वाले बुरे असर से बचा जा सकता है.
मुख्य शब्द और कॉन्सेप्ट
मैसेज का अनुरोध: FCM मैसेज का अनुरोध. इसका इस्तेमाल "अनुरोध", "मैसेज" या "क्वेरी" के तौर पर भी किया जाता है.
अनुरोध प्रति सेकंड (आरपीएस): यह एक मेट्रिक है. इससे FCM को मिलने वाले अनुरोधों की दर के बारे में पता चलता है. इसका इस्तेमाल, क्वेरी प्रति सेकंड (क्यूपीएस) के साथ किया जाता है.
कोटा टोकन, टोकन बकेट, और रीफ़िल: FCM HTTP v1 API के ज़रिए मैसेज भेजते समय, हर अनुरोध के लिए तय समय में कोटा टोकन इस्तेमाल होता है. इस विंडो को "टोकन बकेट" कहा जाता है. यह समयसीमा खत्म होने पर, पूरी तरह से रीफ़िल हो जाती है. उदाहरण के लिए: HTTP v1 API, हर एक मिनट के टोकन बकेट के लिए 600K कोटा टोकन देता है. ये टोकन, हर एक मिनट के बाद फिर से भर जाते हैं.
सर्वर-साइड थ्रॉटलिंग: जब ट्रैफ़िक का वॉल्यूम, FCM सेवा की क्षमता से ज़्यादा हो जाता है, तो सेवा देने की क्षमता से ज़्यादा के अनुरोधों को अस्वीकार कर दिया जाता है, ताकि इनग्रेस फ़्लो की दर को सीमित किया जा सके. 429 हेडर के साथ retry-after गड़बड़ी वाले जवाब दिखाए जा सकते हैं. इससे यह पता चलता है कि आपको अनुरोध फिर से करने से पहले, तय समयावधि तक इंतज़ार करना चाहिए.
क्लाइंट-साइड थ्रॉटलिंग: जब क्लाइंट को अनुरोध पूरे न होने, ज़्यादा इंतज़ार के समय या 429 गड़बड़ियों का पता चलता है, तो उन्हें डेटा बाहर भेजने की दर को सीमित करना चाहिए. इससे नेटवर्क में होने वाली रुकावट को कम किया जा सकता है.
एक्सपोनेंशियल बैकऑफ़: गड़बड़ियों को ठीक करने के लिए फिर से कोशिश करते समय, समय के अंतर को तेज़ी से बढ़ाएं. उदाहरण के लिए: 1s, 2s, 4s, 8s, 16s, 32s वगैरह.
जिटरिंग: अनुरोधों को तय समय पर फिर से भेजने से बचना. जिटरिंग की मदद से, फिर से कोशिश करने के बीच के समय को अलग-अलग किया जाता है. ऐसा इसलिए किया जाता है, ताकि समय के साथ उन्हें एक जैसा डिस्ट्रिब्यूट किया जा सके. उदाहरण के लिए: 0.9 सेकंड, 2.3 सेकंड, 4.1 सेकंड, 8.5 सेकंड, 17.9 सेकंड, 34.7 सेकंड.
बार-बार अनुरोध करना: जब अनुरोध पूरे नहीं होते हैं, तो उन्हें बार-बार भेजा जाता है. हालांकि, ऐसा एक्सपोनेंशियल बैकऑफ़/जिटरिंग के बिना किया जाता है. इससे अनुरोधों की संख्या बढ़ जाती है और मौजूदा ट्रैफ़िक लोड बढ़ जाता है. इससे ट्रैफ़िक की भीड़भाड़ की समस्याएं "बढ़" सकती हैं और गंभीर हो सकती हैं.
समस्या: ट्रैफ़िक में अचानक बढ़ोतरी
FCM, हर सेकंड में लाखों अनुरोधों (आरपीएस) को प्रोसेस करता है. सिस्टम में रुकावट, देरी से डेटा ट्रांसफ़र होने, और सेवा बंद होने की सबसे बड़ी वजह ट्रैफ़िक में अचानक होने वाली बढ़ोतरी है.
