
Modele generatywne skutecznie rozwiązują wiele rodzajów problemów. Jednak są one ograniczone przez takie czynniki jak:
- Po trenowaniu są one zamrażane, co prowadzi do nieaktualnej wiedzy.
- Nie mogą przesyłać zapytań do danych zewnętrznych ani ich modyfikować.
Wywoływanie funkcji może pomóc w przezwyciężeniu niektórych z tych ograniczeń. Wywoływanie funkcji jest czasami nazywane korzystaniem z narzędzi, ponieważ umożliwia modelowi korzystanie z zewnętrznych narzędzi, takich jak interfejsy API i funkcje, do generowania ostatecznej odpowiedzi.
Z tego przewodnika dowiesz się, jak skonfigurować wywołanie funkcji podobne do scenariusza opisanego w następnej sekcji tej strony. Aby skonfigurować wywoływanie funkcji w aplikacji:
Krok 1. Napisz funkcję, która może dostarczać modelowi informacji potrzebnych do wygenerowania ostatecznej odpowiedzi (np. funkcja może wywoływać zewnętrzny interfejs API).
Krok 2. Utwórz deklarację funkcji, która opisuje funkcję i jej parametry.
Krok 3. Podczas inicjowania modelu podaj deklarację funkcji, aby model wiedział, jak w razie potrzeby może jej używać.
Krok 4. Skonfiguruj aplikację tak, aby model mógł przesyłać wymagane informacje, które umożliwią jej wywołanie funkcji.
Krok 5: przekaż odpowiedź funkcji z powrotem do modelu, aby mógł on wygenerować ostateczną odpowiedź.
Omówienie przykładu wywoływania funkcji
Gdy wysyłasz do modelu żądanie, możesz też podać mu zestaw „narzędzi” (np. funkcji), których może użyć do wygenerowania ostatecznej odpowiedzi. Aby korzystać z tych funkcji i je wywoływać („wywoływanie funkcji”), model i aplikacja muszą wymieniać informacje, dlatego zalecamy korzystanie z wywoływania funkcji za pomocą interfejsu czatu wieloetapowego.
Wyobraź sobie, że masz aplikację, w której użytkownik może wpisać prompta, np.:What was the weather in Boston on October 17, 2024?
Modele Gemini mogą nie znać tych informacji o pogodzie, ale wyobraź sobie, że znasz zewnętrzny interfejs API usługi pogodowej, który może je udostępnić. Możesz użyć wywoływania funkcji, aby udostępnić modelowi Gemini ścieżkę do tego interfejsu API i informacji o pogodzie.
Najpierw w aplikacji piszesz funkcję fetchWeather, która współdziała z tym hipotetycznym zewnętrznym interfejsem API, który ma takie dane wejściowe i wyjściowe:
| Parametr | Typ | Wymagany | Opis |
|---|---|---|---|
| Dane wejściowe | |||
location |
Obiekt | Tak | Nazwa miasta i stanu, dla których chcesz uzyskać informacje o pogodzie. Obsługiwane są tylko miasta w Stanach Zjednoczonych. Musi być zawsze zagnieżdżonym obiektem city i state.
|
date |
Ciąg znaków | Tak | Data, dla której chcesz pobrać dane pogodowe (zawsze musi być w formacie YYYY-MM-DD).
|
| Wyniki | |||
temperature |
Liczba całkowita | Tak | Temperatura (w stopniach Fahrenheita) |
chancePrecipitation |
Ciąg znaków | Tak | Prawdopodobieństwo opadów (wyrażone w procentach) |
cloudConditions |
Ciąg znaków | Tak | Warunki chmury (jeden z tych kodów: clear, partlyCloudy, mostlyCloudy, cloudy)
|
Podczas inicjowania modelu informujesz go, że ta funkcja fetchWeatheristnieje i w razie potrzeby można jej używać do przetwarzania przychodzących żądań.
Jest to tzw. „deklaracja funkcji”. Model nie wywołuje funkcji bezpośrednio. Zamiast tego, podczas przetwarzania przychodzącego żądania model decyduje, czy fetchWeather może pomóc w odpowiedzi na to żądanie. Jeśli model uzna, że funkcja może być przydatna, wygeneruje uporządkowane dane, które pomogą aplikacji wywołać funkcję.
