
請詳閱本文,根據相關資訊做出明智決策,為應用程式設計高效能和高可靠性的架構。本文件包含進階Cloud Firestore主題。如果你才剛開始使用 Cloud Firestore,請參閱快速入門指南。
Cloud Firestore 是 Firebase 和 Google Cloud 提供的資料庫,具備彈性與擴充性,適用於行動裝置、網頁和伺服器開發。Cloud Firestore 容易上手,助您輕鬆打造功能豐富強大的應用程式。
為確保應用程式在資料庫大小和流量增加時,仍能維持良好效能,請瞭解 Cloud Firestore 後端的讀取和寫入機制。您也必須瞭解讀取和寫入作業與儲存層的互動,以及可能影響效能的基礎限制。
在設計應用程式架構前,請先參閱下列各節的最佳做法。
瞭解高階元件
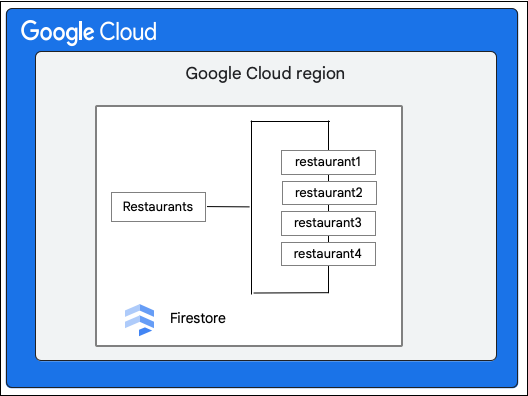
下圖顯示 Cloud Firestore API 要求涉及的高階元件。
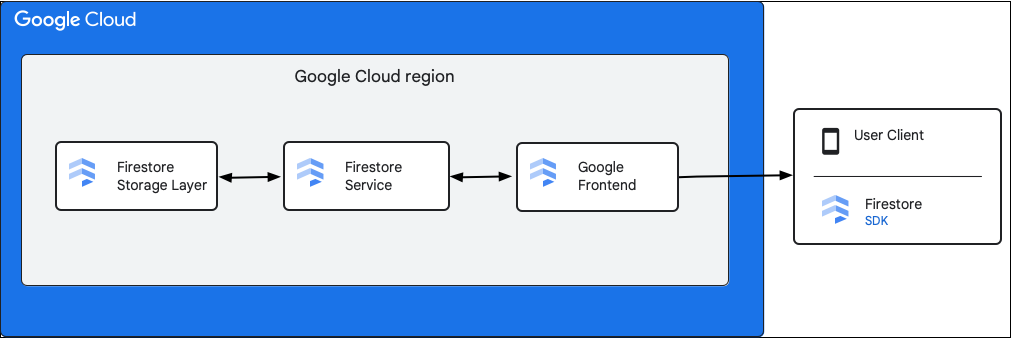
Cloud Firestore SDK 和用戶端程式庫
Cloud Firestore 支援不同平台的 SDK 和用戶端程式庫。雖然應用程式可以直接向 Cloud Firestore API 發出 HTTP 和 RPC 呼叫,但用戶端程式庫提供抽象層,可簡化 API 用法並實作最佳做法。也可能提供離線存取、快取等額外功能。
Google Front End (GFE)
這是所有 Google Cloud 服務共用的基礎架構服務。GFE 會接受傳入的要求,並轉送至相關的 Google 服務 (在本例中為 Cloud Firestore 服務)。同時提供其他重要功能,包括防範阻斷服務攻擊。
Cloud Firestore 項服務
Cloud Firestore 服務會檢查 API 要求,包括驗證、授權、配額檢查和安全性規則,並管理交易。這項 Cloud Firestore 服務包含儲存空間用戶端,可與儲存空間層互動,進行資料讀取和寫入作業。
Cloud Firestore 儲存層
Cloud Firestore 儲存層負責儲存資料和中繼資料,以及 Cloud Firestore 提供的相關資料庫功能。以下各節說明 Cloud Firestore 儲存層的資料結構,以及系統的擴充方式。瞭解資料的整理方式,有助於設計可擴充的資料模型,並進一步瞭解 Cloud Firestore 的最佳做法。
鍵範圍和分割
Cloud Firestore 是 NoSQL 文件導向資料庫。您可以在文件中儲存資料,並以集合階層的形式整理文件。系統會將集合階層和文件 ID 轉換為每個文件的單一鍵。文件會以這個單一鍵邏輯儲存,並依字母順序排序。我們使用「鍵範圍」一詞,指稱鍵的字典順序連續範圍。