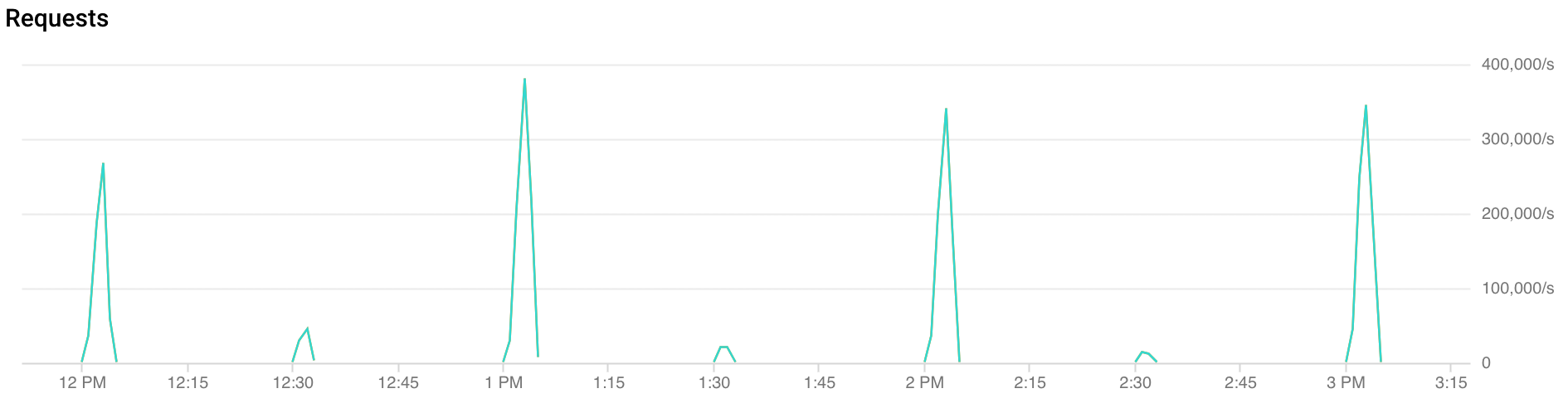
स्पाइकी ट्रैफ़िक क्या होता है?
ट्रैफ़िक में अचानक बढ़ोतरी कई तरह की होती है.
हर घंटे के शुरुआती 30 सेकंड से लेकर दो मिनट तक, FCM को सामान्य से दोगुना ट्रैफ़िक मिलता है. इसी तरह, आधे घंटे और 15 मिनट के मार्क (उदाहरण: 00:15, 00:30, 00:45) पर भी, हालांकि कम, स्पाइक देखे जाते हैं
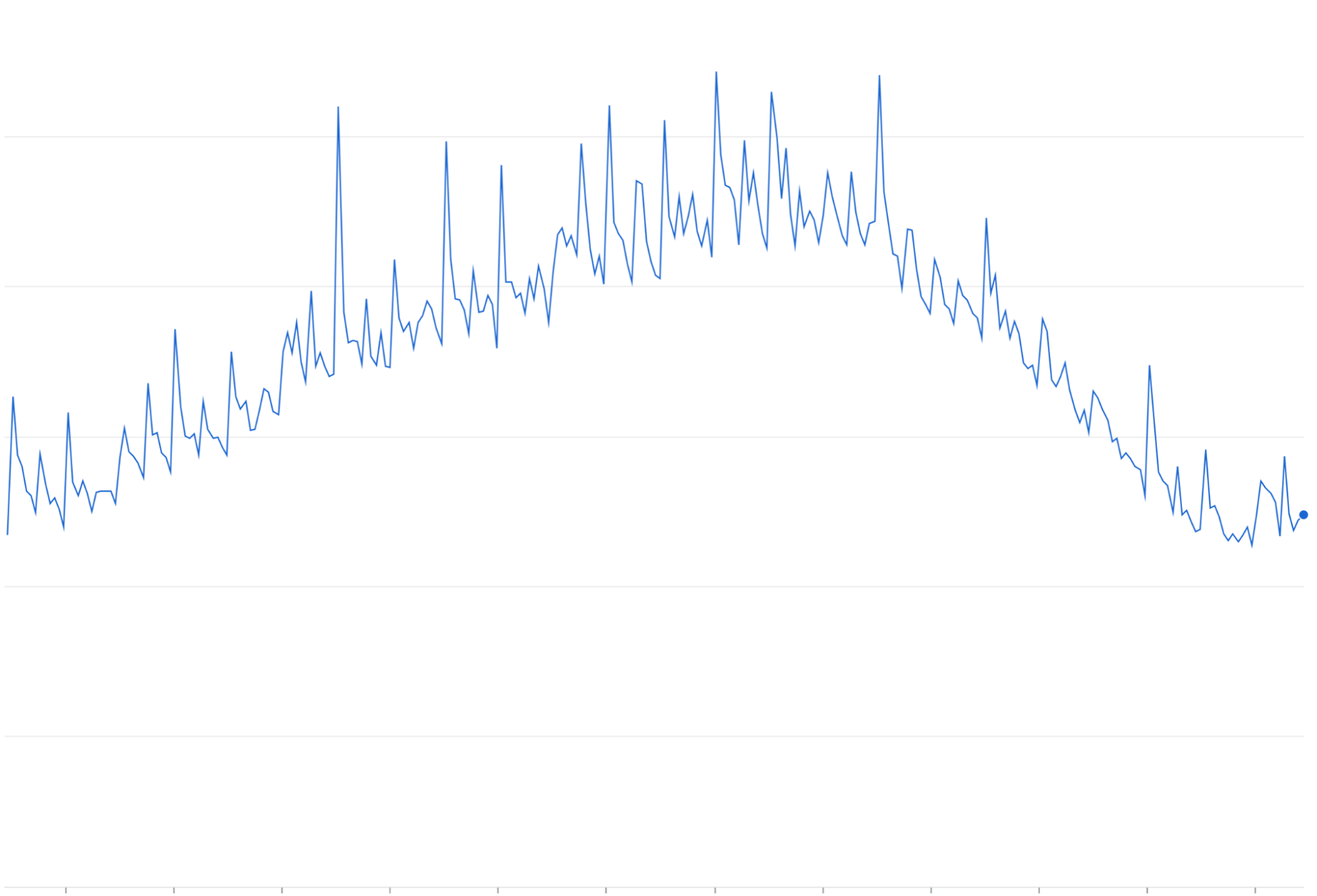
अनुरोध को फिर से भेजने की सुविधा: अनुरोध पूरा न होने या समयसीमा खत्म होने