
Che tu stia sviluppando un'app appena nata o gestendo già un servizio con un traffico elevato, puoi trarre vantaggio dalle informazioni e dai consigli di questa guida su come scalare senza problemi con FCM. Questi concetti e queste pratiche possono aiutarti a evitare impatti negativi quando devi inviare grandi volumi di messaggi.
Termini e concetti chiave
Richiesta di messaggio: una richiesta di messaggio FCM; utilizzata in modo intercambiabile con "richiesta", "messaggio" o "query".
Richieste al secondo (RPS): una metrica per descrivere la frequenza delle richieste in entrata a FCM; utilizzata in modo intercambiabile con Query al secondo (QPS).
Token di quota, bucket di token e ricariche: quando invii messaggi all' API HTTP v1 di FCM, ogni richiesta consuma un token di quota assegnato in una determinata finestra temporale. Questa finestra, chiamata "bucket di token", si ricarica completamente alla fine di la finestra temporale. Ad esempio, l'API HTTP v1 assegna 600.000 token di quota per ogni bucket di token di 1 minuto, che si ricarica completamente alla fine di ogni finestra di 1 minuto.
Limitazione lato server: quando il volume di traffico supera la capacità del servizio FCM, le richieste oltre la capacità di pubblicazione vengono rifiutate per limitare la frequenza del flusso in entrata. Potrebbero essere restituite risposte di errore 429 con intestazioni retry-after per indicare che devi attendere un determinato periodo di tempo prima di riprovare a inviare la richiesta.
Limitazione lato client: quando i client rilevano errori di richiesta, latenza elevata,
o errori 429, devono limitare volontariamente la frequenza del flusso in uscita per evitare di esacerbare
la congestione.
Backoff esponenziale: quando riprovi a inviare le richieste in caso di errori, aggiungi ritardi di tempo che aumentano in modo esponenziale. Ad esempio: 1s, 2s, 4s, 8s, 16s, 32s e così via.
Jittering: evita di riprovare a inviare le richieste a intervalli esatti. Con il jittering, vari i ritardi dei nuovi tentativi tramite un processo casuale per distribuirli in modo uniforme nel tempo (ad esempio: 0,9 s, 2,3 s, 4,1 s, 8,5 s, 17,9 s, 34,7 s).
Amplificazione dei nuovi tentativi: quando le richieste non riuscite vengono riprovate senza backoff esponenziale/jittering, spesso si accumulano e si aggiungono al carico di traffico in corso, potenzialmente "amplificando" ed esacerbando i problemi di congestione del traffico.
Il problema: picchi di traffico
FCM elabora milioni di richieste al secondo (RPS). Il principale fattore che contribuisce alla congestione sistemica, ai problemi di latenza e alle interruzioni sono i picchi di traffico.
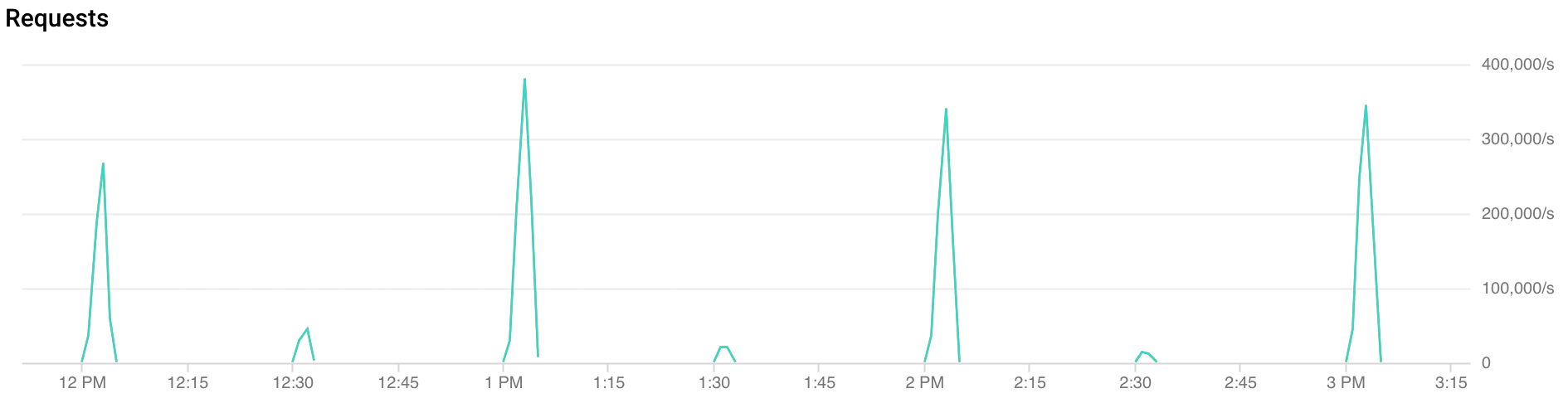
Che cos'è il traffico con picchi?