一般的 Cloud Firestore 資料庫過大,無法放在單一實體機器上。也有一些情境是,資料工作負載太重,以至於單一機器無法處理。為處理大量工作負載,Cloud Firestore 會將資料分割成多個片段,然後儲存在多部機器或儲存伺服器,並從這些位置提供資料。這些分區是在資料庫資料表上以索引鍵範圍區塊 (稱為分割) 建立。
同步複製
請務必注意,資料庫一律會自動同步複製。資料分割區在不同區域中都有副本,即使某個區域無法存取,資料仍可使用。這樣一致地複製到分割的各個副本的作業是由 Paxos 演算法管理,以達成共識。每個分割區都會選出一個備用資源做為 Paxos 領導者,負責處理該分割區的寫入作業。同步複製功能可讓您隨時從 Cloud Firestore 讀取最新版本的資料。
整體而言,這是一個可擴充的高可用性系統,無論工作負載多重,或規模多大,都能提供低延遲的讀取和寫入作業。
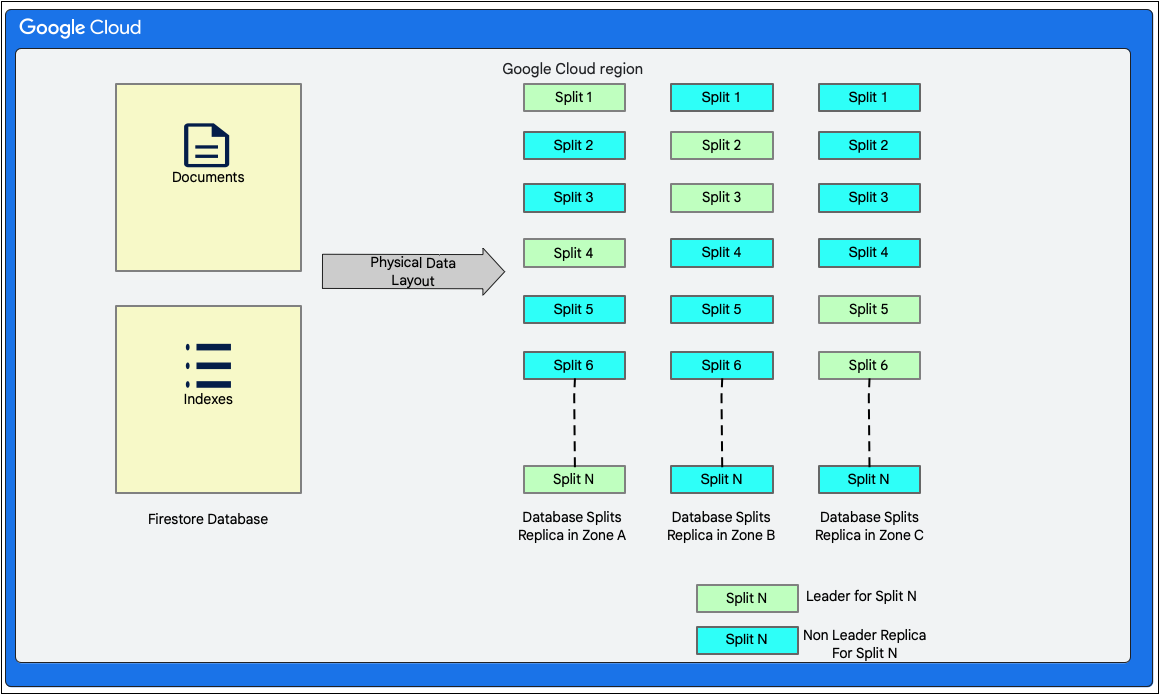
資料版面配置
Cloud Firestore 是無結構定義的文件資料庫。不過,在儲存層中,系統主要會以兩個關聯式資料庫樣式的資料表來配置資料,如下所示:
- 文件資料表:文件會儲存在這個資料表中。
- 索引資料表:這個資料表會儲存索引項目,方便您有效率地取得結果,並依索引值排序。
下圖顯示 Cloud Firestore 資料庫的表格在分割後可能呈現的樣貌。分割會複製到三個不同的區域,且每個分割都有指派的 Paxos 領導者。
單一區域與多區域
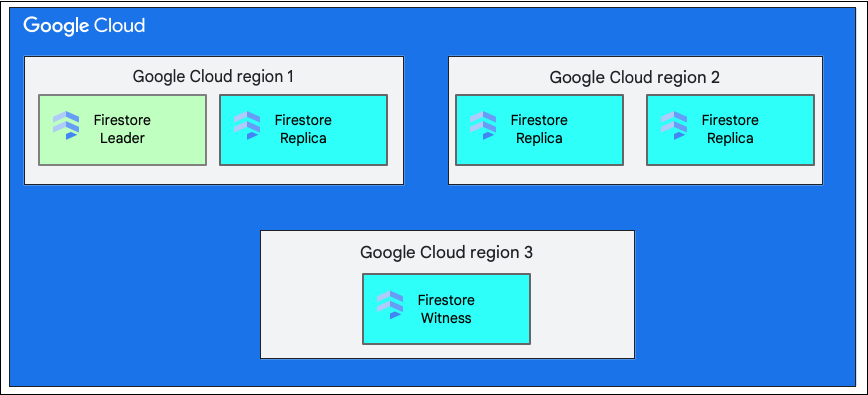
單一地區位置是指特定地理位置,例如 us-west1。如先前所述,Cloud Firestore 資料庫的資料分割會在所選區域內的不同可用區中建立副本。
多區域位置包含一組已定義的區域,用於儲存資料庫副本。在 Cloud Firestore 的多區域部署中,有兩個區域擁有資料庫中所有資料的完整副本。第三個區域有見證備用資源,不會維護完整資料集,但會參與複製作業。透過在多個區域之間複製資料,即使整個區域都遺失,資料仍可供寫入和讀取。
如要進一步瞭解區域位置,請參閱「Cloud Firestore位置」。
瞭解寫入作業的生命週期Cloud Firestore
Cloud Firestore 用戶端可以建立、更新或刪除單一文件,藉此寫入資料。寫入單一文件時,必須在儲存層中,以不可分割的形式更新文件和相關聯的索引項目。Cloud Firestore 也支援原子作業,這類作業包含對一或多個文件進行多次讀取和/或寫入。
