
برای تصمیمگیری آگاهانه در مورد معماری برنامههای خود برای عملکرد و قابلیت اطمینان بالا، این سند را مطالعه کنید. این سند شامل مباحث پیشرفته Cloud Firestore است. اگر تازه کار با Cloud Firestore را شروع کردهاید، به جای آن به راهنمای شروع سریع مراجعه کنید.
Cloud Firestore یک پایگاه داده انعطافپذیر و مقیاسپذیر برای توسعه دستگاههای تلفن همراه، وب و سرور از فایربیس و Google Cloud است. شروع کار با Cloud Firestore و نوشتن برنامههای غنی و قدرتمند بسیار آسان است.
برای اطمینان از اینکه برنامههای شما با افزایش اندازه پایگاه داده و ترافیک، همچنان به خوبی عمل میکنند، درک مکانیسم خواندن و نوشتن در بکاند Cloud Firestore مفید است. همچنین باید تعامل خواندن و نوشتن خود را با لایه ذخیرهسازی و محدودیتهای اساسی که ممکن است بر عملکرد تأثیر بگذارند، درک کنید.
برای بهترین شیوهها قبل از معماری برنامه خود، به بخشهای زیر مراجعه کنید.
درک کامپوننتهای سطح بالا
نمودار زیر اجزای سطح بالای دخیل در یک درخواست API Cloud Firestore را نشان میدهد.
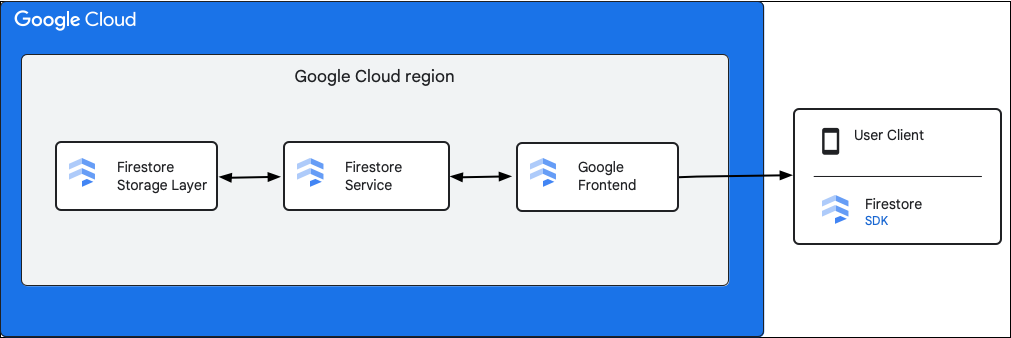
SDK و کتابخانههای کلاینت Cloud Firestore
Cloud Firestore از SDKها و کتابخانههای کلاینت برای پلتفرمهای مختلف پشتیبانی میکند. در حالی که یک برنامه میتواند مستقیماً از طریق HTTP و RPC به API Cloud Firestore فراخوانی کند، کتابخانههای کلاینت لایهای از انتزاع را برای سادهسازی استفاده از API و پیادهسازی بهترین شیوهها فراهم میکنند. آنها همچنین ممکن است ویژگیهای اضافی مانند دسترسی آفلاین، حافظههای پنهان و غیره را ارائه دهند.
رابط کاربری گوگل (GFE)
این یک سرویس زیرساختی مشترک برای همه سرویسهای ابری گوگل است. GFE درخواستهای ورودی را میپذیرد و آنها را به سرویس مربوطه گوگل (در این زمینه سرویس Cloud Firestore ) ارسال میکند. همچنین قابلیتهای مهم دیگری از جمله محافظت در برابر حملات انکار سرویس (Denial of Service) را نیز ارائه میدهد.
سرویس Cloud Firestore
سرویس Cloud Firestore بررسیهایی را روی درخواست API انجام میدهد که شامل احراز هویت، مجوز، بررسی سهمیه و قوانین امنیتی است و همچنین تراکنشها را مدیریت میکند. این سرویس Cloud Firestore شامل یک کلاینت ذخیرهسازی است که با لایه ذخیرهسازی برای خواندن و نوشتن دادهها تعامل دارد.
لایه ذخیرهسازی Cloud Firestore
لایه ذخیرهسازی Cloud Firestore مسئول ذخیرهسازی دادهها و فرادادهها و ویژگیهای پایگاه داده مرتبط ارائه شده توسط Cloud Firestore است. بخشهای زیر نحوه سازماندهی دادهها در لایه ذخیرهسازی Cloud Firestore و نحوه مقیاسپذیری سیستم را شرح میدهند. یادگیری در مورد نحوه سازماندهی دادهها میتواند به شما در طراحی یک مدل داده مقیاسپذیر و درک بهتر بهترین شیوهها در Cloud Firestore کمک کند.