पर, एक्सपोनेंशियल बैकऑफ़ के बिना अनुरोध को फिर से भेजने से, मौजूदा ट्रैफ़िक के साथ-साथ ट्रैफ़िक की बार-बार बढ़ती हुई लहरें आ सकती हैं.
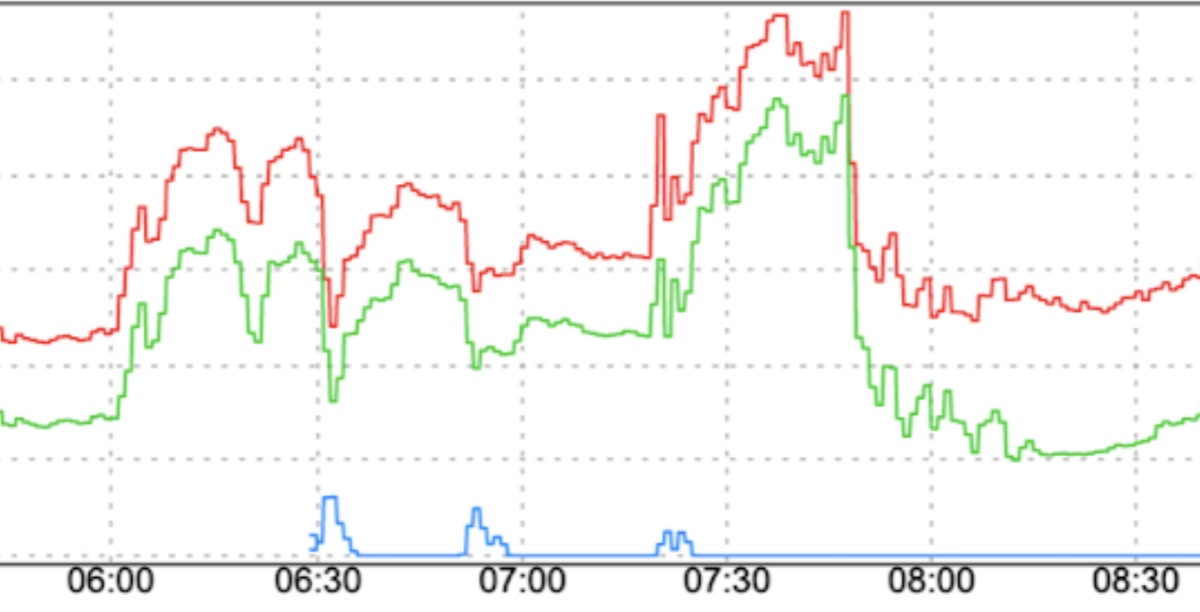
ट्रैफ़िक पैटर्न में अचानक बदलाव होना: नए ट्रैफ़िक को सीधे तौर पर FCM पर रीडायरेक्ट करने या अलग-अलग क्षेत्रों में ट्रैफ़िक को FCM पर ले जाने से, स्पाइक आ सकती हैं. ऐसा तब होता है, जब ट्रैफ़िक को धीरे-धीरे बढ़ाने जैसे स्मूद फ़ैक्टर का इस्तेमाल न किया गया हो.