對於所有類型的寫入作業,Cloud Firestore 都提供關聯式資料庫的 ACID 屬性 (完整性、一致性、獨立性和耐用性)。Cloud Firestore 也提供可序列化功能,也就是所有交易看起來會像依序執行。
寫入交易的高階步驟
當 Cloud Firestore 用戶端使用上述任一方法發出寫入或提交交易時,系統會在儲存層中以資料庫讀寫交易的形式執行。這項交易可讓 Cloud Firestore 提供先前所述的 ACID 屬性。
做為交易的第一步,Cloud Firestore 會讀取現有文件,並判斷要在 Documents 資料表中的資料進行哪些變動。
這也包括對「索引」表格進行必要更新,如下所示:
- 要新增至文件的欄位,必須在「索引」資料表中插入對應的欄位。
- 從文件中移除的欄位必須在「索引」表格中一併刪除。
- 在文件中修改的欄位,需要在「Indexes」資料表中刪除舊值並插入新值。
如要計算稍早提及的突變,Cloud Firestore 會讀取專案的索引設定。索引設定會儲存專案的索引相關資訊。Cloud Firestore 使用兩種索引:單一欄位和複合式。如要深入瞭解 Cloud Firestore 中建立的索引,請參閱「Cloud Firestore 中的索引類型」。
計算完變動後,Cloud Firestore 會在交易中收集這些變動,然後提交。
瞭解儲存層中的寫入交易
如先前所述,Cloud Firestore 中的寫入作業涉及儲存層的讀寫交易。視資料的版面配置而定,寫入作業可能涉及一或多個分割,如資料版面配置所示。
在下圖中,Cloud Firestore 資料庫有八個分割 (標示為 1 到 8),託管在單一可用區的三個不同儲存伺服器上,每個分割都會在 3 個(或更多) 不同可用區中複製。每個分割都有 Paxos 領導者,不同分割的領導者可能位於不同區域。
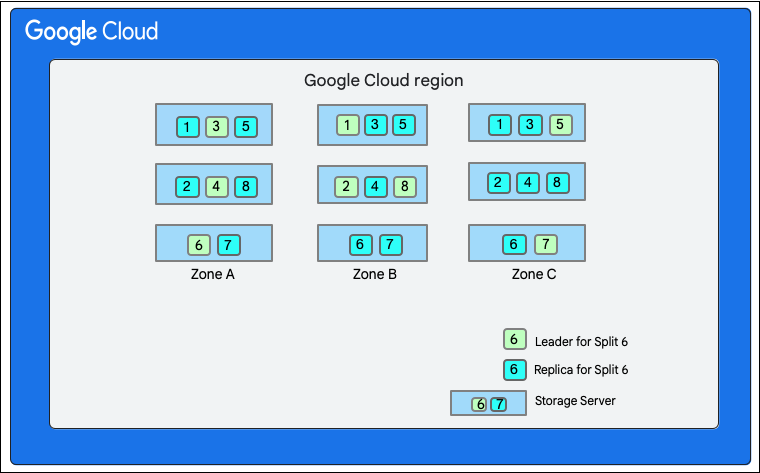 Cloud Firestore 資料庫分割">
Cloud Firestore 資料庫分割">
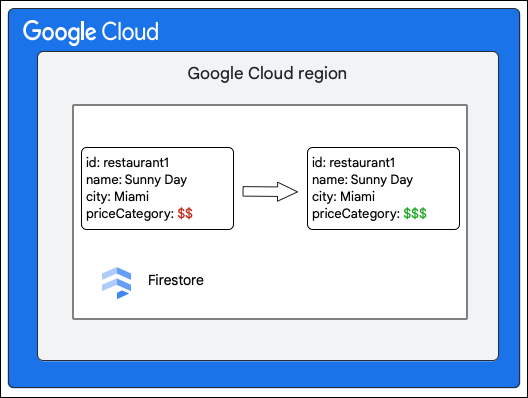
假設 Cloud Firestore 資料庫有 Restaurants 集合,如下所示:
Cloud Firestore 用戶端會更新 priceCategory 欄位的值,要求對 Restaurant 集合中的文件進行下列變更。
以下高階步驟說明寫入作業的過程:
- 建立讀寫交易。
- 從儲存層的「Documents」表格中,讀取