Ponownie przyjrzyj się przychodzącemu żądaniu:What was the weather in Boston on October 17, 2024? Model prawdopodobnie uzna, że funkcja fetchWeather może pomóc w wygenerowaniu odpowiedzi. Model sprawdzi, jakie parametry wejściowe są potrzebne w przypadku funkcji fetchWeather, a następnie wygeneruje uporządkowane dane wejściowe dla tej funkcji, które będą wyglądać mniej więcej tak:
{
functionName: fetchWeather,
location: {
city: Boston,
state: Massachusetts // the model can infer the state from the prompt
},
date: 2024-10-17
}
Model przekazuje te uporządkowane dane wejściowe do aplikacji, aby mogła ona wywołać funkcję fetchWeather. Gdy aplikacja otrzyma z interfejsu API informacje o warunkach pogodowych, przekaże je do modelu. Te informacje o pogodzie pozwalają modelowi dokończyć przetwarzanie i wygenerować odpowiedź na początkowe żądanie What was the weather in Boston on October 17, 2024?.
Model może podać ostateczną odpowiedź w języku naturalnym, np.:On October 17, 2024, in Boston, it was 38 degrees Fahrenheit with partly cloudy skies.
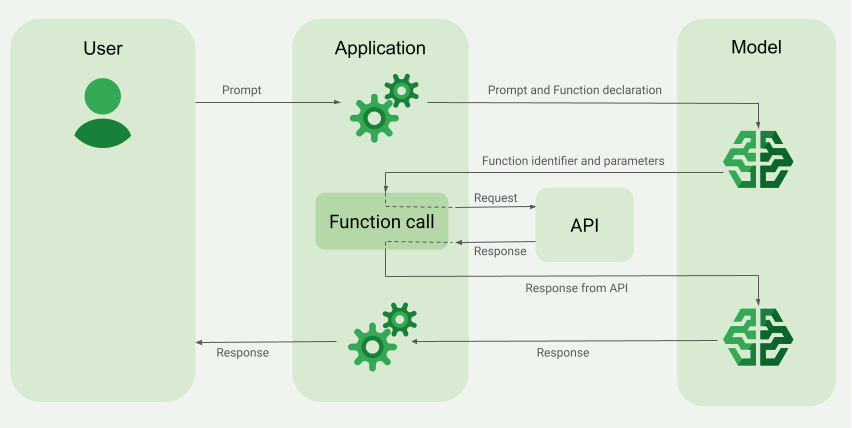
Wdrażanie wywoływania funkcji
Poniższe kroki w tym przewodniku pokazują, jak wdrożyć wywołanie funkcji podobne do procesu opisanego w sekcji Omówienie przykładu wywołania funkcji (u góry tej strony).
Zanim zaczniesz
|
Kliknij Gemini API dostawcę, aby wyświetlić na tej stronie treści i kod dostawcy. |
Jeśli jeszcze tego nie zrobisz, zapoznaj się z przewodnikiem dla początkujących, w którym znajdziesz informacje o tym, jak skonfigurować projekt Firebase, połączyć aplikację z Firebase, dodać pakiet SDK, zainicjować usługę backendu dla wybranego dostawcy Gemini API i utworzyć instancję GenerativeModel.
Do testowania i ulepszania promptów zalecamy używanie Google AI Studio.
Krok 1. Napisz funkcję
Wyobraź sobie, że masz aplikację, w której użytkownik może wpisać prompta, np.:What was the weather in Boston on October 17, 2024? Gemini
Modele mogą nie znać tych informacji o pogodzie, ale wyobraź sobie, że znasz zewnętrzny interfejs API usługi pogodowej, który może je udostępnić. Scenariusz opisany w tym przewodniku
opiera się na tym hipotetycznym zewnętrznym interfejsie API.
Napisz w aplikacji funkcję, która będzie wchodzić w interakcję z hipotetycznym zewnętrznym interfejsem API i dostarczać modelowi informacje potrzebne do wygenerowania ostatecznej prośby. W tym przykładzie dotyczącym pogody będzie to funkcja fetchWeather, która wywołuje ten hipotetyczny zewnętrzny interfejs API.