Esistono diversi tipi di picchi di traffico.
Picchi orari: FCM riceve più del doppio del traffico durante i primi 30 secondi e i primi 2 minuti di ogni ora. Picchi simili, anche se minori, si osservano anche a metà ora e a un quarto d'ora (esempi: 00:15, 00:30, 00:45).
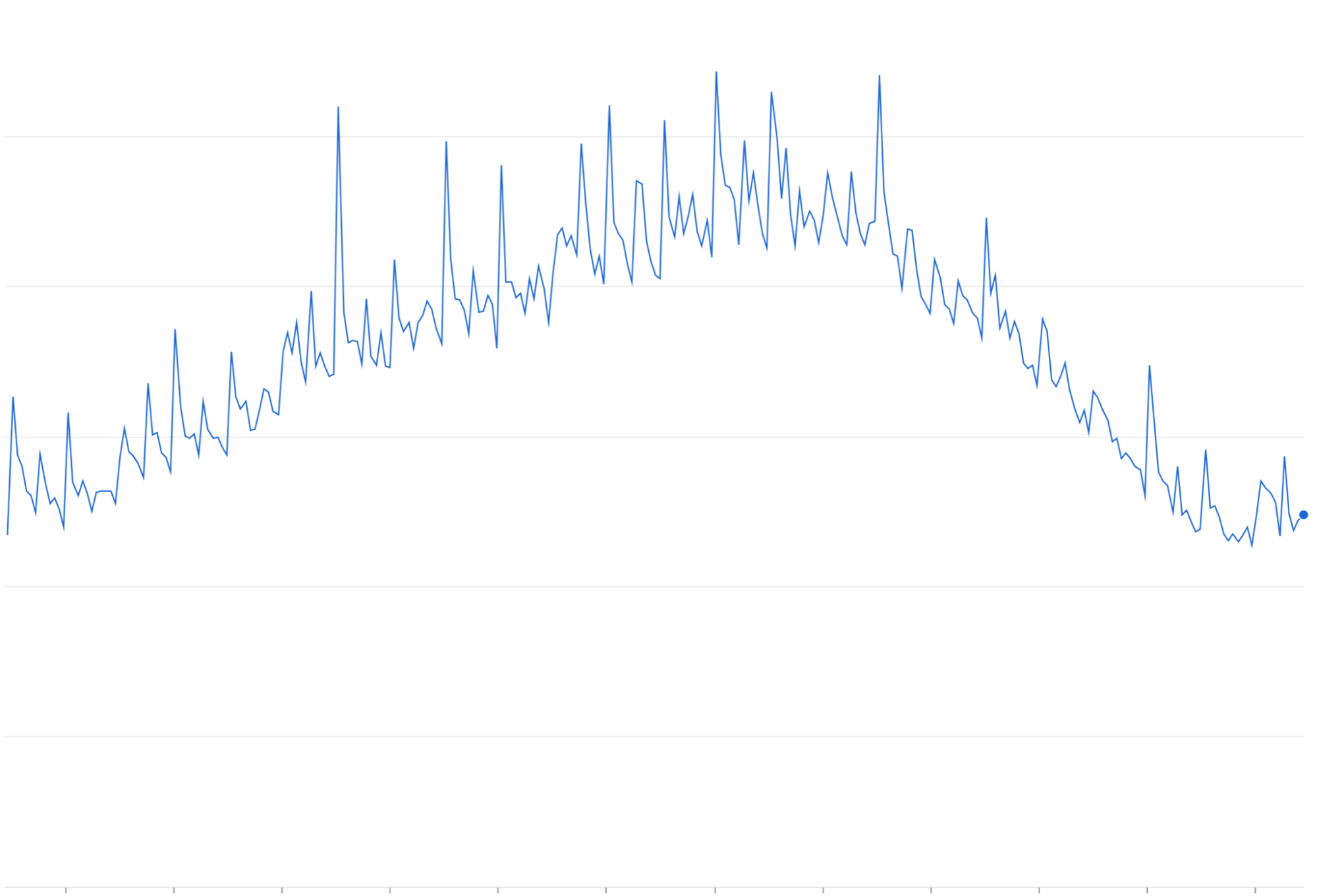
Amplificazione dei nuovi tentativi: riprovare a inviare le richieste