Restaurants集合中的restaurant1文件。 - 從「索引」表格讀取文件的索引。
- 計算要對資料進行的變動。在本例中,有五項變動:
- M1:更新「文件」表格中
restaurant1的資料列,反映priceCategory欄位值的變更。 - M2 和 M3:在遞減和遞增索引的「索引」表格中,刪除
priceCategory舊值的資料列。 - M4 和 M5:在「索引」表格中,為
priceCategory的新值插入遞減和遞增索引的資料列。
- M1:更新「文件」表格中
- 提交這些突變。
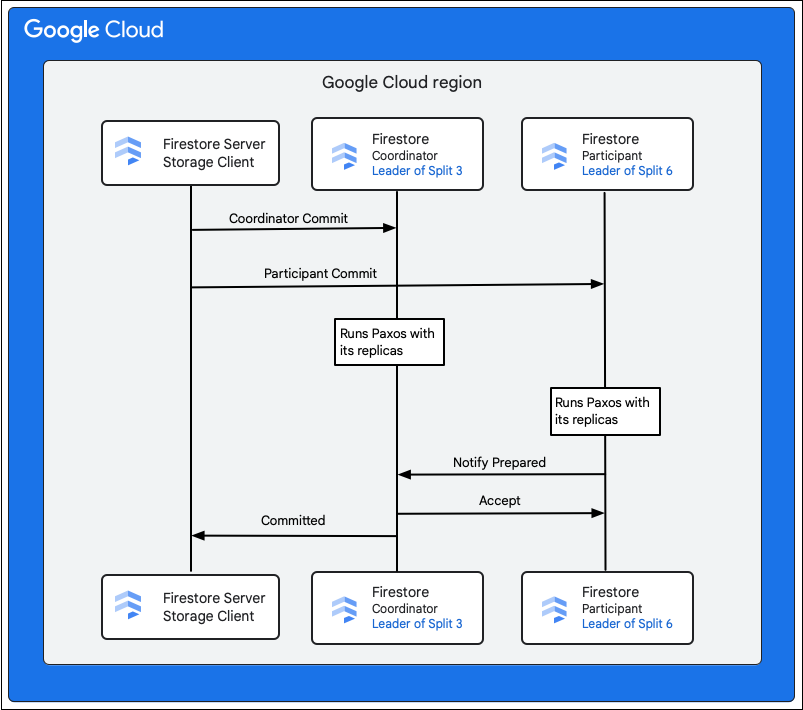
Cloud Firestore 服務中的儲存空間用戶端會尋找擁有要變更之資料列索引鍵的分割。假設分割 3 提供 M1,分割 6 提供 M2 到 M5。這是一項分散式交易,所有分割都是參與者。參與者分割也可能包含先前在讀取/寫入交易中讀取資料的任何其他分割。
以下步驟說明提交作業的過程:
- 儲存空間用戶端發出修訂。該修訂版本包含 M1 至 M5 的突變。
- 分割 3 和 6 是這筆交易的參與者。其中一位參與者會被選為協調者,例如 Split 3。協調者的工作是確認所有參與者的交易皆以不可分割的形式修訂或取消。
- 這些分割作業的領導者副本負責處理參與者和協調員完成的工作。
- 每位參與者和協調員都會使用各自的副本執行 Paxos 演算法。
- 領導者會與副本執行 Paxos 演算法。如果大多數副本都以
ok to commit回應回覆領導者,即達到法定人數。 - 接著,每位參與者都會在準備就緒時通知協調器 (兩階段提交的第一階段)。如果有任何參與者無法修訂交易,整筆交易便會
aborts。
- 領導者會與副本執行 Paxos 演算法。如果大多數副本都以
- 協調者得知所有參與者 (包括自己) 都已準備就緒後,就會將
accept交易結果傳送給所有參與者 (兩階段修訂的第二階段)。在這個階段,每個參與者都會將修訂決策記錄到穩定的儲存空間,並修訂交易。 - 協調器會在 Cloud Firestore 中回覆儲存空間用戶端,表示交易已修訂。同時,協調者和所有參與者都會將變異套用到資料。
如果 Cloud Firestore 資料庫很小,單一分割可能擁有 M1 到 M5 突變中的所有鍵。在這種情況下,交易只有一個參與者,不需要上述的兩階段提交,因此寫入速度會更快。
多區域寫入
在多區域部署中,副本分散在各個區域,可提高可用性,但會造成效能損失。不同區域的副本之間通訊時,往返時間會較長。因此,與單一區域部署相比,Cloud Firestore 作業的基準延遲略高。