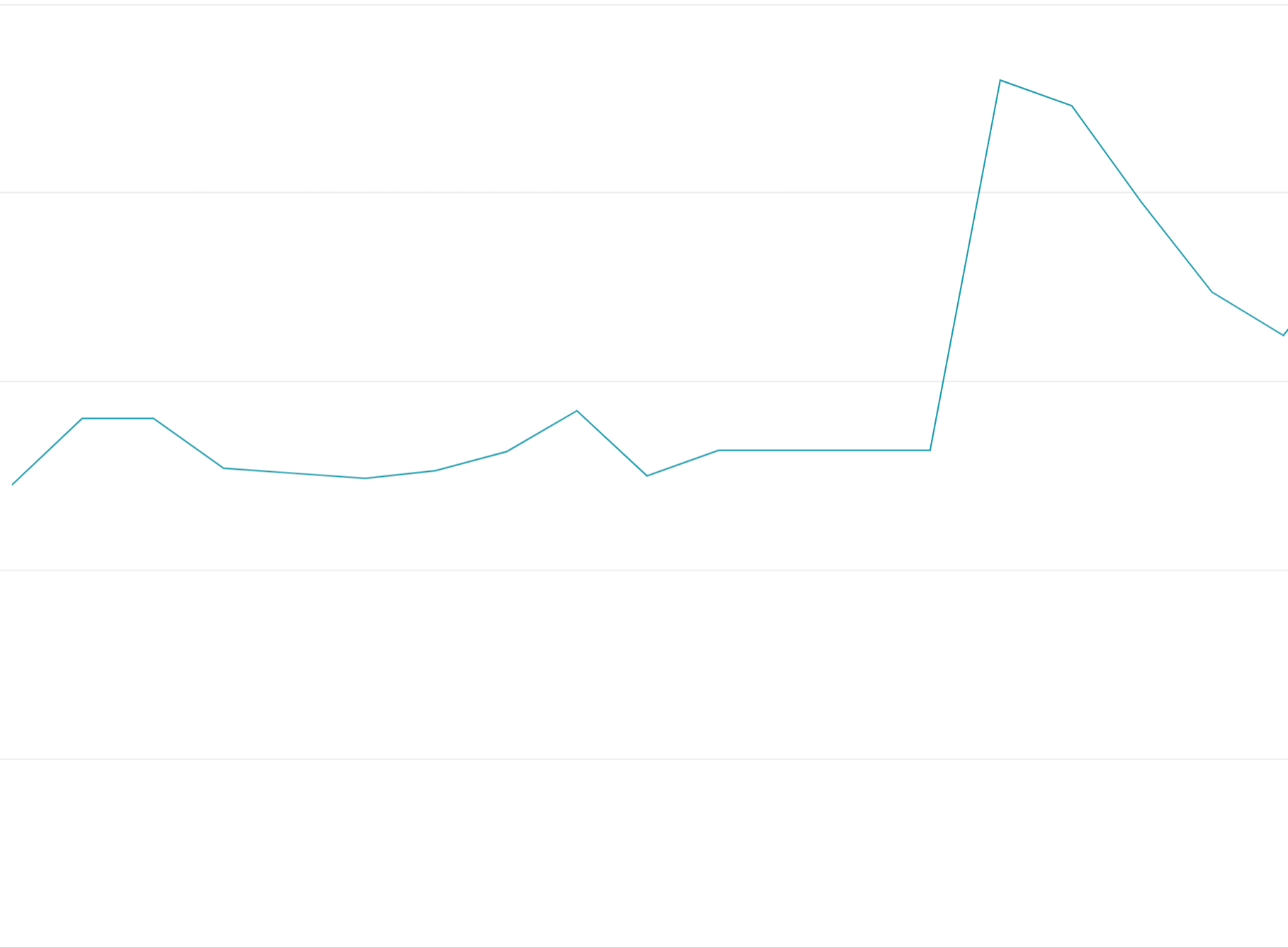
कोटा टोकन का इस्तेमाल शुरू में ही कर लेना: कोटा विंडो की शुरुआत में ही सभी कोटा टोकन का इस्तेमाल कर लेने से, अनुरोधों को कोटा विंडो में एक समान रूप से नहीं बांटा जा सकेगा. इससे, लोड में उतार-चढ़ाव होगा. इसे लोड-बैलेंस करना मुश्किल और महंगा होगा.