non riuscite o con timeout senza backoff esponenziale può accumularsi in onde di traffico ripetute in aggiunta ai picchi di traffico esistenti.
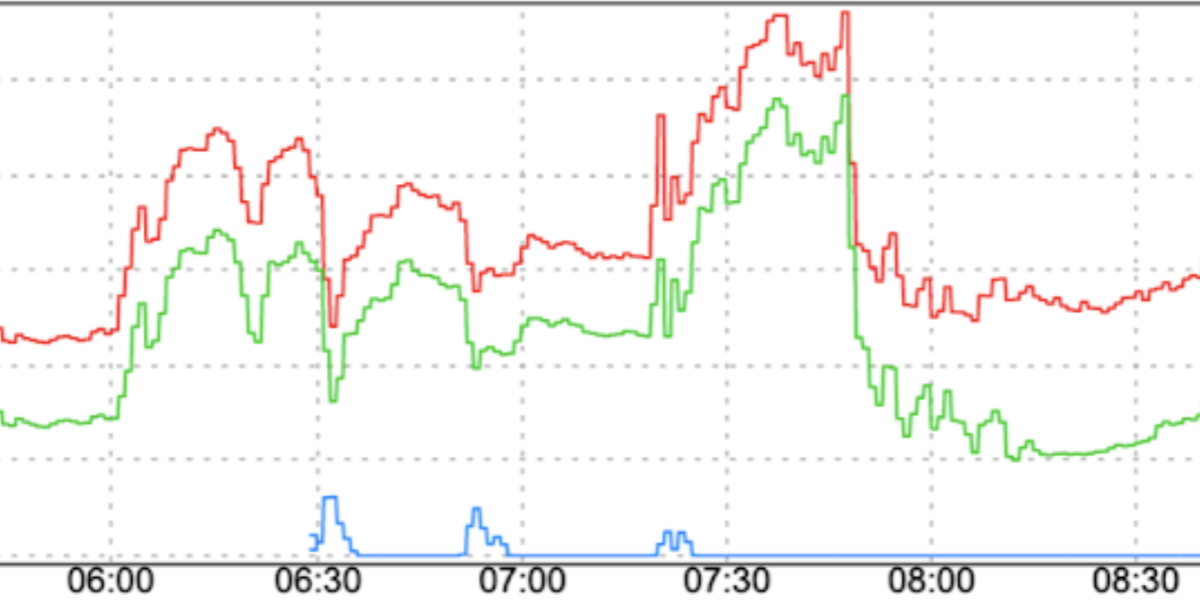
Modifiche improvvise dei pattern di traffico: indirizzare nuovo traffico a FCM o spostare il traffico a FCM tra le regioni senza fattori di smoothing come l'aumento graduale può causare picchi.