我們會設定副本,確保分割區的領導權一律位於主要區域。主要區域是指流量傳入 Cloud Firestore 伺服器的區域。領導者做出這項決策後,Cloud Firestore 中的儲存空間用戶端與副本領導者 (或多重分割交易的協調器) 之間的通訊往返延遲時間就會縮短。
Cloud Firestore 中的每次寫入作業也會與 Cloud Firestore 中的即時引擎進行互動。如要進一步瞭解即時查詢,請參閱「大規模瞭解即時查詢」。
瞭解 Cloud Firestore 中的讀取生命週期
本節將深入探討 Cloud Firestore 中的獨立非即時讀取作業。在內部,Cloud Firestore 伺服器會在兩個主要階段處理大部分查詢:
- 對「Indexes」資料表進行單一範圍掃描
- 根據先前的掃描結果,在「文件」表格中進行點查
系統會使用資料庫交易,從儲存層讀取資料,確保讀取作業一致。不過,與用於寫入的交易不同,這些交易不會取得鎖定。而是選擇時間戳記,然後在該時間戳記執行所有讀取作業。由於不會取得鎖定,因此不會封鎖並行的讀寫交易。如要執行這項交易,Cloud Firestore 中的儲存空間用戶端會指定時間戳記範圍,告訴儲存空間層如何選擇讀取時間戳記。儲存空間用戶端在 Cloud Firestore 中選擇的時間戳記範圍類型,取決於讀取請求的讀取選項。
瞭解儲存層中的讀取交易
本節說明讀取類型,以及這些類型在 Cloud Firestore 儲存層中的處理方式。
強式讀取
根據預設,Cloud Firestore 讀取作業具有同步一致性。這種強式一致性表示 Cloud Firestore 讀取作業會傳回最新版本的資料,反映讀取作業開始前已提交的所有寫入作業。
單一分割讀取
Cloud Firestore 中的儲存空間用戶端會查詢擁有要讀取資料列索引鍵的分割。假設需要從先前的區段讀取 Split 3,用戶端會將讀取要求傳送至最近的副本,以縮短往返延遲時間。
此時,視所選備用資源而定,可能會發生下列情況:
- 讀取要求會傳送至領導者副本 (區域 A)。
- 由於領導者永遠處於最新狀態,讀取便可直接繼續進行。
- 讀取要求送往非主要備用資源 (例如區域 B)
- 分割 3 可能會根據內部狀態判斷自己有足夠資訊可處理讀取作業,然後進行處理。
- Split 3 不確定它看到是不是最新的資料。它會傳送訊息給領導者,要求需要套用的最後一筆交易的時間戳記,以處理讀取作業。一旦套用交易,便可繼續讀取作業。
Cloud Firestore,然後將回應傳回給用戶端。
多重分割讀取
如果必須從多個分割區讀取資料,所有分割區都會發生相同的機制。所有分割作業都傳回資料後,Cloud Firestore 中的儲存空間用戶端會合併結果。Cloud Firestore 接著會將這項資料傳送給用戶端。