Swift
// This function calls a hypothetical external API that returns
// a collection of weather information for a given location on a given date.
func fetchWeather(city: String, state: String, date: String) -> JSONObject {
// TODO(developer): Write a standard function that would call an external weather API.
// For demo purposes, this hypothetical response is hardcoded here in the expected format.
return [
"temperature": .number(38),
"chancePrecipitation": .string("56%"),
"cloudConditions": .string("partlyCloudy"),
]
}
Kotlin
// This function calls a hypothetical external API that returns
// a collection of weather information for a given location on a given date.
// `location` is an object of the form { city: string, state: string }
data class Location(val city: String, val state: String)
suspend fun fetchWeather(location: Location, date: String): JsonObject {
// TODO(developer): Write a standard function that would call to an external weather API.
// For demo purposes, this hypothetical response is hardcoded here in the expected format.
return JsonObject(mapOf(
"temperature" to JsonPrimitive(38),
"chancePrecipitation" to JsonPrimitive("56%"),
"cloudConditions" to JsonPrimitive("partlyCloudy")
))
}
Java
// This function calls a hypothetical external API that returns
// a collection of weather information for a given location on a given date.
// `location` is an object of the form { city: string, state: string }
public JsonObject fetchWeather(Location location, String date) {
// TODO(developer): Write a standard function that would call to an external weather API.
// For demo purposes, this hypothetical response is hardcoded here in the expected format.
return new JsonObject(Map.of(
"temperature", JsonPrimitive(38),
"chancePrecipitation", JsonPrimitive("56%"),
"cloudConditions", JsonPrimitive("partlyCloudy")));
}
Web
// This function calls a hypothetical external API that returns
// a collection of weather information for a given location on a given date.
// `location` is an object of the form { city: string, state: string }
async function fetchWeather({ location, date }) {
// TODO(developer): Write a standard function that would call to an external weather API.
// For demo purposes, this hypothetical response is hardcoded here in the expected format.
return {
temperature: 38,
chancePrecipitation: "56%",
cloudConditions: "partlyCloudy",
};
}
Dart
// This function calls a hypothetical external API that returns
// a collection of weather information for a given location on a given date.
// `location` is an object of the form { city: string, state: string }
Future<Map<String, Object?>> fetchWeather(
Location location, String date
) async {
// TODO(developer): Write a standard function that would call to an external weather API.
// For demo purposes, this hypothetical response is hardcoded here in the expected format.
final apiResponse = {
'temperature': 38,
'chancePrecipitation': '56%',
'cloudConditions': 'partlyCloudy',
};
return apiResponse;
}
Unity
// This function calls a hypothetical external API that returns
// a collection of weather information for a given location on a given date.
System.Collections.Generic.Dictionary<string, object> FetchWeather(
string city, string state, string date) {
// TODO(developer): Write a standard function that would call an external weather API.
// For demo purposes, this hypothetical response is hardcoded here in the expected format.
return new System.Collections.Generic.Dictionary<string, object>() {
{"temperature", 38},
{"chancePrecipitation", "56%"},
{"cloudConditions", "partlyCloudy"},
};
}
Krok 2. Utwórz deklarację funkcji
Utwórz deklarację funkcji, którą później przekażesz modelowi (następny krok tego przewodnika).
W deklaracji podaj jak najwięcej szczegółów w opisach funkcji i jej parametrów.
Model wykorzystuje informacje zawarte w deklaracji funkcji, aby określić, którą funkcję wybrać i jak podać wartości parametrów dla rzeczywistego wywołania funkcji. W sekcji Dodatkowe zachowania i opcje na tej stronie znajdziesz informacje o tym, jak model może wybierać funkcje, oraz o tym, jak możesz kontrolować ten wybór.
Pamiętaj o tych uwagach na temat podanego schematu:
Deklaracje funkcji musisz podać w formacie schematu zgodnym ze schematem OpenAPI. Vertex AI obsługuje schemat OpenAPI w ograniczonym zakresie.
Obsługiwane są te atrybuty:
type,nullable,required,format,description,properties,items,enum.Te atrybuty nie są obsługiwane:
default,optional,maximum,oneOf.