محدودههای کلیدی و تقسیمبندیها
Cloud Firestore یک پایگاه داده NoSQL و سندگرا است. شما دادهها را در اسناد ذخیره میکنید که در سلسله مراتبی از مجموعهها سازماندهی شدهاند. سلسله مراتب مجموعه و شناسه سند برای هر سند به یک کلید واحد ترجمه میشوند. اسناد به صورت منطقی ذخیره میشوند و توسط این کلید واحد از نظر لغوی مرتب میشوند. ما از اصطلاح محدوده کلید برای اشاره به محدودهای از کلیدها که از نظر لغوی به هم پیوسته هستند، استفاده میکنیم.
یک پایگاه داده معمولی Cloud Firestore برای قرار گرفتن در یک ماشین فیزیکی واحد بسیار بزرگ است. همچنین سناریوهایی وجود دارد که حجم کار روی دادهها برای یک ماشین بسیار سنگین است. برای مدیریت حجمهای کاری بزرگ، Cloud Firestore دادهها را به قطعات جداگانهای تقسیم میکند که میتوانند روی چندین ماشین یا سرورهای ذخیرهسازی ذخیره و از آنها سرویسدهی شوند. این تقسیمبندیها در جداول پایگاه داده در بلوکهایی از محدودههای کلیدی به نام Splits ساخته میشوند.
تکثیر همزمان
لازم به ذکر است که پایگاه داده همیشه به صورت خودکار و همزمان در حال تکثیر است. بخشهای داده دارای کپیهایی در مناطق مختلف هستند تا حتی زمانی که یک منطقه غیرقابل دسترسی میشود، در دسترس باشند. تکثیر مداوم به نسخههای مختلف تقسیمبندی توسط الگوریتم Paxos برای اجماع مدیریت میشود. یک کپی از هر تقسیمبندی به عنوان رهبر Paxos انتخاب میشود که مسئول مدیریت نوشتنها در آن تقسیمبندی است. تکثیر همزمان به شما این امکان را میدهد که همیشه بتوانید آخرین نسخه دادهها را از Cloud Firestore بخوانید.
نتیجه کلی این امر، یک سیستم مقیاسپذیر و با دسترسیپذیری بالا است که صرف نظر از حجم کاری سنگین و در مقیاس بسیار بزرگ، تأخیر کمی را برای خواندن و نوشتن فراهم میکند.
طرح داده
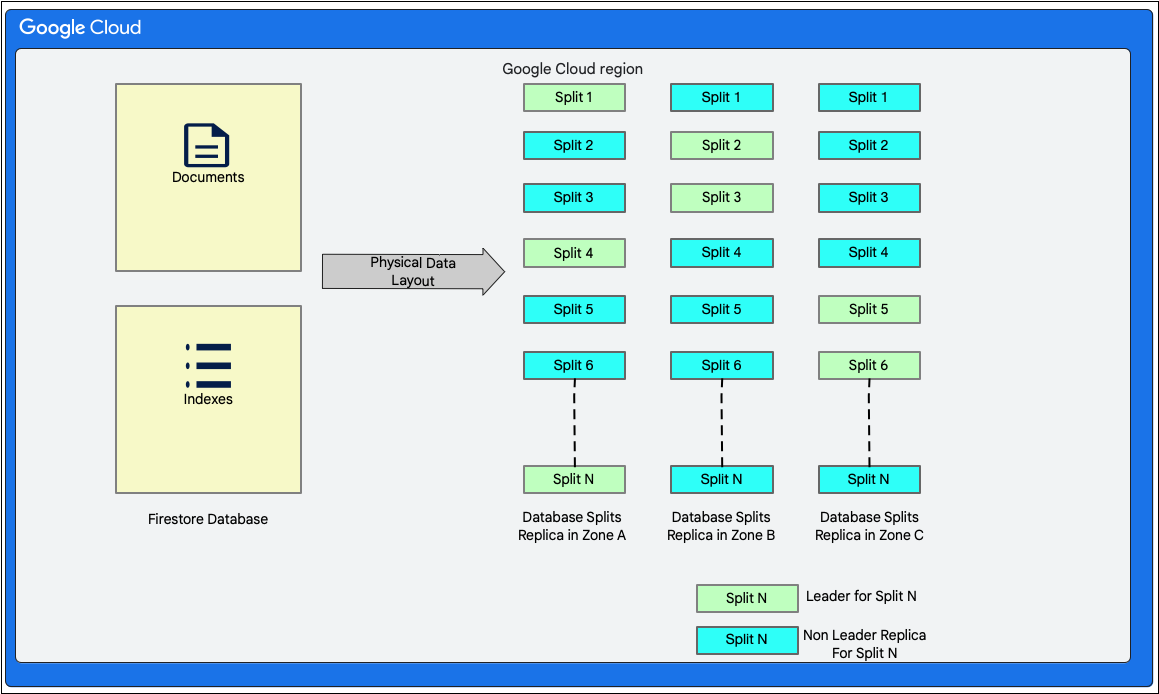
Cloud Firestore یک پایگاه داده سند بدون طرح است. با این حال، از نظر داخلی، دادهها را عمدتاً در دو جدول به سبک پایگاه داده رابطهای در لایه ذخیرهسازی خود به شرح زیر قرار میدهد:
- جدول اسناد : اسناد در این جدول ذخیره میشوند.