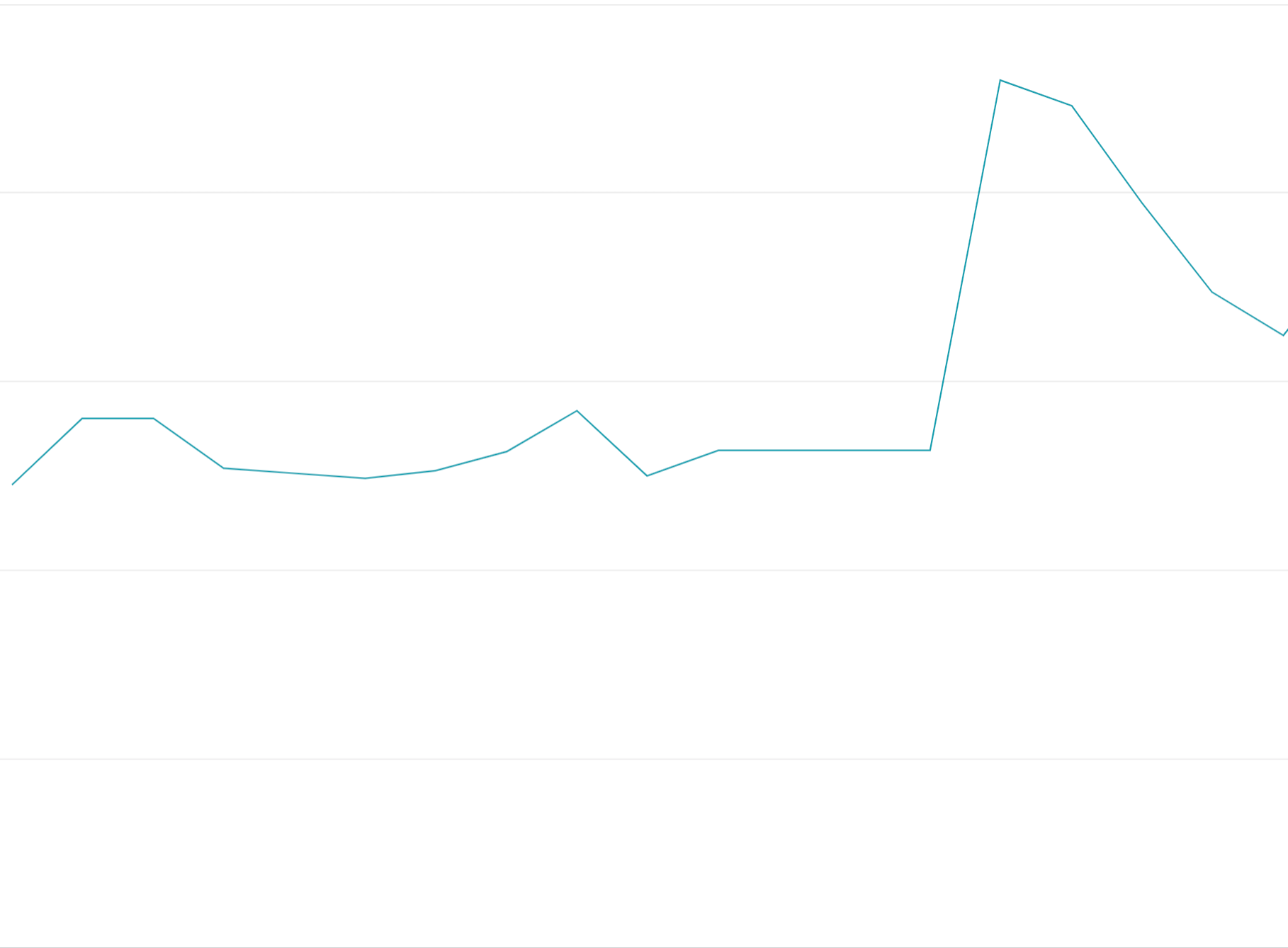
Utilizzo anticipato dei token di quota: esaurire tutti i token di quota all'inizio delle finestre di quota anziché distribuire le richieste in modo uniforme nelle finestre di quota creerà oscillazioni on-off difficili e costose da bilanciare il carico.
