
Bez względu na to, czy rozwijasz nową aplikację, czy zarządzasz już usługą o dużym natężeniu ruchu, ten przewodnik zawiera przydatne informacje i zalecenia dotyczące płynnego skalowania za pomocą FCM. Te pojęcia i praktyki mogą pomóc Ci uniknąć negatywnych skutków, gdy musisz wysłać dużą liczbę wiadomości.
Kluczowe terminy i pojęcia
Żądanie wiadomości: żądanie wiadomości FCM; używane zamiennie z terminami "żądanie", "wiadomość" lub "zapytanie".
Żądania na sekundę (RPS): wskaźnik opisujący szybkość przychodzących żądań do FCM; używany zamiennie z terminem Zapytania na sekundę (QPS).
Tokeny limitu, zasobniki tokenów i doładowania: podczas wysyłania wiadomości za pomocą interfejsu FCM HTTP v1 API każde żądanie zużywa przydzielony token limitu w danym przedziale czasu. Ten przedział czasu, zwany "zasobnikiem tokenów", doładowuje się do pełna na końcu przedziału czasu. Na przykład interfejs HTTP v1 API przydziela 600 tys. tokenów limitu na każdy 1-minutowy zasobnik tokenów, który doładowuje się do pełna na końcu każdego 1-minutowego przedziału czasu.
Ograniczanie po stronie serwera: gdy natężenie ruchu przekracza możliwości usługi FCM's
capacity, żądania przekraczające możliwości obsługi są odrzucane, aby ograniczyć przepływ przychodzący
flow. Odpowiedzi na błędy 429 z nagłówkami retry-after mogą wskazywać, że przed ponowieniem żądania należy odczekać określony czas.
Ograniczanie po stronie klienta: gdy klienci zauważą nieudane żądania, duże opóźnienia,
lub 429 błędy, powinni dobrowolnie ograniczyć przepływ wychodzący, aby nie pogarszać
zatorów.
Wzrastający czas do ponowienia: podczas ponawiania prób w przypadku błędów dodaj wykładniczo rosnące opóźnienia. Na przykład: 1 s, 2 s, 4 s, 8 s, 16 s, 32 s itd.
Jittering: unikanie ponawiania żądań w dokładnych odstępach czasu. Dzięki jitteringowi możesz zmieniać opóźnienia ponawiania za pomocą procesu losowego, aby równomiernie rozłożyć je w czasie (np. 0,9 s, 2,3 s, 4,1 s, 8,5 s, 17,9 s, 34,7 s).
Wzrost liczby ponowień: gdy nieudane żądania są ponawiane bez wzrastającego czasu do ponowienia lub jitteringu, często się kumulują i zwiększają bieżące obciążenie ruchem, co może "wzmacniać" i pogarszać problemy z zatorami.
Problem: skoki natężenia ruchu
FCM przetwarza miliony żądań na sekundę (RPS). Największym czynnikiem przyczyniającym się do zatorów systemowych, problemów z opóźnieniami i awarii są skoki natężenia ruchu.
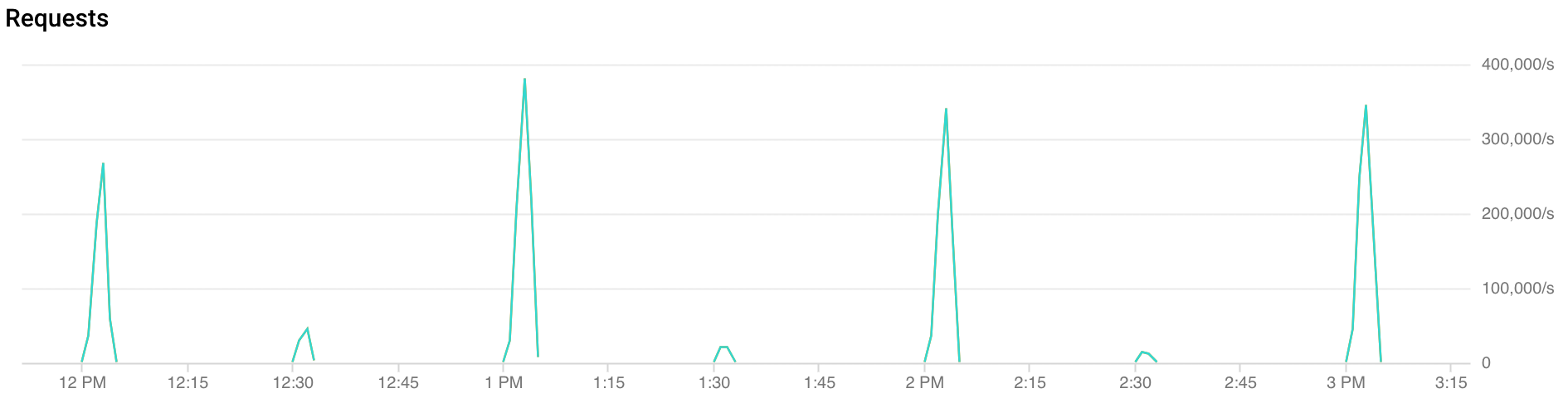
Co to jest skokowe natężenie ruchu?