Domyślnie w przypadku Firebase AI Logic pakietów SDK wszystkie pola są wymagane, chyba że w
optionalPropertiestablicy określisz je jako opcjonalne. W przypadku tych opcjonalnych pól model może je wypełnić lub pominąć. Pamiętaj, że jest to odwrotność domyślnego działania tych 2 dostawców, jeśli używasz ich pakietów SDK serwera lub ich interfejsu API bezpośrednio.Gemini API
Sprawdzone metody związane z deklaracjami funkcji, w tym wskazówki dotyczące nazw i opisów, znajdziesz w sekcji Sprawdzone metody w dokumentacji Google Cloud. Sprawdzone metody znajdziesz w Gemini Developer API dokumentacji.
Deklarację funkcji możesz napisać w ten sposób:
Swift
let fetchWeatherTool = FunctionDeclaration(
name: "fetchWeather",
description: "Get the weather conditions for a specific city on a specific date.",
parameters: [
"location": .object(
properties: [
"city": .string(description: "The city of the location."),
"state": .string(description: "The US state of the location."),
],
description: """
The name of the city and its state for which to get the weather. Only cities in the
USA are supported.
"""
),
"date": .string(
description: """
The date for which to get the weather. Date must be in the format: YYYY-MM-DD.
"""
),
]
)
Kotlin
val fetchWeatherTool = FunctionDeclaration(
"fetchWeather",
"Get the weather conditions for a specific city on a specific date.",
mapOf(
"location" to Schema.obj(
mapOf(
"city" to Schema.string("The city of the location."),
"state" to Schema.string("The US state of the location."),
),
description = "The name of the city and its state for which " +
"to get the weather. Only cities in the " +
"USA are supported."
),
"date" to Schema.string("The date for which to get the weather." +
" Date must be in the format: YYYY-MM-DD."
),
),
)
Java
FunctionDeclaration fetchWeatherTool = new FunctionDeclaration(
"fetchWeather",
"Get the weather conditions for a specific city on a specific date.",
Map.of("location",
Schema.obj(Map.of(
"city", Schema.str("The city of the location."),
"state", Schema.str("The US state of the location."))),
"date",
Schema.str("The date for which to get the weather. " +
"Date must be in the format: YYYY-MM-DD.")),
Collections.emptyList());
Web
const fetchWeatherTool: FunctionDeclarationsTool = {
functionDeclarations: [
{
name: "fetchWeather",
description:
"Get the weather conditions for a specific city on a specific date",
parameters: Schema.object({
properties: {
location: Schema.object({
description:
"The name of the city and its state for which to get " +
"the weather. Only cities in the USA are supported.",
properties: {
city: Schema.string({
description: "The city of the location."
}),
state: Schema.string({
description: "The US state of the location."
}),
},
}),
date: Schema.string({
description:
"The date for which to get the weather. Date must be in the" +
" format: YYYY-MM-DD.",
}),
},
}),
},
],
};
Dart
final fetchWeatherTool = FunctionDeclaration(
'fetchWeather',
'Get the weather conditions for a specific city on a specific date.',
parameters: {
'location': Schema.object(
description:
'The name of the city and its state for which to get'
'the weather. Only cities in the USA are supported.',
properties: {
'city': Schema.string(
description: 'The city of the location.'
),
'state': Schema.string(
description: 'The US state of the location.'
),
},
),
'date': Schema.string(
description:
'The date for which to get the weather. Date must be in the format: YYYY-MM-DD.'
),
},
);
Unity
var fetchWeatherTool = new Tool(new FunctionDeclaration(
name: "fetchWeather",
description: "Get the weather conditions for a specific city on a specific date.",
parameters: new System.Collections.Generic.Dictionary<string, Schema>() {
{ "location", Schema.Object(
properties: new System.Collections.Generic.Dictionary<string, Schema>() {
{ "city", Schema.String(description: "The city of the location.") },
{ "state", Schema.String(description: "The US state of the location.")}
},
description: "The name of the city and its state for which to get the weather. Only cities in the USA are supported."
) },
{ "date", Schema.String(
description: "The date for which to get the weather. Date must be in the format: YYYY-MM-DD."