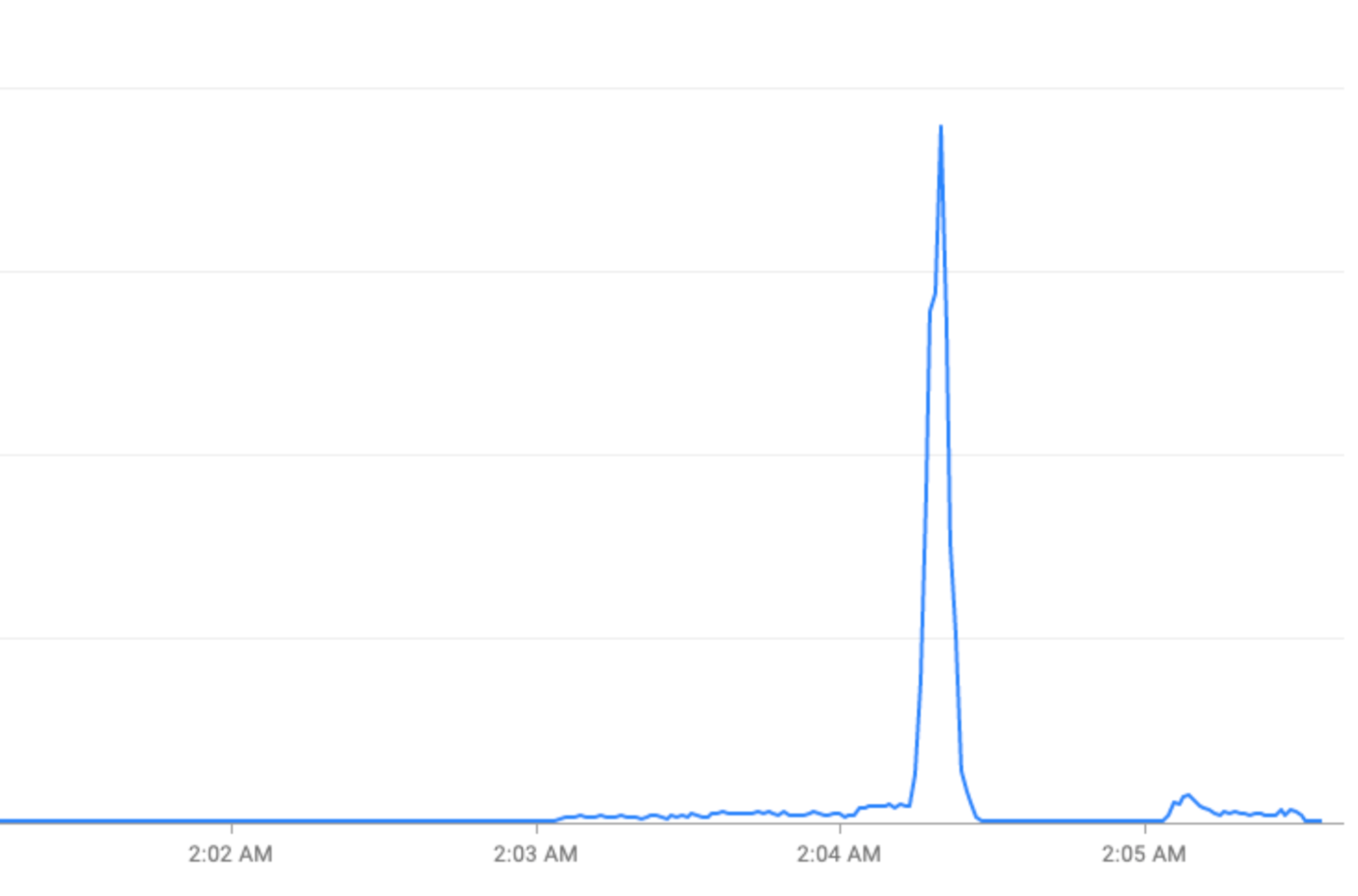
Eventi speciali: picchi di traffico durante le festività (Capodanno) o eventi sportivi (Coppa del Mondo FIFA).