Istnieje kilka różnych typów skoków natężenia ruchu.
Skoki o pełnej godzinie: FCM otrzymuje ponad 2 razy więcej ruchu w pierwszych 30 sekundach do 2 minut każdej godziny. Podobne, choć mniejsze, skoki obserwuje się też o pół godziny i kwadrans (np. 00:15, 00:30, 00:45).
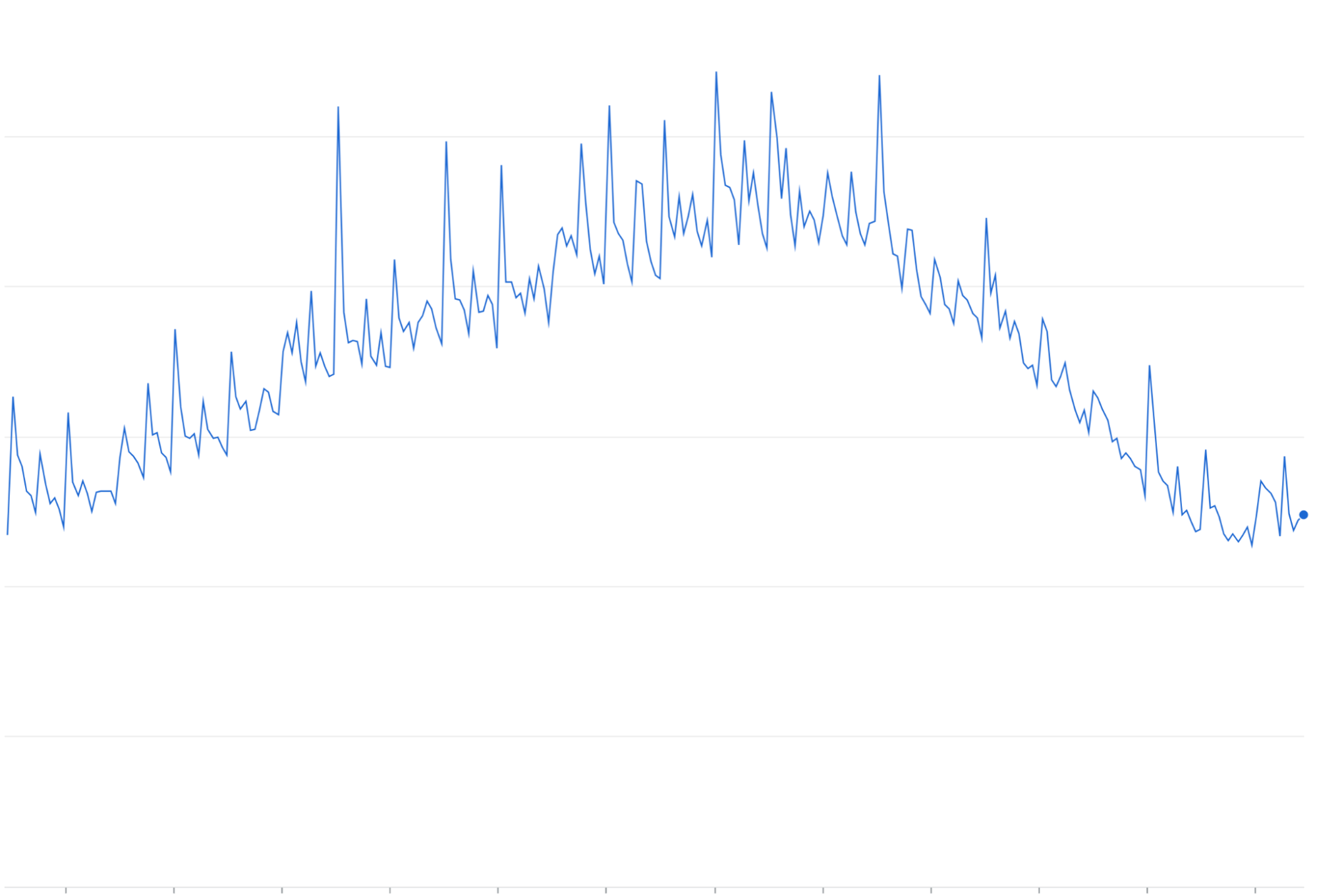
Wzrost liczby ponowień: ponawianie nieudanych lub przekraczających