)}
}
));
Krok 3. Podaj deklarację funkcji podczas inicjowania modelu
Maksymalna liczba deklaracji funkcji, które możesz podać w żądaniu, to 128. W sekcji Dodatkowe zachowania i opcje na tej stronie znajdziesz informacje o tym, jak model może wybierać funkcje, a także jak możesz kontrolować ten wybór (za pomocą znaku toolConfig, aby ustawić tryb wywoływania funkcji).
Swift
import FirebaseAILogic
// Initialize the Gemini Developer API backend service
// Create a `GenerativeModel` instance with a model that supports your use case
let model = FirebaseAI.firebaseAI(backend: .googleAI()).generativeModel(
modelName: "gemini-2.5-flash",
// Provide the function declaration to the model.
tools: [.functionDeclarations([fetchWeatherTool])]
)
Kotlin
// Initialize the Gemini Developer API backend service
// Create a `GenerativeModel` instance with a model that supports your use case
val model = Firebase.ai(backend = GenerativeBackend.googleAI()).generativeModel(
modelName = "gemini-2.5-flash",
// Provide the function declaration to the model.
tools = listOf(Tool.functionDeclarations(listOf(fetchWeatherTool)))
)
Java
// Initialize the Gemini Developer API backend service
// Create a `GenerativeModel` instance with a model that supports your use case
GenerativeModelFutures model = GenerativeModelFutures.from(
FirebaseAI.getInstance(GenerativeBackend.googleAI())
.generativeModel("gemini-2.5-flash",
null,
null,
// Provide the function declaration to the model.
List.of(Tool.functionDeclarations(List.of(fetchWeatherTool)))));
Web
import { initializeApp } from "firebase/app";
import { getAI, getGenerativeModel, GoogleAIBackend } from "firebase/ai";
// TODO(developer) Replace the following with your app's Firebase configuration
// See: https://firebase.google.com/docs/web/learn-more#config-object
const firebaseConfig = {
// ...
};
// Initialize FirebaseApp
const firebaseApp = initializeApp(firebaseConfig);
// Initialize the Gemini Developer API backend service
const firebaseAI = getAI(firebaseApp, { backend: new GoogleAIBackend() });
// Create a `GenerativeModel` instance with a model that supports your use case
const model = getGenerativeModel(firebaseAI, {
model: "gemini-2.5-flash",
// Provide the function declaration to the model.
tools: fetchWeatherTool
});
Dart
import 'package:firebase_ai/firebase_ai.dart';
import 'package:firebase_core/firebase_core.dart';
import 'firebase_options.dart';
// Initialize FirebaseApp
await Firebase.initializeApp(
options: DefaultFirebaseOptions.currentPlatform,
);
// Initialize the Gemini Developer API backend service
// Create a `GenerativeModel` instance with a model that supports your use case
_functionCallModel = FirebaseAI.googleAI().generativeModel(
model: 'gemini-2.5-flash',
// Provide the function declaration to the model.
tools: [
Tool.functionDeclarations([fetchWeatherTool]),
],
);
Unity
using Firebase;
using Firebase.AI;
// Initialize the Gemini Developer API backend service
// Create a `GenerativeModel` instance with a model that supports your use case
var model = FirebaseAI.DefaultInstance.GetGenerativeModel(
modelName: "gemini-2.5-flash",
// Provide the function declaration to the model.
tools: new Tool[] { fetchWeatherTool }
);
Dowiedz się, jak wybrać model odpowiednie do Twojego przypadku użycia i aplikacji.
Krok 4. Wywołaj funkcję, aby wywołać zewnętrzny interfejs API.
Jeśli model uzna, że funkcja fetchWeather może pomóc w wygenerowaniu ostatecznej odpowiedzi, aplikacja musi wykonać rzeczywiste wywołanie tej funkcji przy użyciu danych wejściowych o ustrukturyzowanej formie dostarczonych przez model.
Ponieważ informacje muszą być przekazywane w obie strony między modelem a aplikacją, zalecanym sposobem korzystania z wywoływania funkcji jest interfejs czatu wielokrotnego.