- جدول شاخصها : ورودیهای شاخص که امکان دستیابی کارآمد به نتایج را فراهم میکنند و بر اساس مقدار شاخص مرتب شدهاند، در این جدول ذخیره میشوند.
نمودار زیر نشان میدهد که جداول یک پایگاه داده Cloud Firestore با تقسیمبندیها چگونه ممکن است به نظر برسند. تقسیمبندیها در سه منطقه مختلف تکرار میشوند و هر تقسیمبندی یک رهبر Paxos اختصاص داده شده دارد.
تک منطقهای در مقابل چند منطقهای
هنگام ایجاد یک پایگاه داده، باید یک منطقه یا چند منطقه را انتخاب کنید.
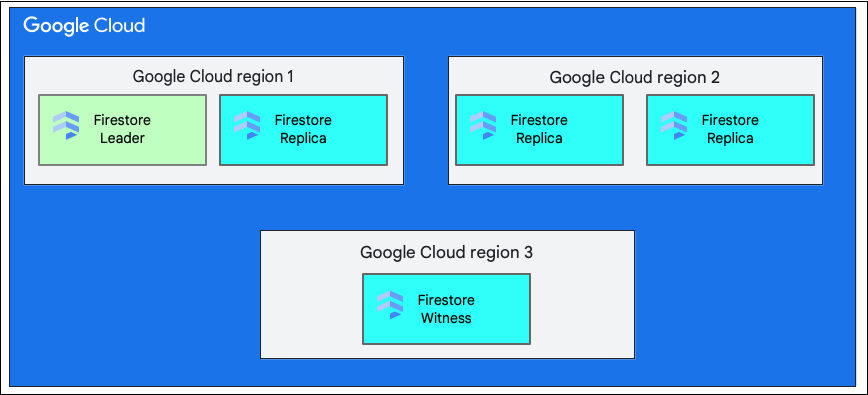
یک موقعیت منطقهای واحد، یک موقعیت جغرافیایی خاص است، مانند us-west1 . همانطور که قبلاً توضیح داده شد، بخشهای مختلف دادههای یک پایگاه داده Cloud Firestore دارای کپیهایی در مناطق مختلف در منطقه انتخاب شده هستند.
یک مکان چند منطقهای شامل مجموعهای تعریفشده از مناطق است که در آنها کپیهای پایگاه داده ذخیره میشوند. در یک استقرار چند منطقهای از Cloud Firestore ، دو منطقه دارای کپیهای کاملی از کل دادهها در پایگاه داده هستند. منطقه سوم دارای یک کپی شاهد است که مجموعه کاملی از دادهها را نگهداری نمیکند، اما در تکثیر شرکت میکند. با تکثیر دادهها بین چندین منطقه، دادهها حتی با از دست دادن کل یک منطقه، برای نوشتن و خواندن در دسترس هستند.
برای اطلاعات بیشتر در مورد مکانهای یک منطقه، به مکانهای Cloud Firestore مراجعه کنید.
زندگی یک نویسنده در Cloud Firestore را درک کنید
یک کلاینت Cloud Firestore میتواند با ایجاد، بهروزرسانی یا حذف یک سند واحد، دادهها را بنویسد. نوشتن در یک سند واحد مستلزم بهروزرسانی خودکار سند و ورودیهای شاخص مرتبط با آن در لایه ذخیرهسازی است. Cloud Firestore همچنین از عملیات خودکار شامل خواندن و/یا نوشتن چندگانه در یک یا چند سند پشتیبانی میکند.
برای انواع نوشتن، Cloud Firestore ویژگیهای ACID (اتمیک بودن، سازگاری، ایزوله بودن و دوام) پایگاههای داده رابطهای را ارائه میدهد. Cloud Firestore همچنین قابلیت سریالسازی را فراهم میکند، به این معنی که همه تراکنشها طوری به نظر میرسند که گویی به ترتیب سریالی اجرا میشوند.