limit czasu żądań bez wzrastającego czasu do ponowienia może powodować powtarzające się fale ruchu na szczytach istniejącego ruchu.
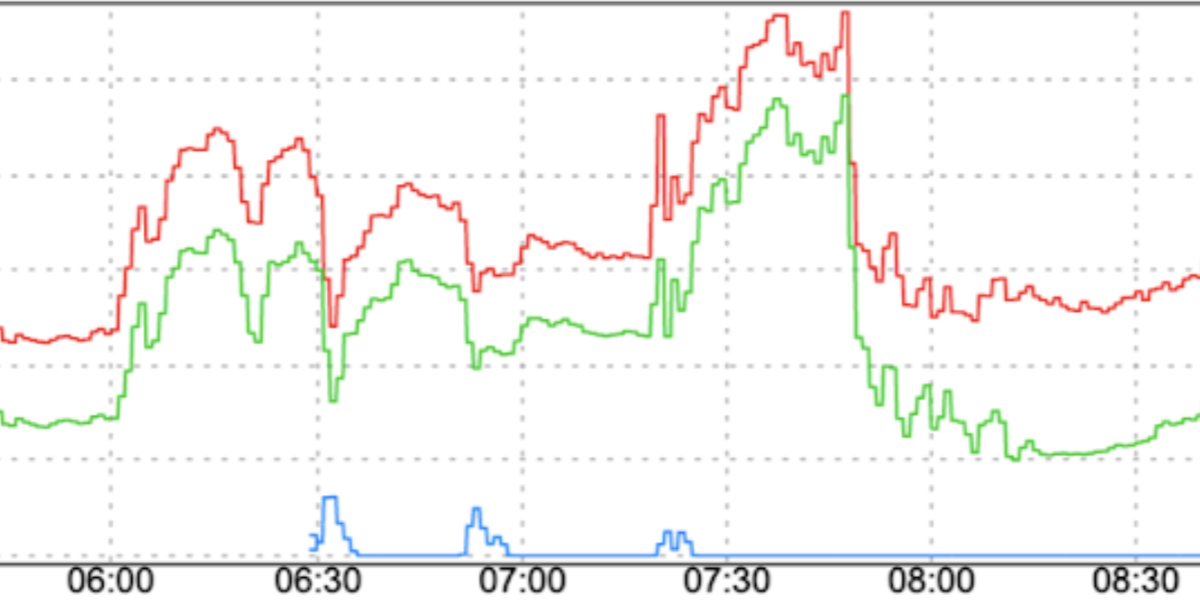
Nagłe zmiany wzorca ruchu: kierowanie nowego ruchu do FCM lub przenoszenie ruchu do FCM w różnych regionach bez czynników wygładzających, takich jak stopniowe zwiększanie, może powodować skoki.