Ten fragment kodu pokazuje, jak aplikacja jest informowana o tym, że model chce użyć funkcji fetchWeather. Pokazuje też, że model podał niezbędne wartości parametrów wejściowych dla wywołania funkcji (i jej bazowego zewnętrznego interfejsu API).
W tym przykładzie przychodzące żądanie zawierało prompt What was the weather in Boston on October 17, 2024?. Na podstawie tego promptu model wywnioskował parametry wejściowe wymagane przez funkcję fetchWeather (czyli city, state i date).
Swift
let chat = model.startChat()
let prompt = "What was the weather in Boston on October 17, 2024?"
// Send the user's question (the prompt) to the model using multi-turn chat.
let response = try await chat.sendMessage(prompt)
var functionResponses = [FunctionResponsePart]()
// When the model responds with one or more function calls, invoke the function(s).
for functionCall in response.functionCalls {
if functionCall.name == "fetchWeather" {
// TODO(developer): Handle invalid arguments.
guard case let .object(location) = functionCall.args["location"] else { fatalError() }
guard case let .string(city) = location["city"] else { fatalError() }
guard case let .string(state) = location["state"] else { fatalError() }
guard case let .string(date) = functionCall.args["date"] else { fatalError() }
functionResponses.append(FunctionResponsePart(
name: functionCall.name,
// Forward the structured input data prepared by the model
// to the hypothetical external API.
response: fetchWeather(city: city, state: state, date: date)
))
}
// TODO(developer): Handle other potential function calls, if any.
}
Kotlin
val prompt = "What was the weather in Boston on October 17, 2024?"
val chat = model.startChat()
// Send the user's question (the prompt) to the model using multi-turn chat.
val result = chat.sendMessage(prompt)
val functionCalls = result.functionCalls
// When the model responds with one or more function calls, invoke the function(s).
val fetchWeatherCall = functionCalls.find { it.name == "fetchWeather" }
// Forward the structured input data prepared by the model
// to the hypothetical external API.
val functionResponse = fetchWeatherCall?.let {
// Alternatively, if your `Location` class is marked as @Serializable, you can use
// val location = Json.decodeFromJsonElement<Location>(it.args["location"]!!)
val location = Location(
it.args["location"]!!.jsonObject["city"]!!.jsonPrimitive.content,
it.args["location"]!!.jsonObject["state"]!!.jsonPrimitive.content
)
val date = it.args["date"]!!.jsonPrimitive.content
fetchWeather(location, date)
}
Java
String prompt = "What was the weather in Boston on October 17, 2024?";
ChatFutures chatFutures = model.startChat();
// Send the user's question (the prompt) to the model using multi-turn chat.
ListenableFuture<GenerateContentResponse> response =
chatFutures.sendMessage(new Content("user", List.of(new TextPart(prompt))));
ListenableFuture<JsonObject> handleFunctionCallFuture = Futures.transform(response, result -> {
for (FunctionCallPart functionCall : result.getFunctionCalls()) {
if (functionCall.getName().equals("fetchWeather")) {
Map<String, JsonElement> args = functionCall.getArgs();
JsonObject locationJsonObject =
JsonElementKt.getJsonObject(args.get("location"));
String city =
JsonElementKt.getContentOrNull(
JsonElementKt.getJsonPrimitive(
locationJsonObject.get("city")));
String state =
JsonElementKt.getContentOrNull(
JsonElementKt.getJsonPrimitive(
locationJsonObject.get("state")));
Location location = new Location(city, state);
String date = JsonElementKt.getContentOrNull(
JsonElementKt.getJsonPrimitive(
args.get("date")));
return fetchWeather(location, date);
}
}
return null;
}, Executors.newSingleThreadExecutor());
Web
const chat = model.startChat();
const prompt = "What was the weather in Boston on October 17, 2024?";
// Send the user's question (the prompt) to the model using multi-turn chat.
let result = await chat.sendMessage(prompt);
const functionCalls = result.response.functionCalls();
let functionCall;
let functionResult;
// When the model responds with one or more function calls, invoke the function(s).
if (functionCalls.length > 0) {
for (const call of functionCalls) {
if (call.name === "fetchWeather") {
// Forward the structured input data prepared by the model
// to the hypothetical external API.