مراحل سطح بالا در یک تراکنش نوشتن
وقتی کلاینت Cloud Firestore با استفاده از هر یک از روشهای ذکر شده قبلی، یک تراکنش write یا commit صادر میکند، این تراکنش به صورت داخلی به عنوان یک تراکنش read-write پایگاه داده در لایه ذخیرهسازی اجرا میشود. این تراکنش Cloud Firestore را قادر میسازد تا ویژگیهای ACID ذکر شده قبلی را ارائه دهد.
به عنوان اولین مرحله از یک تراکنش، Cloud Firestore سند موجود را میخواند و جهشهایی را که باید در دادههای جدول Documents ایجاد شود، تعیین میکند.
این همچنین شامل انجام بهروزرسانیهای لازم در جدول Indexes به شرح زیر است:
- فیلدهایی که به اسناد اضافه میشوند، نیاز به درجهای مربوطه در جدول Indexes دارند.
- فیلدهایی که از اسناد حذف میشوند، نیاز به حذفهای متناظر در جدول شاخصها دارند.
- فیلدهایی که در اسناد تغییر میکنند، نیاز به حذف (برای مقادیر قدیمی) و درج (برای مقادیر جدید) در جدول شاخصها دارند.
برای محاسبه جهشهای ذکر شده در بالا، Cloud Firestore پیکربندی نمایهسازی پروژه را میخواند. پیکربندی نمایهسازی اطلاعات مربوط به نمایههای یک پروژه را ذخیره میکند. Cloud Firestore از دو نوع نمایه استفاده میکند: تک فیلدی و مرکب. برای درک دقیق نمایههای ایجاد شده در Cloud Firestore ، به بخش انواع نمایه در Cloud Firestore مراجعه کنید.
پس از محاسبه جهشها، Cloud Firestore آنها را درون یک تراکنش جمعآوری کرده و سپس آن را ثبت میکند.
درک تراکنش نوشتن در لایه ذخیرهسازی
همانطور که قبلاً بحث شد، نوشتن در Cloud Firestore شامل یک تراکنش خواندن-نوشتن در لایه ذخیرهسازی است. بسته به چیدمان دادهها، یک نوشتن ممکن است شامل یک یا چند تقسیمبندی باشد، همانطور که در چیدمان دادهها مشاهده میشود.
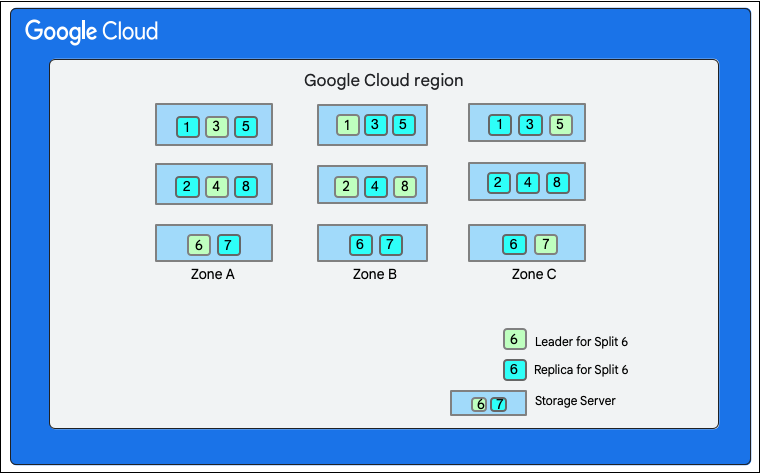
در نمودار زیر، پایگاه داده Cloud Firestore دارای هشت بخش (با علامتهای ۱ تا ۸) است که در سه سرور ذخیرهسازی مختلف در یک منطقه واحد میزبانی میشوند و هر بخش در ۳ (یا بیشتر) منطقه مختلف تکثیر میشود. هر بخش دارای یک رهبر Paxos است که ممکن است برای بخشهای مختلف در منطقه متفاوتی باشد.