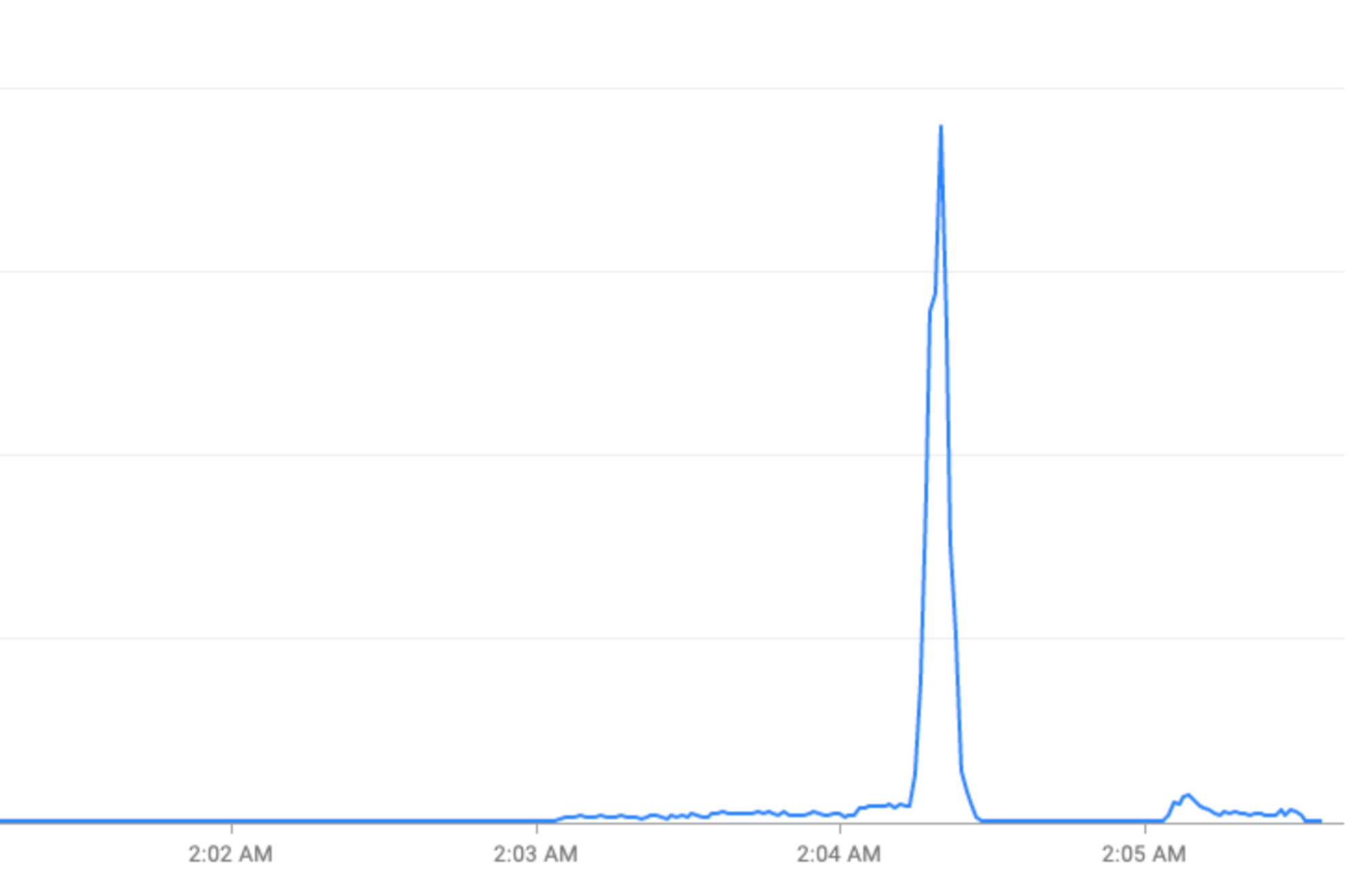
खास इवेंट: छुट्टियों (31 दिसंबर की शाम) या खेल-कूद से जुड़े इवेंट (FIFA विश्व कप) के दौरान ट्रैफ़िक में अचानक बढ़ोतरी होती है.