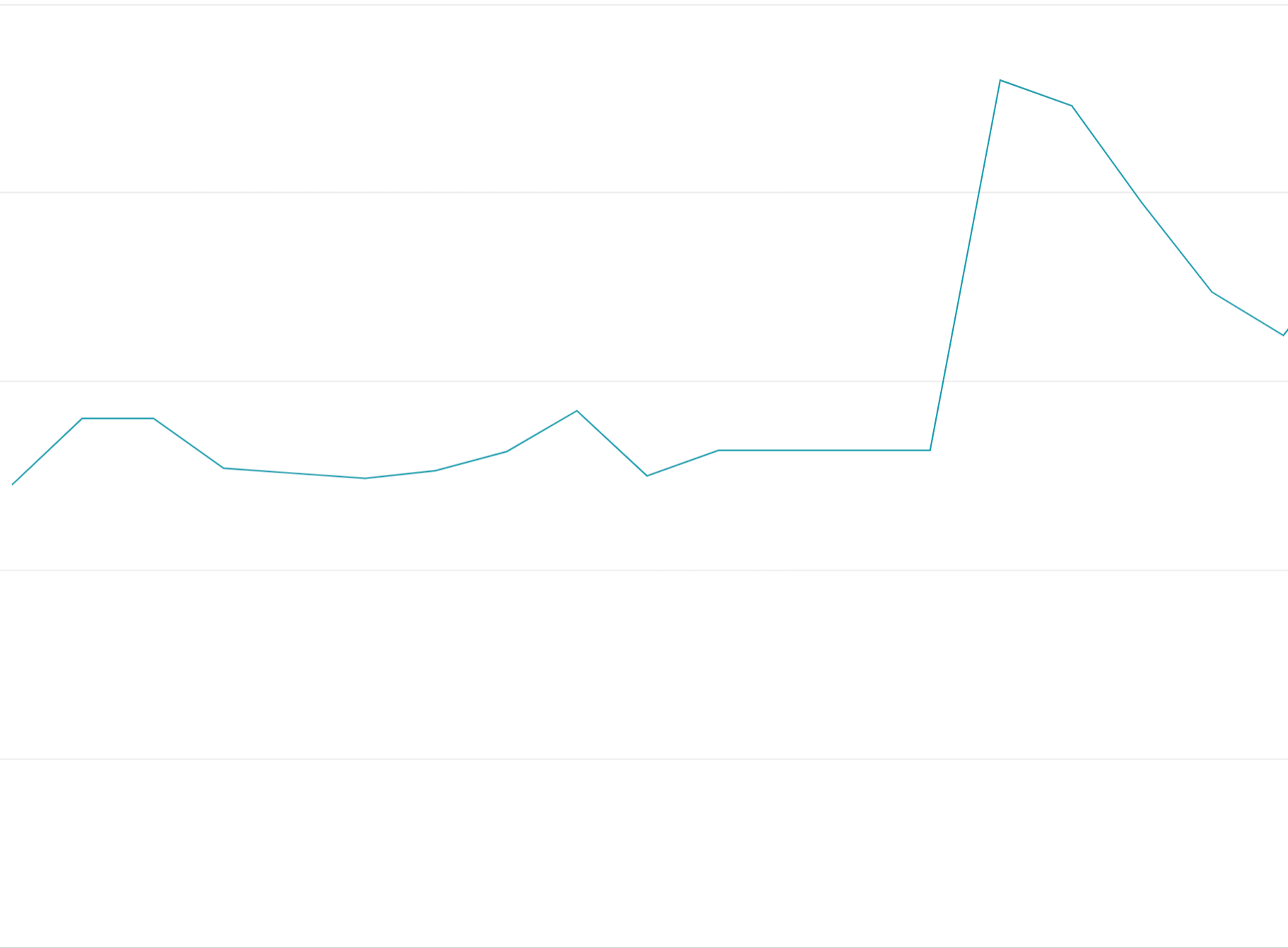
Wykorzystanie tokenów limitu z wyprzedzeniem: wyczerpanie wszystkich tokenów limitu na początku okien limitu zamiast równomiernego rozłożenia żądań w oknach limitu spowoduje oscylacje włączania i wyłączania, które są trudne i kosztowne do równoważenia obciążenia.