 تقسیم پایگاه داده Cloud Firestore">
تقسیم پایگاه داده Cloud Firestore">
یک پایگاه داده Cloud Firestore را در نظر بگیرید که مجموعه Restaurants را به صورت زیر دارد:
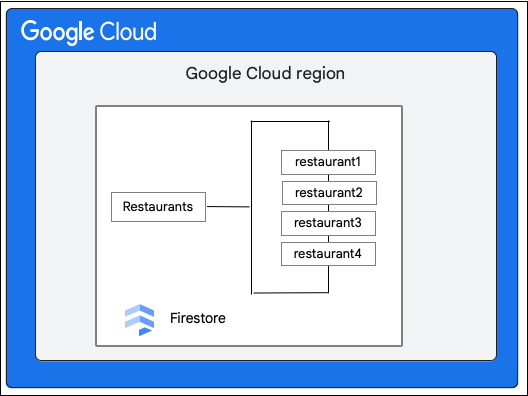
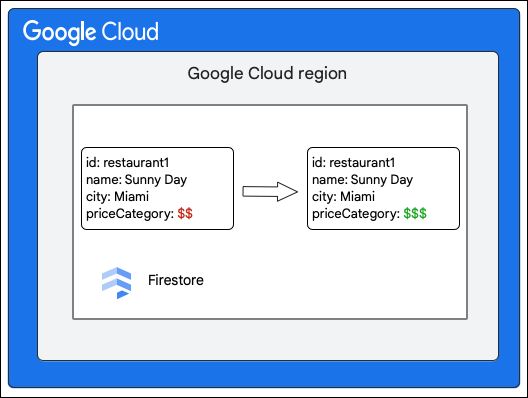
کلاینت Cloud Firestore با بهروزرسانی مقدار فیلد priceCategory ، تغییر زیر را در سندی در مجموعه Restaurant درخواست میکند.
مراحل سطح بالای زیر، آنچه را که به عنوان بخشی از نوشتن اتفاق میافتد، شرح میدهند:
- یک تراکنش خواندن-نوشتن ایجاد کنید.
- سند
restaurant1را در مجموعهRestaurantsاز جدول Documents از لایه ذخیرهسازی بخوانید. - شاخصهای سند را از جدول شاخصها (Indexes) بخوانید.
- جهشهایی که باید روی دادهها اعمال شوند را محاسبه کنید. در این مورد، پنج جهش وجود دارد:
- M1: سطر مربوط به
restaurant1در جدول Documents را بهروزرسانی کن تا تغییر مقدار فیلدpriceCategoryرا منعکس کند. - M2 و M3: سطرهای مربوط به مقدار قدیمی
priceCategoryرا در جدول Indexes برای شاخصهای نزولی و صعودی حذف کنید. - M4 و M5: ردیفهای مربوط به مقدار جدید
priceCategoryرا در جدول Indexes برای شاخصهای نزولی و صعودی وارد کنید.
- M1: سطر مربوط به
- این جهشها را مرتکب شوید.
کلاینت ذخیرهسازی در سرویس Cloud Firestore به دنبال تقسیمبندیهایی میگردد که کلیدهای ردیفهایی که باید تغییر کنند را در اختیار دارند. بیایید حالتی را در نظر بگیریم که تقسیمبندی ۳ به M1 و تقسیمبندی ۶ به M2-M5 سرویس میدهد. یک تراکنش توزیعشده وجود دارد که شامل همه این تقسیمبندیها به عنوان شرکتکننده است. تقسیمبندیهای شرکتکننده همچنین ممکن است شامل هر تقسیمبندی دیگری باشد که دادهها قبلاً به عنوان بخشی از تراکنش خواندن-نوشتن از آن خوانده شدهاند.
مراحل زیر آنچه را که به عنوان بخشی از کامیت اتفاق میافتد، شرح میدهد:
- کلاینت ذخیرهسازی یک کامیت صادر میکند. این کامیت شامل جهشهای M1 تا M5 است.
- بخشهای ۳ و ۶، شرکتکنندگان این تراکنش هستند. یکی از شرکتکنندگان به عنوان هماهنگکننده انتخاب میشود، مانند بخش ۳. وظیفه هماهنگکننده این است که مطمئن شود تراکنش به صورت خودکار در بین همه شرکتکنندگان انجام میشود یا لغو میگردد.
- رهبران کپیشده از این تقسیمبندیها، مسئول کارهایی هستند که توسط شرکتکنندگان و هماهنگکنندگان انجام میشود.
- هر شرکتکننده و هماهنگکننده، یک الگوریتم Paxos را با کپیهای مربوط به خود اجرا میکند.
- رهبر الگوریتم Paxos را با کپیها اجرا میکند. اگر اکثر کپیها با
ok to commitحد نصاب حاصل میشود. - سپس هر شرکتکننده وقتی آماده شد ، هماهنگکننده را مطلع میکند (مرحله اول از تایید دو مرحلهای). اگر هر شرکتکنندهای نتواند تراکنش را تایید کند، کل تراکنش
aborts.