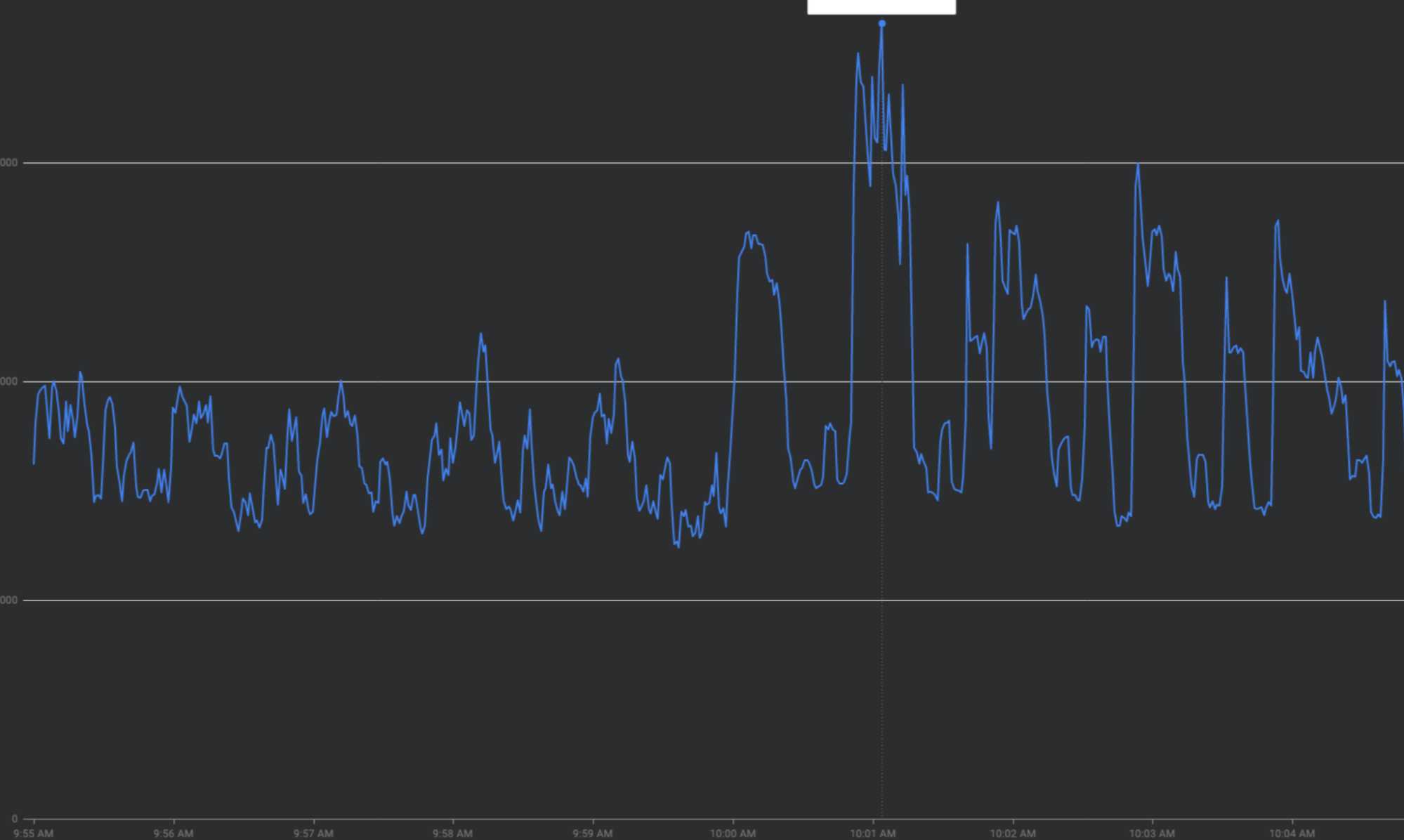
"फ़्लैटनिंग द कर्व" की मदद से, ट्रैफ़िक में अचानक होने वाली बढ़ोतरी को कम करना
इस सेक्शन में, ट्रैफ़िक में अचानक होने वाली बढ़ोतरी को कम करने की रणनीतियों के बारे में बताया गया है. इन रणनीतियों को "फ़्लैटनिंग द कर्व" कहा जाता है.
FCM का इस्तेमाल सिर्फ़ सही मामलों में करें
ऐसे कुछ इस्तेमाल के उदाहरण हैं जहां सूचना देने के लिए FCM का इस्तेमाल करना ज़रूरी या सही नहीं है.
उदाहरण के लिए, कैलेंडर इवेंट की सूचनाओं के लिए, अपने ऐप्लिकेशन में कोई लोकल टास्क शेड्यूल किया जा सकता है. इससे सूचनाएं, ऐप्लिकेशन सर्वर से भेजने के बजाय सही समय पर दिखेंगी. FCM मैसेज को कैलेंडर सिंक करने तक सीमित करें.
स्पाइक से बचें
स्केलिंग से जुड़ी एक एंटी-पैटर्न यह है कि सर्वर-साइड थ्रॉटलिंग लागू करने के बजाय, सिस्टम की अनुमति के हिसाब से FCM सूचनाएँ तुरंत भेजी जाएँ. इन बातों का ध्यान रखें:
- क्या आपके सभी खरीदारों को एक मिनट के अंदर एक ही सूचना मिलनी चाहिए? क्या डिलीवरी के लिए पांच मिनट का समय, आपके कारोबार की ज़रूरतों को पूरा कर पाएगा?
- क्या स्पाइक को कम करने के लिए, प्राथमिकता के आधार पर ग्राहकों को सेगमेंट में बांटा जा सकता है?
- क्या सूचनाएं पहले से शेड्यूल की जा सकती हैं?