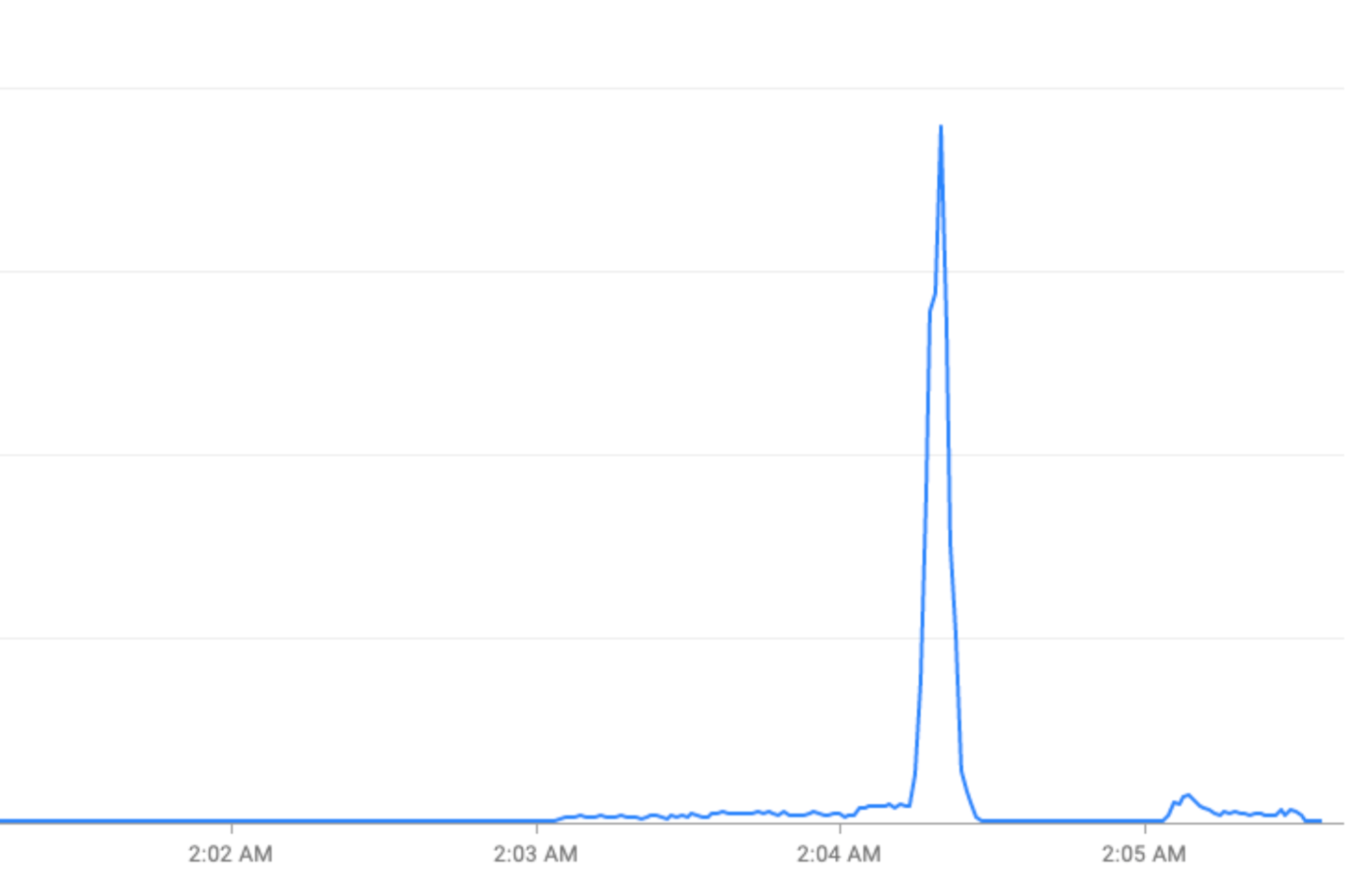
Wydarzenia specjalne: skoki natężenia ruchu podczas świąt (Sylwester) lub wydarzeń sportowych (Mistrzostwa Świata w Piłce Nożnej FIFA).