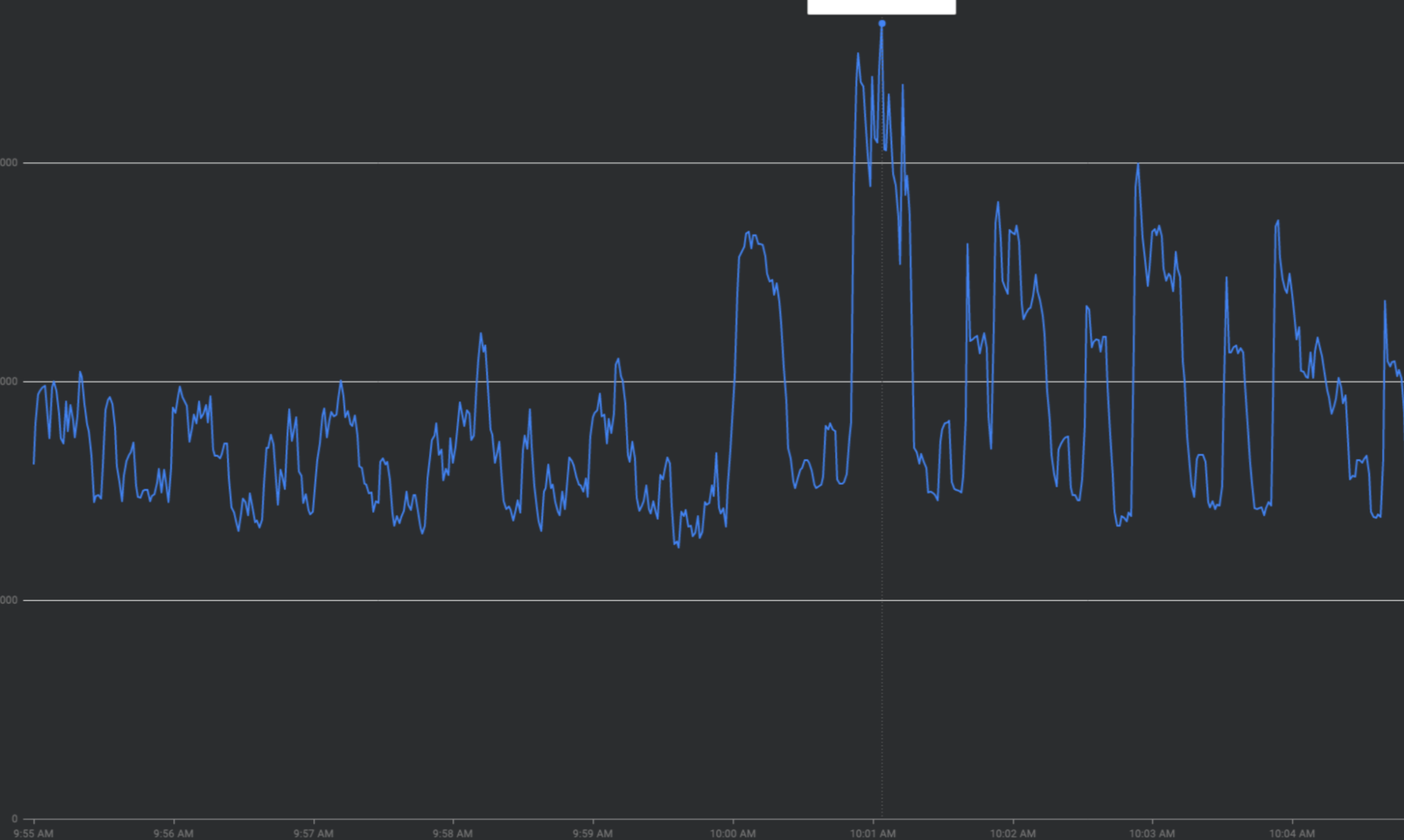
Rimediare ai picchi di traffico "appiattendo la curva"
Questa sezione descrive le strategie per attenuare i picchi di traffico, se possibile, ovvero le strategie per "appiattire la curva".