जहां तक हो सके: ऐसी रणनीतियों से बचें जिनकी वजह से, FCM के मैसेज भेजने का कोटा तुरंत खत्म हो जाता है. ऐसा इसलिए, ताकि टोकन बकेट के फिर से भरने के बाद, पैटर्न को दोहराया न जा सके. इस तरह के ऐक्सेस पैटर्न से, FCM और उससे जुड़े सिस्टम के लिए लोड बैलेंसिंग से जुड़ी समस्याएं पैदा होती हैं. ट्रैफ़िक को धीरे-धीरे बढ़ाएं. कम से कम, 60 सेकंड की समयावधि में 0 से ज़्यादा से ज़्यादा आरपीएस तक रैंप करें. ज़्यादा आरपीएस के लिए, लंबी विंडो को प्राथमिकता दें.
"हर घंटे" के हिसाब से ट्रैफ़िक की जानकारी देने वाली सुविधा का इस्तेमाल न करना
जहां तक हो सके: :00, :15, :30, और :45 मिनट के मार्क के दो मिनट के अंदर मैसेज न भेजें.
सर्वर-साइड थ्रॉटलिंग लागू करना
FCM पर ट्रैफ़िक के फ़्लो को मॉनिटर और मैनेज करने के लिए, सर्वर-साइड थ्रॉटलिंग लागू करें.
फिर से कोशिश करने की सुविधा
FCM हमेशा उपलब्ध रहने की कोशिश करता है. हालांकि, कभी-कभी कुछ अनुरोधों का समय खत्म हो जाता है या वे पूरे नहीं हो पाते. इसकी कई वजहें हो सकती हैं. हालांकि, यहां दिए गए सबसे सही तरीकों से, फिर से कोशिश करने की सुविधा को ऑप्टिमाइज़ किया जा सकता है. इससे मैसेज जल्द से जल्द डिलीवर किए जा सकते हैं. साथ ही, ट्रैफ़िक की भीड़ पर पड़ने वाले असर को कम किया जा सकता है.
टाइम आउट
फिर से कोशिश करने से पहले, भेजने के अनुरोधों पर कम से कम 10 सेकंड का टाइमआउट सेट करें. FCM के ज़्यादातर इंटरनल रिमोट प्रोसीजर कॉल, 10 सेकंड के टाइमआउट का इस्तेमाल करते हैं.
गड़बड़ियां
- 400, 401, 403, 404 गड़बड़ियों के लिए: अनुरोध को रद्द करें और फिर से कोशिश न करें.
- 429 गड़बड़ियों के लिए: retry-after हेडर में सेट की गई अवधि के बाद फिर से कोशिश करें. अगर retry-after हेडर सेट नहीं है, तो डिफ़ॉल्ट रूप से 60 सेकंड पर सेट हो जाता है.
- 500 गड़बड़ियों के लिए: एक्स्पोनेंशियल बैकऑफ़ के साथ फिर से कोशिश करें.
एक्स्पोनेंशियल बैकऑफ़
फिर से कोशिश करने की संख्या को कम करने के लिए, अनुरोधों को फिर से भेजने के लिए, एक्स्पोनेंशियल बैक-ऑफ़ के साथ जिटरिंग लागू करें. उदाहरण के लिए, Firebase Admin SDK टूल, एक्सपोनेंशियल बैकऑफ़ लागू करता है.
यहां कुछ और सेटिंग के बारे में बताया गया है:
- कम से कम इंटरवल: अगर FCM के ज़रिए भेजा गया अनुरोध पूरा नहीं होता है, तो तुरंत फिर से अनुरोध न भेजें. अनुरोध पूरा न होने पर, कम से कम 10 सेकंड इंतज़ार करें. इसके बाद, फिर से कोशिश करें.
- ज़्यादा से ज़्यादा इंटरवल: ऐसे अनुरोधों को छोड़ने के लिए ज़्यादा से ज़्यादा इंटरवल सेट करें जो अब समय पर नहीं किए गए हैं. ऐसा अनिश्चित काल तक फिर से कोशिश करने के बजाय करें.
अगर किसी अनुरोध को एक्स्पोनेंशियल बैकऑफ़ के साथ लगातार फिर से भेजा जा रहा है और 60 मिनट बाद भी वह पूरा नहीं हो रहा है, तो हो सकता है कि उसे फिर से भेजे जा सकने वाली गड़बड़ी के तौर पर गलत तरीके से कैटगरी में रखा गया हो. इसके अलावा, यह भी हो सकता है कि FCM में कोई समस्या आ रही हो. ऐसे में, अनुरोध को फिर से भेजने से समस्या और बढ़ सकती है.