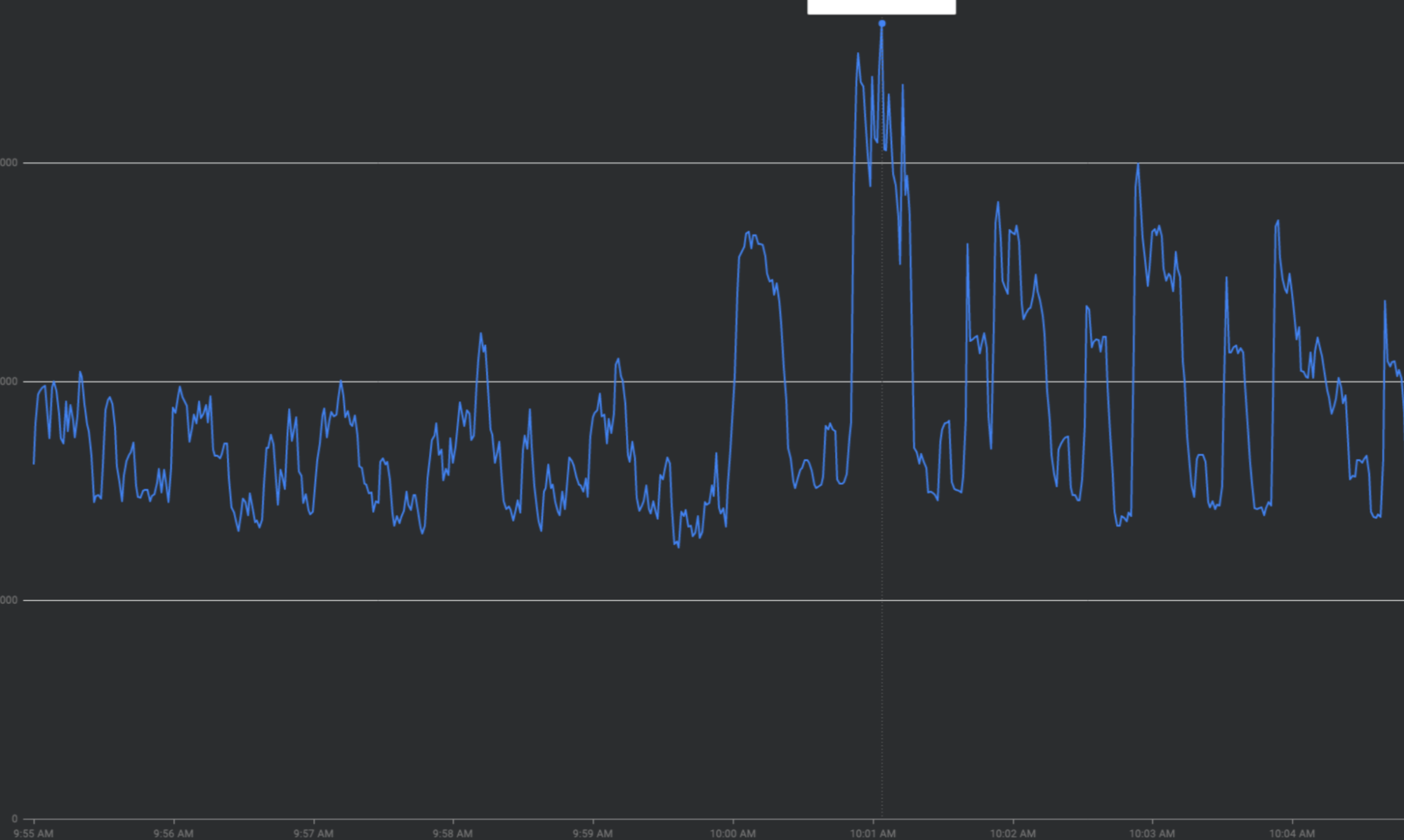
Zapobieganie skokom natężenia ruchu przez „spłaszczenie krzywej”
W tej sekcji opisujemy strategie wygładzania skoków natężenia ruchu, czyli „spłaszczania krzywej”.