- رهبر الگوریتم Paxos را با کپیها اجرا میکند. اگر اکثر کپیها با
- زمانی که هماهنگکننده از آمادگی همه شرکتکنندگان، از جمله خودش، مطلع شد، نتیجه
acceptتراکنش را به همه شرکتکنندگان اطلاع میدهد (مرحله دوم از تایید دو مرحلهای). در این مرحله، هر شرکتکننده تصمیم تایید را در حافظه پایدار ثبت میکند و تراکنش تایید میشود. - هماهنگکننده به کلاینت ذخیرهسازی در Cloud Firestore پاسخ میدهد که تراکنش انجام شده است. به طور موازی، هماهنگکننده و همه شرکتکنندگان جهشها را روی دادهها اعمال میکنند.
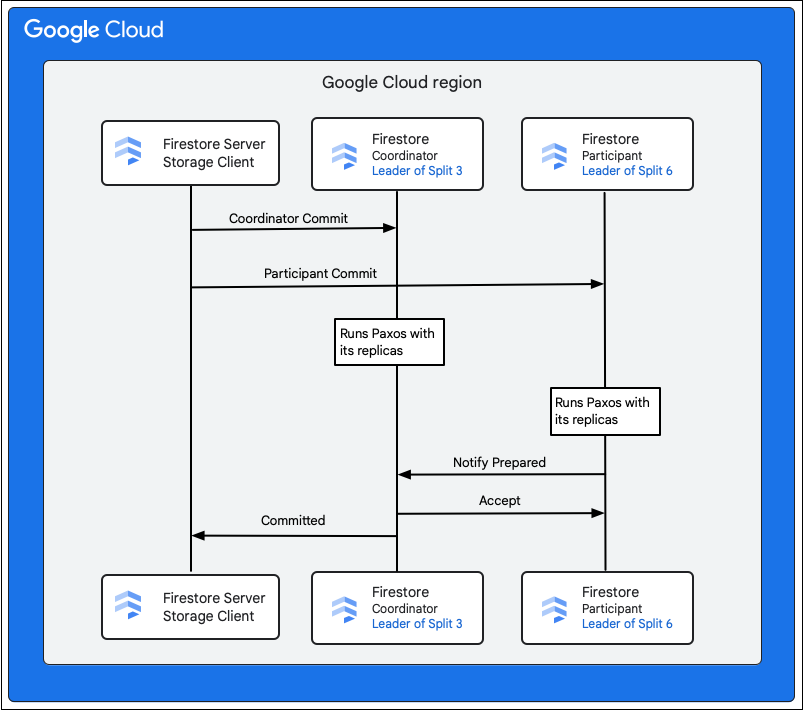
وقتی پایگاه داده Cloud Firestore کوچک باشد، ممکن است اتفاق بیفتد که یک تقسیم واحد، تمام کلیدها را در جهشهای M1-M5 در اختیار داشته باشد. در چنین حالتی، فقط یک شرکتکننده در تراکنش وجود دارد و کامیت دو مرحلهای که قبلاً ذکر شد، لازم نیست، بنابراین نوشتنها سریعتر انجام میشوند.
در چند منطقه مینویسد
در یک استقرار چند منطقهای، گسترش کپیها در مناطق مختلف، دسترسیپذیری را افزایش میدهد، اما با هزینه عملکرد همراه است. ارتباط بین کپیها در مناطق مختلف، زمان رفت و برگشت طولانیتری طول میکشد. از این رو، تأخیر پایه برای عملیات Cloud Firestore در مقایسه با استقرارهای تک منطقهای کمی بیشتر است.
ما کپیها را به گونهای پیکربندی میکنیم که رهبری برای تقسیمبندیها همیشه در منطقه اصلی باقی بماند. منطقه اصلی، منطقهای است که ترافیک از آن به سرور Cloud Firestore وارد میشود. این تصمیم رهبری، تأخیر رفت و برگشت در ارتباط بین کلاینت ذخیرهسازی در Cloud Firestore و رهبر کپی (یا هماهنگکننده برای تراکنشهای چند تقسیمی) را کاهش میدهد.
هر نوشتن در Cloud Firestore همچنین شامل تعامل با موتور بلادرنگ در Cloud Firestore است. برای اطلاعات بیشتر در مورد پرسوجوهای بلادرنگ، به درک پرسوجوهای بلادرنگ در مقیاس مراجعه کنید.