रोलआउट और रोलबैक प्लान बनाना और धीरे-धीरे बदलाव करना
जब बड़े पैमाने पर ट्रैफ़िक में बदलाव किए जा रहे हों, जैसे कि FCM पर ट्रैफ़िक बढ़ाना या अलग-अलग क्षेत्रों या नेटवर्क पर ट्रैफ़िक को ट्रांसफ़र करना, तो रोलआउट/रोलबैक प्लान बनाना और धीरे-धीरे बदलाव लागू करना, आपके उपयोगकर्ताओं, आपकी सेवा, और FCM को सुरक्षित रखेगा.
- लॉन्च करने के प्लान से, स्टेकहोल्डर की उम्मीदों को पूरा किया जा सकता है. कुछ स्थितियों (नीचे दी गई हैं) में, आपको रोलआउट प्लान को FCM टीम के साथ पहले से शेयर करना पड़ सकता है, ताकि आपको कोई हैरानी न हो.
- रोलबैक प्लान की मदद से, अचानक होने वाली समस्याओं का पता लगाया जा सकता है. साथ ही, अनचाही गड़बड़ियों से तुरंत और सुरक्षित तरीके से ठीक होने के लिए, तरीके तैयार किए जा सकते हैं.
- धीरे-धीरे बदलाव करने के दो पहलू हैं:
- "धीरे-धीरे" रोल आउट करना: रोल आउट के चरण 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% या इससे ज़्यादा होने चाहिए. हर चरण को एक दिन से लेकर एक हफ़्ते तक "सोक" करें. इसका मतलब है कि सिस्टम पर लोड पड़ने पर उसके व्यवहार को देखें. इससे आपको "स्टेप-अप" से पहले संभावित समस्याओं का पता लगाने में मदद मिलती है
- ट्रैफ़िक को धीरे-धीरे बढ़ाना: ट्रैफ़िक को बढ़ाने के लिए हर "चरण" में, कम से कम एक घंटे की अवधि तक ट्रैफ़िक को स्थिर रखें. इससे, लोड-बैलेंसिंग की सुविधा देने वाले FCM के इन्फ़्रास्ट्रक्चर को आपके नए ट्रैफ़िक को सही तरीके से स्केल करने में मदद मिलती है. साथ ही, इससे हॉटस्पॉट और कंजेशन की संभावना कम हो जाती है.
यहां दुनिया भर में, FCM Legacy HTTP API से FCM HTTP v1 API पर 5,00,000 आरपीएस माइग्रेट करने का एक काल्पनिक उदाहरण दिया गया है:
| हफ़्ता | चरण | धीरे-धीरे रैंप-अप करने की रणनीति |
|---|---|---|
| 0 | 1% रैंप-अप | एक घंटे में, FCM HTTP v1 के लिए 0 से 5,000 आरपीएस तक धीरे-धीरे बढ़ाएं. |
| 1 | 5% रैंप-अप | दो घंटे में, 5,000 से 25,000 आरपीएस तक धीरे-धीरे बढ़ाएं. |
| 2 | 10% रैंप-अप | दो घंटे में, 25,000 से 50,000 आरपीएस तक धीरे-धीरे बढ़ाएं |
| 3 | 25% रैंप-अप | तीन घंटे में, 50,000 से 1,25,000 आरपीएस तक बढ़ाना |
| 4 | 50% रैंप-अप | छह घंटे में, 1,25,000 से 2,50,000 आरपीएस तक बढ़ाना |
| 5 | 75% रैंप-अप | छह घंटे में, 2,50,000 से 3,75,000 आरपीएस तक बढ़ाना |
| 6 | 100% रैंप-अप | छह घंटे में, 3,75,000 से 5,00,000 आरपीएस तक बढ़ाना |
रोलबैक करने का काल्पनिक प्लान:
- अगर किसी भी चरण में, 95वें पर्सेंटाइल की लेटेन्सी 500 मि॰से॰ से ज़्यादा हो जाती है या गड़बड़ी का अनुपात एक घंटे से ज़्यादा समय तक 1% से ज़्यादा रहता है, तो डाइनैमिक कॉन्फ़िगरेशन का इस्तेमाल करके, तुरंत पिछले चरण पर रोल बैक करें.
- जब तक लेटेन्सी और गड़बड़ी का अनुपात सामान्य स्तर पर न आ जाए, तब तक पिछले चरणों पर वापस जाएं.
FCM से कब संपर्क करना चाहिए
अगर इनमें से कोई भी समस्या होती है, तो Firebase की सहायता टीम के ज़रिए FCM से संपर्क करें:
- डिफ़ॉल्ट कोटा अब आपके इस्तेमाल के उदाहरण के मुताबिक नहीं है
- आपने तीन महीने की अवधि में, दुनिया भर में 1,00,000 आरपीएस या महाद्वीप के हिसाब से 30,000 आरपीएस के हिसाब से अनुरोध भेजने के पैटर्न में बदलाव किया हो.