Używaj FCM tylko w odpowiednich przypadkach
W niektórych przypadkach używanie FCM do dostarczania powiadomień nie jest konieczne ani odpowiednie.
Na przykład w przypadku powiadomień o wydarzeniach w kalendarzu możesz zaplanować lokalne zadanie w aplikacji, aby wyświetlać powiadomienia w odpowiednich momentach, zamiast wysyłać je z serwera aplikacji. Ogranicz wiadomości FCM do synchronizacji kalendarza.
Unikaj skoków
Jednym z anty-wzorców skalowania jest wysyłanie powiadomień FCM tak szybko, jak pozwalają na to systemy, zamiast stosowania ograniczania po stronie serwera. Zastanów się nad tym:
- Czy wszyscy Twoi klienci muszą otrzymać to samo powiadomienie w ciągu 1 minuty? Czy na przykład 5-minutowy przedział czasu dostawy nadal będzie spełniać Twoje potrzeby biznesowe?
- Czy można podzielić klientów na segmenty według priorytetu, aby wygładzić skoki?
- Czy powiadomienia można zaplanować z wyprzedzeniem?
Jeśli to możliwe: unikaj strategii, które powodują natychmiastowe wyczerpanie limitu wysyłania FCM, a następnie powtarzanie tego wzorca, gdy tylko zasobnik tokenów się napełni. Ten wzorzec dostępu powoduje problemy z równoważeniem obciążenia w FCM i jego systemach zależnych. Zwiększaj natężenie ruchu tak stopniowo, jak to możliwe. Zwiększaj natężenie ruchu od 0 do maksymalnej liczby żądań na sekundę w ciągu co najmniej 60 sekund. W przypadku większej liczby żądań na sekundę preferuj dłuższe przedziały czasu.
Unikaj ruchu o pełnej godzinie
Jeśli to możliwe: unikaj wysyłania wiadomości w ciągu 2 minut od każdej z godzin :00, :15, :30 i :45.
Wdrażanie ograniczania po stronie serwera
Wdróż ograniczanie po stronie serwera, aby monitorować ruch do FCM i nim zarządzać.
Obsługa ponawiania prób
Chociaż FCM dąży do wysokiej dostępności, czasami niektóre żądania przekroczą limit czasu lub nie powiodą się. Przyczyny mogą być różne, ale te sprawdzone metody optymalizują zachowanie ponawiania prób, aby dostarczać wiadomości tak szybko, jak to możliwe, przy jednoczesnym minimalizowaniu wpływu na zatory.
Czasy oczekiwania
Przed ponowieniem próby ustaw co najmniej 10-sekundowy limit czasu oczekiwania na żądania wysyłania. Większość wewnętrznych zdalnych wywołań procedur FCM używa 10-sekundowego limitu czasu oczekiwania.
Błędy
- W przypadku błędów 400, 401, 403 i 404: przerwij i nie ponawiaj próby.
- W przypadku błędów 429: ponów próbę po odczekaniu czasu ustawionego w nagłówku retry-after. Jeśli nie ustawiono nagłówka retry-after, domyślnie ustaw 60 sekund.
- W przypadku błędów 500: ponów próbę ze wzrastającym czasem do ponowienia.
Wzrastający czas do ponowienia
Aby uniknąć wzrostu liczby ponowień, wdróż wzrastający czas do ponowienia z jitteringiem w przypadku ponawiania żądań. Na przykład pakiet Firebase Admin SDK implementuje wzrastający czas do ponowienia.
Oto kilka dodatkowych zalecanych ustawień:
- Minimalny odstęp czasu: nie ponawiaj natychmiast nieudanego żądania w FCM. Przed ponowieniem nieudanego żądania odczekaj co najmniej 10 sekund.
- Maksymalny interwał: ustaw maksymalny interwał, aby odrzucać żądania, które nie są już aktualne, zamiast ponawiać je w nieskończoność.
Jeśli żądanie jest ciągle ponawiane ze wzrastającym czasem do ponowienia i nadal nie powodzi się po 60 minutach, oznacza to, że jest ono błędnie sklasyfikowane jako błąd, który można ponowić, lub że FCM ma awarię, w której ponawianie prób może nieumyślnie pogarszać sytuację.