زندگی یک خواننده را در Cloud Firestore درک کنید
این بخش به بررسی خواندنهای مستقل و غیر بلادرنگ در Cloud Firestore میپردازد. سرور Cloud Firestore به صورت داخلی اکثر این کوئریها را در دو مرحله اصلی مدیریت میکند:
- یک اسکن تک محدودهای روی جدول ایندکسها
- جستجوهای نقطهای در جدول اسناد بر اساس نتیجه اسکن قبلی
خواندن دادهها از لایه ذخیرهسازی به صورت داخلی با استفاده از یک تراکنش پایگاه داده انجام میشود تا از خواندنهای مداوم اطمینان حاصل شود. با این حال، برخلاف تراکنشهای مورد استفاده برای نوشتن، این تراکنشها قفل نمیگیرند. در عوض، آنها با انتخاب یک برچسب زمانی و سپس اجرای همه خواندنها در آن برچسب زمانی کار میکنند. از آنجایی که آنها قفلی دریافت نمیکنند، تراکنشهای خواندن-نوشتن همزمان را مسدود نمیکنند. برای اجرای این تراکنش، کلاینت ذخیرهسازی در Cloud Firestore یک محدوده برچسب زمانی را مشخص میکند که به لایه ذخیرهسازی میگوید چگونه یک برچسب زمانی خواندن را انتخاب کند. نوع محدوده برچسب زمانی انتخاب شده توسط کلاینت ذخیرهسازی در Cloud Firestore توسط گزینههای خواندن برای درخواست خواندن تعیین میشود.
درک تراکنش خواندن در لایه ذخیرهسازی
این بخش انواع خواندنها و نحوه پردازش آنها در لایه ذخیرهسازی در Cloud Firestore را شرح میدهد.
خوانشهای قوی
به طور پیشفرض، خواندنهای Cloud Firestore کاملاً سازگار هستند. این سازگاری قوی به این معنی است که یک خواندن Cloud Firestore آخرین نسخه از دادهها را برمیگرداند که منعکس کننده تمام نوشتنهایی است که تا شروع خواندن انجام شدهاند.
خواندن تکی و تقسیم شده
کلاینت ذخیرهسازی در Cloud Firestore به دنبال Splitهایی میگردد که کلیدهای سطرهای خوانده شده را در اختیار دارند. فرض کنید که نیاز به خواندن Split 3 از بخش قبلی دارد. کلاینت درخواست خواندن را به نزدیکترین replica ارسال میکند تا تأخیر رفت و برگشت را کاهش دهد.
در این مرحله، بسته به کپی انتخاب شده، موارد زیر ممکن است رخ دهد:
- درخواست خواندن به یک کپی از رهبر (منطقه A) میرود.
- از آنجایی که رهبر همیشه بهروز است، مطالعه میتواند مستقیماً ادامه یابد.
- درخواست خواندن به یک کپی غیر رهبر (مانند منطقه B) میرود.
- ممکن است Split 3 از طریق وضعیت داخلی خود بداند که اطلاعات کافی برای ارائه خدمات خواندن دارد و Split این کار را انجام میدهد.
- Split 3 مطمئن نیست که آیا آخرین دادهها را دیده است یا خیر. پیامی به Leader میفرستد تا مهر زمانی آخرین تراکنشی را که برای ارائه خواندن نیاز دارد، درخواست کند. پس از اعمال آن تراکنش، خواندن میتواند ادامه یابد.
سپس Cloud Firestore پاسخ را به کلاینت خود برمیگرداند.
خواندن چند قسمتی
در شرایطی که خواندنها باید از چندین تقسیمبندی انجام شوند، همین مکانیزم در تمام تقسیمبندیها اتفاق میافتد. پس از بازگشت دادهها از تمام تقسیمبندیها، کلاینت ذخیرهسازی در Cloud Firestore نتایج را ترکیب میکند. سپس Cloud Firestore با این دادهها به کلاینت خود پاسخ میدهد.
خواندنهای تکراری
خواندن قوی حالت پیشفرض در Cloud Firestore است. با این حال، به دلیل ارتباطی که ممکن است با رهبر مورد نیاز باشد، هزینه تأخیر بالقوه بالاتری دارد. اغلب برنامه Cloud Firestore شما نیازی به خواندن آخرین نسخه دادهها ندارد و این قابلیت با دادههایی که ممکن است چند ثانیه قدیمی باشند، به خوبی کار میکند.
در چنین حالتی، کلاینت میتواند با استفاده از گزینههای read_time read، خواندنهای قدیمی را دریافت کند. در این حالت، خواندنها به گونهای انجام میشوند که دادهها در read_time بودهاند و به احتمال زیاد نزدیکترین کپی، از قبل وجود دادهها در زمان read_time مشخص شده را تأیید کرده است. برای عملکرد به طور قابل توجهی بهتر، ۱۵ ثانیه یک مقدار قدیمی بودن معقول است. حتی برای خواندنهای قدیمی، ردیفهای ارائه شده با یکدیگر سازگار هستند.