過時讀取
Cloud Firestore 的預設模式為強讀取。不過,由於可能需要與領導者通訊,因此可能會導致延遲時間較長。通常 Cloud Firestore 應用程式不需要讀取最新版本的資料,即使資料可能過時幾秒,功能也能正常運作。
在這種情況下,用戶端可以選擇使用 read_time 讀取選項接收過時的讀取內容。在這種情況下,系統會讀取 read_time 時的資料,而最接近的副本很可能已驗證其在指定 read_time 時的資料。
如要顯著提升效能,合理的過時程度值是 15 秒。即使是過時的讀取作業,產生的資料列也會彼此一致。
避開熱點
Cloud Firestore 中的分割會自動分成較小的區塊,以便在需要或索引鍵空間擴充時,將流量服務工作分配給更多儲存伺服器。即使流量消失,為處理過多流量而建立的分割區仍會保留約 24 小時。因此,如果流量尖峰期反覆出現,系統會維持分割狀態,並在必要時導入更多分割。這些機制可協助 Cloud Firestore 資料庫在流量負載或資料庫大小增加時自動調度資源。不過,請注意以下限制。
分割儲存空間和負載需要時間,如果流量增加速度過快,可能會導致延遲時間過長或超出期限錯誤 (一般稱為「熱點」),而服務會進行調整。最佳做法是在鍵值範圍內分配作業,同時以每秒 500 項作業的速度,提高資料庫中集合的流量。逐步增加流量後,每五分鐘最多增加 50% 的流量。這個程序稱為「500/50/5」規則,可讓資料庫以最佳方式擴充,滿足工作負載需求。
雖然系統會隨著負載增加自動建立分割,但 Cloud Firestore 只能分割鍵範圍,直到使用專屬的一組複製儲存伺服器提供單一文件為止。因此,如果對單一文件執行大量並行作業,可能會導致該文件出現熱點。如果單一文件持續出現高延遲,建議修改資料模型,將資料分割或複製到多個文件。
如果多項作業嘗試同時讀取和/或寫入同一個文件,就會發生爭用錯誤。
如果使用依序遞增/遞減的鍵做為 Cloud Firestore 中的文件 ID,且每秒的作業數相當高,也會發生熱點問題。建立更多拆分作業無法解決問題,因為流量暴增只是轉移到新建立的拆分作業。由於 Cloud Firestore 預設會自動為文件中的所有欄位建立索引,因此如果文件欄位包含依序遞增/遞減的值 (例如時間戳記),索引空間中也可能會建立這類移動熱點。
請注意,只要遵循上述做法,Cloud Firestore 就能擴充規模,處理任意大小的工作負載,不必調整任何設定。
疑難排解
Cloud Firestore 提供 Key Visualizer 做為診斷工具,用於分析使用模式及排解熱點問題。