Tworzenie planów wdrażania i wycofywania oraz wprowadzanie stopniowych zmian
W przypadku wprowadzania zmian w ruchu na dużą skalę, takich jak zwiększanie ruchu do FCM lub przenoszenie ruchu między regionami lub sieciami, opracowanie planu wdrażania lub wycofywania oraz wprowadzanie stopniowych zmian ochroni Twoich użytkowników, Twoją usługę i FCM.
- Plan wdrażania dostosowuje oczekiwania zainteresowanych stron. W niektórych sytuacjach (opisanych poniżej) warto wcześniej udostępnić plan wdrażania zespołowi FCM, aby uniknąć niespodzianek.
- Plan wycofywania pozwala uwzględnić nieprzewidziane sytuacje i przygotować mechanizmy szybkiego i bezpiecznego przywracania po nieoczekiwanych awariach.
- Wprowadzanie stopniowych zmian ma 2 aspekty:
- Stopniowe zwiększanie: kroki powinny być następujące: 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% lub dokładniejsze. "Wsiąka" (obserwuj zachowanie systemu pod obciążeniem) każdy krok przez 1 dzień do 1 tygodnia. Pozwala to wykryć potencjalne problemy przed kolejnym „krokiem”.
- Stopniowe zwiększanie natężenia ruchu: podczas każdego „kroku” zwiększania natężenia ruchu wygładź ruch w ciągu co najmniej godziny. Pozwala to infrastrukturze równoważenia obciążenia FCM odpowiednio skalować nowy ruch przy jednoczesnym minimalizowaniu potencjału występowania hotspotów i zatorów.
Oto hipotetyczny scenariusz migracji 500 tys. żądań na sekundę na całym świecie z interfejsu FCM Legacy HTTP API do interfejsu FCM HTTP v1 API:
| Tydzień | Krok | Strategia stopniowego zwiększania |
|---|---|---|
| 0 | Zwiększenie o 1% | Stopniowo zwiększaj natężenie ruchu od 0 do 5 tys. żądań na sekundę w interfejsie FCM HTTP v1 w ciągu godziny. |
| 1 | Zwiększenie o 5% | Stopniowo zwiększaj natężenie ruchu od 5 tys. do 25 tys. żądań na sekundę w ciągu 2 godzin. |
| 2 | Zwiększenie o 10% | Stopniowo zwiększaj natężenie ruchu od 25 tys. do 50 tys. żądań na sekundę w ciągu 2 godzin. |
| 3 | Zwiększenie o 25% | Zwiększaj natężenie ruchu od 50 tys. do 125 tys. żądań na sekundę w ciągu 3 godzin. |
| 4 | Zwiększenie o 50% | Zwiększaj natężenie ruchu od 125 tys. do 250 tys. żądań na sekundę w ciągu 6 godzin. |
| 5 | Zwiększenie o 75% | Zwiększaj natężenie ruchu od 250 tys. do 375 tys. żądań na sekundę w ciągu 6 godzin. |
| 6 | Zwiększenie o 100% | Zwiększaj natężenie ruchu od 375 tys. do 500 tys. żądań na sekundę w ciągu 6 godzin. |
Hipotetyczny plan wycofywania:
- Jeśli opóźnienie na poziomie 95 percentyla wzrośnie do ponad 500 ms lub jeśli współczynnik błędów przekroczy 1% przez ponad godzinę na dowolnym etapie, użyj konfiguracji dynamicznej, aby natychmiast wycofać zmiany do poprzedniego kroku.
- Kontynuuj wycofywanie do wcześniejszych kroków, aż opóźnienie i współczynnik błędów wrócą do normalnych poziomów.
Kiedy skontaktować się z FCM
Skontaktuj się z FCM za pomocą zespołu pomocy Firebase , jeśli:
- domyślne limity nie są już odpowiednie dla Twojego przypadku użycia;
- zmieniasz wzorce wysyłania w ciągu 3 miesięcy w skali 100 tys. żądań na sekundę na całym świecie lub 30 tys. żądań na sekundę na kontynencie.