Utilizzare FCM solo per i casi d'uso appropriati
Esistono alcuni casi d'uso in cui l'utilizzo di FCM per inviare una notifica non è necessario o appropriato.
Ad esempio, per le notifiche degli eventi di Calendar, puoi pianificare un'attività locale nella tua app per visualizzare una notifica nei momenti appropriati anziché inviarla dal server dell'app. Limita i messaggi FCM alle sincronizzazioni di Calendar.
Evitare i picchi
Un anti-pattern di scalabilità consiste nell'inviare le notifiche FCM il più rapidamente possibile, anziché applicare la limitazione lato server. Considera quanto segue:
- Tutti i tuoi clienti devono ricevere la stessa notifica entro una finestra di 1 minuto? Una finestra di consegna di 5 minuti, ad esempio, soddisferebbe comunque le esigenze della tua attività?
- I tuoi clienti possono essere segmentati in base alla priorità per attenuare i picchi?
- Le notifiche possono essere pianificate in anticipo?
Ove possibile: evita le strategie che comportano l'esaurimento immediato della quota di invio di FCM, per poi ripetere il pattern non appena il token bucket si ricarica. Questo pattern di accesso crea problemi di bilanciamento del carico per FCM e i relativi sistemi dipendenti. Aumenta il traffico il più gradualmente possibile. Come minimo, aumenta da 0 al numero massimo di RPS in una finestra temporale di 60 secondi. Preferisci finestre più lunghe per un numero maggiore di RPS.
Evitare il traffico "orario"
Ove possibile: evita di inviare messaggi entro una finestra di 2 minuti da ciascuno di i segni di :00, :15, :30 e :45 minuti.
Implementare la limitazione lato server
Implementa la limitazione lato server per monitorare e gestire il flusso di traffico verso FCM.
Gestire i nuovi tentativi
Sebbene FCM si impegni a essere altamente disponibile, a volte alcune richieste vanno in timeout o non vanno a buon fine. Sebbene i motivi varino, le seguenti best practice ottimizzano il comportamento dei nuovi tentativi per inviare i messaggi il prima possibile, riducendo al minimo l'impatto sulla congestione del traffico.
Timeout
Imposta un timeout di almeno 10 secondi per le richieste di invio prima di riprovare. La maggior parte delle chiamate di procedura remota interne di FCM utilizza un timeout di 10 secondi.
Errori
- Per gli errori 400, 401, 403, 404: interrompi e non riprovare.
- Per gli errori 429: riprova dopo aver atteso la durata impostata nell'intestazione retry-after. Se non è impostata alcuna intestazione retry-after, il valore predefinito è 60 secondi.
- Per gli errori 500: riprova con backoff esponenziale.
Backoff esponenziale
Per evitare l'amplificazione dei nuovi tentativi, implementa il backoff esponenziale con jittering per riprovare a inviare le richieste. Ad esempio, l'SDK Firebase Admin implementa il backoff esponenziale.