از نقاط داغ دوری کنید
تقسیمبندیها در Cloud Firestore به طور خودکار به قطعات کوچکتری تقسیم میشوند تا در صورت نیاز یا زمانی که فضای کلید گسترش مییابد، کار ارائه ترافیک را به سرورهای ذخیرهسازی بیشتر توزیع کنند. تقسیمبندیهای ایجاد شده برای مدیریت ترافیک اضافی، حتی اگر ترافیک از بین برود، حدود ۲۴ ساعت حفظ میشوند. بنابراین اگر افزایش ناگهانی ترافیک وجود داشته باشد، تقسیمبندیها حفظ میشوند و هر زمان که لازم باشد، تقسیمبندیهای بیشتری معرفی میشوند. این مکانیسمها به پایگاههای داده Cloud Firestore کمک میکنند تا تحت بار ترافیکی یا اندازه پایگاه داده فزاینده، به طور خودکار مقیاسبندی شوند. با این حال، محدودیتهایی وجود دارد که باید از آنها آگاه باشید، همانطور که در زیر توضیح داده شده است.
تقسیم فضای ذخیرهسازی و بار زمان میبرد و افزایش سریع ترافیک ممکن است باعث تأخیر زیاد یا خطاهای فراتر از مهلت شود که معمولاً به عنوان نقاط حساس شناخته میشوند، در حالی که سرویس در حال تنظیم است. بهترین روش این است که عملیات را در سراسر محدوده کلیدی توزیع کنید، در حالی که ترافیک را روی یک مجموعه در پایگاه داده با ۵۰۰ عملیات در ثانیه افزایش میدهید. پس از این افزایش تدریجی، هر پنج دقیقه ترافیک را تا ۵۰٪ افزایش دهید. این فرآیند قانون ۵۰۰/۵۰/۵ نامیده میشود و پایگاه داده را در موقعیت مقیاسپذیری بهینه برای پاسخگویی به حجم کار شما قرار میدهد.
اگرچه تقسیمبندیها با افزایش بار به طور خودکار ایجاد میشوند، Cloud Firestore میتواند یک محدوده کلیدی را فقط تا زمانی که یک سند واحد را با استفاده از مجموعهای اختصاصی از سرورهای ذخیرهسازی تکثیر شده ارائه میدهد، تقسیم کند. در نتیجه، حجم زیاد و پایدار عملیات همزمان روی یک سند واحد ممکن است منجر به ایجاد یک نقطه اتصال (hotspot) در آن سند شود. اگر با تأخیرهای زیاد و پایدار در یک سند واحد مواجه شدید، باید اصلاح مدل داده خود را برای تقسیم یا تکثیر دادهها در چندین سند در نظر بگیرید.
خطاهای رقابتی زمانی اتفاق میافتند که چندین عملیات سعی میکنند همزمان یک سند را بخوانند و/یا بنویسند.
مورد خاص دیگری از هاتاسپاتینگ زمانی اتفاق میافتد که یک کلید به صورت متوالی افزایش/کاهش یابنده به عنوان شناسه سند در Cloud Firestore استفاده شود و تعداد عملیات در ثانیه به طور قابل توجهی بالا باشد. ایجاد تقسیمبندیهای بیشتر در اینجا کمکی نمیکند زیرا موج ترافیک به سادگی به تقسیمبندی تازه ایجاد شده منتقل میشود. از آنجایی که Cloud Firestore به طور خودکار تمام فیلدهای سند را به طور پیشفرض فهرستبندی میکند، چنین هاتاسپاتهای متحرکی نیز میتوانند در فضای فهرستبندی برای یک فیلد سند که حاوی مقداری به صورت متوالی افزایش/کاهش یابنده مانند یک مهر زمانی است، ایجاد شوند.
توجه داشته باشید که با پیروی از رویههای ذکر شده در بالا، Cloud Firestore میتواند بدون نیاز به تنظیم هیچ پیکربندی، برای ارائه حجم کاری دلخواه بزرگ، مقیاسپذیر باشد.
عیبیابی
Cloud Firestore ابزار Key Visualizer را به عنوان یک ابزار تشخیصی ارائه میدهد که برای تجزیه و تحلیل الگوهای استفاده و عیبیابی مشکلات هاتاسپات طراحی شده است.
قدم بعدی چیست؟
- درباره بهترین شیوههای بیشتر بخوانید
- درباره پرسوجوهای بلادرنگ در مقیاس بزرگ اطلاعات کسب کنید