functionResult = await fetchWeather(call.args);
functionCall = call;
}
}
}
Dart
final chat = _functionCallModel.startChat();
const prompt = 'What was the weather in Boston on October 17, 2024?';
// Send the user's question (the prompt) to the model using multi-turn chat.
var response = await chat.sendMessage(Content.text(prompt));
final functionCalls = response.functionCalls.toList();
// When the model responds with one or more function calls, invoke the function(s).
if (functionCalls.isNotEmpty) {
for (final functionCall in functionCalls) {
if (functionCall.name == 'fetchWeather') {
Map<String, dynamic> location =
functionCall.args['location']! as Map<String, dynamic>;
var date = functionCall.args['date']! as String;
var city = location['city'] as String;
var state = location['state'] as String;
final functionResult =
await fetchWeather(Location(city, state), date);
// Send the response to the model so that it can use the result to
// generate text for the user.
response = await functionCallChat.sendMessage(
Content.functionResponse(functionCall.name, functionResult),
);
}
}
} else {
throw UnimplementedError(
'Function not declared to the model: ${functionCall.name}',
);
}
Unity
var chat = model.StartChat();
var prompt = "What was the weather in Boston on October 17, 2024?";
// Send the user's question (the prompt) to the model using multi-turn chat.
var response = await chat.SendMessageAsync(prompt);
var functionResponses = new List<ModelContent>();
foreach (var functionCall in response.FunctionCalls) {
if (functionCall.Name == "fetchWeather") {
// TODO(developer): Handle invalid arguments.
var city = functionCall.Args["city"] as string;
var state = functionCall.Args["state"] as string;
var date = functionCall.Args["date"] as string;
functionResponses.Add(ModelContent.FunctionResponse(
name: functionCall.Name,
// Forward the structured input data prepared by the model
// to the hypothetical external API.
response: FetchWeather(city: city, state: state, date: date)
));
}
// TODO(developer): Handle other potential function calls, if any.
}
Krok 5. Przekaż dane wyjściowe funkcji do modelu, aby wygenerować ostateczną odpowiedź.
Gdy funkcja fetchWeather zwróci informacje o pogodzie, aplikacja musi przekazać je z powrotem do modelu.
Następnie model przeprowadza końcowe przetwarzanie i generuje ostateczną odpowiedź w języku naturalnym, np.:
On October 17, 2024 in Boston, it was 38 degrees Fahrenheit with partly cloudy skies.
Swift
// Send the response(s) from the function back to the model
// so that the model can use it to generate its final response.
let finalResponse = try await chat.sendMessage(
[ModelContent(role: "function", parts: functionResponses)]
)
// Log the text response.
print(finalResponse.text ?? "No text in response.")
Kotlin
// Send the response(s) from the function back to the model
// so that the model can use it to generate its final response.
val finalResponse = chat.sendMessage(content("function") {
part(FunctionResponsePart("fetchWeather", functionResponse!!))
})
// Log the text response.
println(finalResponse.text ?: "No text in response")
Java
ListenableFuture<GenerateContentResponse> modelResponseFuture = Futures.transformAsync(
handleFunctionCallFuture,
// Send the response(s) from the function back to the model
// so that the model can use it to generate its final response.
functionCallResult -> chatFutures.sendMessage(new Content("function",
List.of(new FunctionResponsePart(
"fetchWeather", functionCallResult)))),
Executors.newSingleThreadExecutor());
Futures.addCallback(modelResponseFuture, new FutureCallback<GenerateContentResponse>() {
@Override
public void onSuccess(GenerateContentResponse result) {
if (result.getText() != null) {
// Log the text response.
System.out.println(result.getText());
}
}
@Override
public void onFailure(Throwable t) {
// handle error
}
}, Executors.newSingleThreadExecutor());
Web
// Send the response from the function back to the model
// so that the model can use it to generate its final response.
result = await chat.sendMessage([
{
functionResponse: {
name: functionCall.name, // "fetchWeather"
response: functionResult,
},
},
]);
console.log(result.response.text());
Dart
// Send the response from the function back to the model
// so that the model can use it to generate its final response.
response = await chat
.sendMessage(Content.functionResponse(functionCall.name, functionResult));
Unity
// Send the response(s) from the function back to the model
// so that the model can use it to generate its final response.
var finalResponse = await chat.SendMessageAsync(functionResponses);
// Log the text response.