Ecco alcune impostazioni consigliate:
- Intervallo minimo: non riprovare immediatamente a inviare una richiesta non riuscita con FCM. Attendi almeno 10 secondi prima di riprovare a inviare una richiesta non riuscita.
- Intervallo massimo: imposta un intervallo massimo per eliminare le richieste che non sono più tempestive, anziché riprovare a inviarle all'infinito.
Se una richiesta viene riprovata continuamente con backoff esponenziale e non va ancora a buon fine dopo 60 minuti, significa che è stata classificata erroneamente come errore riprovabile oppure che FCM sta riscontrando un'interruzione in cui i nuovi tentativi potrebbero esacerbare involontariamente la situazione.
Creare piani di rollout e rollback e apportare modifiche graduali
Quando apporti modifiche al traffico su larga scala, ad esempio aumentando il traffico verso FCM o spostando il traffico tra regioni o reti, la progettazione di un piano di rollout/rollback e l'implementazione di modifiche graduali proteggeranno i tuoi utenti, il tuo servizio e FCM.
- Un piano di rollout allinea le aspettative degli stakeholder. In determinate situazioni (descritte di seguito), potresti voler condividere in anticipo il tuo piano di rollout con il team di FCM per evitare sorprese.
- Un piano di rollback ti consente di tenere conto delle emergenze e di preparare meccanismi per ripristinare rapidamente e in sicurezza i guasti imprevisti.
- Apportare modifiche graduali ha due aspetti:
- Aumenti "passo dopo passo": i passaggi devono essere 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% o più precisi. "Assorbi" (osserva il comportamento del sistema sotto carico) ogni passaggio per 1 giorno o 1 settimana. In questo modo, puoi individuare potenziali problemi prima del "passaggio" successivo.
- Aumenti graduali del traffico: quando esegui ogni "passaggio" per aumentare il traffico, attenua il traffico nell'arco di almeno un'ora. In questo modo, l'infrastruttura di bilanciamento del carico di FCM può scalare in modo appropriato il nuovo traffico, riducendo al minimo il potenziale di hotspot e congestione.
Ecco uno scenario ipotetico per la migrazione di 500.000 RPS a livello globale dall'API HTTP legacy di FCM all'API HTTP v1 di FCM:
| Settimana | Passaggio | Strategia di aumento graduale |
|---|---|---|
| 0 | Aumento dell'1% | Aumenta gradualmente da 0 a 5000 RPS all'API HTTP v1 di FCM nell'arco di un'ora. |
| 1 | Aumento del 5% | Aumenta gradualmente da 5000 a 25.000 RPS in 2 ore. |
| 2 | Aumento del 10% | Aumenta gradualmente da 25.000 a 50.000 RPS in 2 ore. |
| 3 | Aumento del 25% | Aumenta da 50.000 a 125.000 RPS in 3 ore. |
| 4 | Aumento del 50% | Aumenta da 125.000 a 250.000 RPS in 6 ore. |
| 5 | Aumento del 75% | Aumenta da 250.000 a 375.000 RPS in 6 ore. |
| 6 | Aumento del 100% | Aumenta da 375.000 a 500.000 RPS in 6 ore. |
Piano di rollback ipotetico:
- Se la latenza al 95° percentile aumenta a più di 500 ms o se il rapporto di errore supera l'1% per più di un'ora in qualsiasi passaggio, utilizza la configurazione dinamica per eseguire immediatamente il rollback al passaggio precedente.
- Continua a eseguire il rollback ai passaggi precedenti finché la latenza e il rapporto di errore non tornano ai livelli nominali.
Quando contattare FCM
Contatta FCM tramite l'assistenza Firebase se si verifica una delle seguenti condizioni:
- Le quote predefinite non soddisfano più il tuo caso d'uso.
- Stai modificando i pattern di invio entro una finestra di 3 mesi a una scala di 100.000 RPS a livello globale o 30.000 RPS a livello continentale.