UnityEngine.Debug.Log(finalResponse.Text ?? "No text in response.");
Dodatkowe zachowania i opcje
Oto kilka dodatkowych zachowań wywoływania funkcji, które musisz uwzględnić w kodzie, oraz opcje, które możesz kontrolować.
Model może poprosić o ponowne wywołanie funkcji lub wywołanie innej funkcji.
Jeśli odpowiedź z jednego wywołania funkcji jest niewystarczająca, aby model mógł wygenerować ostateczną odpowiedź, może poprosić o dodatkowe wywołanie funkcji lub o wywołanie zupełnie innej funkcji. Może się to zdarzyć tylko wtedy, gdy w deklaracji funkcji podasz modelowi więcej niż jedną funkcję.
Aplikacja musi uwzględniać to, że model może poprosić o dodatkowe wywołania funkcji.
Model może poprosić o wywołanie kilku funkcji jednocześnie.
Na liście deklaracji funkcji możesz podać maksymalnie 128 funkcji. W takiej sytuacji model może uznać, że do wygenerowania ostatecznej odpowiedzi potrzebne jest wywołanie kilku funkcji. Może też zdecydować się na wywołanie niektórych z tych funkcji w tym samym czasie – nazywa się to równoległym wywoływaniem funkcji.
Aplikacja musi uwzględniać to, że model może poprosić o wykonanie kilku funkcji jednocześnie, i przekazywać do niego wszystkie odpowiedzi z tych funkcji.
Możesz określić, czy i w jaki sposób model może prosić o wywoływanie funkcji.
Możesz wprowadzić pewne ograniczenia dotyczące tego, jak i czy model ma używać podanych deklaracji funkcji. Jest to tzw. ustawianie trybu wywoływania funkcji. Oto przykłady:
Zamiast zezwalać modelowi na wybór między natychmiastową odpowiedzią w języku naturalnym a wywołaniem funkcji, możesz wymusić, aby zawsze używał wywołań funkcji. Jest to tzw. wymuszone wywoływanie funkcji.
Jeśli podasz kilka deklaracji funkcji, możesz ograniczyć model do używania tylko podzbioru podanych funkcji.
Te ograniczenia (lub tryby) wdrażasz, dodając konfigurację narzędzia (toolConfig) wraz z promptem i deklaracjami funkcji. W konfiguracji narzędzia możesz określić jeden z tych trybów. Najbardziej przydatny tryb to ANY.
| Tryb | Opis |
|---|---|
AUTO |
Domyślne działanie modelu. Model decyduje, czy użyć wywołania funkcji, czy odpowiedzi w języku naturalnym. |
ANY |
Model musi używać wywołań funkcji („wymuszone wywoływanie funkcji”). Aby ograniczyć model do podzbioru funkcji, podaj nazwy dozwolonych funkcji w allowedFunctionNames.
|
NONE |
Model nie może używać wywołań funkcji. Działanie to jest równoważne żądaniu modelu bez powiązanych deklaracji funkcji. |
Co jeszcze możesz zrobić?
Wypróbuj inne funkcje
- Twórz rozmowy wieloetapowe (czat).
- Generowanie tekstu na podstawie promptów zawierających tylko tekst.
- Generuj tekst, podając różne typy plików, takie jak obrazy, pliki PDF, filmy i pliki audio.
Dowiedz się, jak kontrolować generowanie treści
- Poznaj projektowanie promptów, w tym sprawdzone metody, strategie i przykładowe prompty.
- Skonfiguruj parametry modelu, takie jak temperatura i maksymalna liczba tokenów wyjściowych (w przypadku Gemini) lub format obrazu i generowanie osób (w przypadku Imagen).
- Użyj ustawień bezpieczeństwa, aby dostosować prawdopodobieństwo otrzymania odpowiedzi, które mogą być uznane za szkodliwe.
Więcej informacji o obsługiwanych modelach
Dowiedz się więcej o modelach dostępnych w różnych przypadkach użycia, ich limitach i cenach.Prześlij opinię o korzystaniu z usługi Firebase AI Logic