
इस पेज पर, क्वेरी की परफ़ॉर्मेंस का पता लगाने और उसका विश्लेषण करने के लिए, क्वेरी की अहम जानकारी वाले डैशबोर्ड का इस्तेमाल करने का तरीका बताया गया है.
क्वेरी की अहम जानकारी के बारे में खास जानकारी
मेट्रिक से जुड़ी क्वेरी को मॉनिटर करने के लिए, क्वेरी की अहम जानकारी वाले डैशबोर्ड का इस्तेमाल करें. मेट्रिक के आधार पर, सबसे ज़्यादा इस्तेमाल की जाने वाली क्वेरी और ज़्यादा समय लेने वाली क्वेरी की पहचान की जा सकती है. इन क्वेरी को ऑप्टिमाइज़ करने की ज़रूरत हो सकती है. क्वेरी की अहम जानकारी वाले डैशबोर्ड का इस्तेमाल करके, इन कामों में मदद पाएं:
- क्वेरी की परफ़ॉर्मेंस ऑप्टिमाइज़ेशन: ऐसी क्वेरी की पहचान करें जिनमें ज़्यादा समय लगता है और जिन्हें ऑप्टिमाइज़ करने की ज़रूरत हो सकती है.
- क्वेरी की लागत को मैनेज करना: ज़्यादा लागत वाली क्वेरी ढूंढें और लागत कम करने के लिए उन्हें ऑप्टिमाइज़ करें.
- क्वेरी के आंकड़ों पर नज़र रखना: समय के साथ क्वेरी के आंकड़ों को ट्रैक करें.
क्वेरी की अहम जानकारी का डेटा
क्वेरी की अहम जानकारी में, यहां दी गई एपीआई के तरीकों का डेटा शामिल होता है:
findaggregate
किसी प्रोजेक्ट, डेटाबेस, और 10 मिनट से लेकर 30 दिनों तक की समयावधि के लिए, इन तरीकों का इस्तेमाल करने वाली क्वेरी का डेटा देखा जा सकता है. एक जैसे स्ट्रक्चर वाली क्वेरी का डेटा, एक ही सामान्य क्वेरी में कैप्चर किया जाता है.
क्वेरी की अहम जानकारी से, किसी क्वेरी के बारे में यह जानकारी मिलती है:
| सामान्य किया गया क्वेरी टेक्स्ट | क्वेरी का स्ट्रक्चर, टेक्स्ट के तौर पर दिखाया गया है. |
| प्रोग्राम चलाने की संख्या | चुनी गई समयावधि में, एक्ज़ीक्यूशन की संख्या. |
| गड़बड़ी की संख्या | चुनी गई समयावधि में गड़बड़ियों की संख्या. |
| औसत एक्ज़ीक्यूशन अवधि(मि॰से॰) | क्वेरी को प्रोसेस करने में डेटाबेस को लगने वाला औसत समय, मिलीसेकंड में. |
| औसतन कितने नतीजे मिले | क्वेरी के जवाब में मिले नतीजों की संख्या. नतीजों में दस्तावेज़, कलेक्शन आईडी, और एग्रीगेट किए गए बकेट शामिल होते हैं. |
| स्कैन किए गए दस्तावेज़ों की औसत संख्या | किसी क्वेरी में स्कैन किए गए दस्तावेज़ों की संख्या. |
| स्कैन की गई इंडेक्स एंट्री की औसत संख्या | क्वेरी को चलाने के लिए, इंडेक्स की कितनी एंट्री की जांच की गई. |
| औसत समय के हिसाब से लोड करना | औसत लेटेन्सी के आधार पर, सबसे ज़्यादा खोजी गई क्वेरी को फ़िल्टर करने में मदद करने वाला डेटा. |
| कुल (बिल करने लायक) रीड ऑपरेशन के हिसाब से लोड | इस डेटा की मदद से, बिल की जाने वाली रीड कार्रवाइयों की कुल संख्या के आधार पर, सबसे ज़्यादा क्वेरी को फ़िल्टर किया जा सकता है. |
डेटा का अंतराल और रखरखाव
डेटा का ब्यौरा, तय की गई अवधि पर निर्भर करता है:
- चार दिन पहले तक के इंटरवल के लिए, 10 मिनट का ग्रेन्यूलैरिटी डेटा
- 30 दिन पहले तक के इंटरवल के लिए, हर घंटे के हिसाब से डेटा
क्वेरी की अहम जानकारी के लिए, डेटा को ज़्यादा से ज़्यादा 30 दिनों तक सेव करके रखा जाता है. हर 10 मिनट का डेटा चार दिनों के लिए और हर घंटे का डेटा 30 दिनों के लिए सेव किया जाता है.
सीमाएं
क्वेरी की अहम जानकारी का डेटा, एक से दो घंटे की देरी से अपडेट होता है.
कीमत
क्वेरी की अहम जानकारी के लिए, कोई अतिरिक्त शुल्क नहीं लिया जाता.
ज़रूरी भूमिकाएं
क्वेरी की अहम जानकारी वाला डैशबोर्ड देखने के लिए, आपको अनुमति चाहिए. इसके लिए, अपने एडमिन से अपने प्रोजेक्ट के लिए, Datastore Viewer (roles/datastore.viewer) की IAM भूमिका देने के लिए कहें.
इस पहले से तय की गई भूमिका में datastore.insights.get अनुमति शामिल है. क्वेरी की अहम जानकारी वाला डैशबोर्ड देखने के लिए यह अनुमति ज़रूरी है.
आपको यह अनुमति, कस्टम भूमिकाओं या पहले से तय अन्य भूमिकाओं के ज़रिए भी मिल सकती है.
क्वेरी की अहम जानकारी देखना
Firebase कंसोल
- किसी Cloud Firestore डेटाबेस के लिए क्वेरी की अहम जानकारी देखने के लिए, Google Cloud console में डेटाबेस का क्वेरी की अहम जानकारी वाला पैनल खोलें.
Firebase कंसोल में, Firestore डेटाबेस पेज पर जाएं.
- डेटाबेस की सूची में से कोई डेटाबेस चुनें.
- टैब की सूची में, क्वेरी की अहम जानकारी पर क्लिक करें.
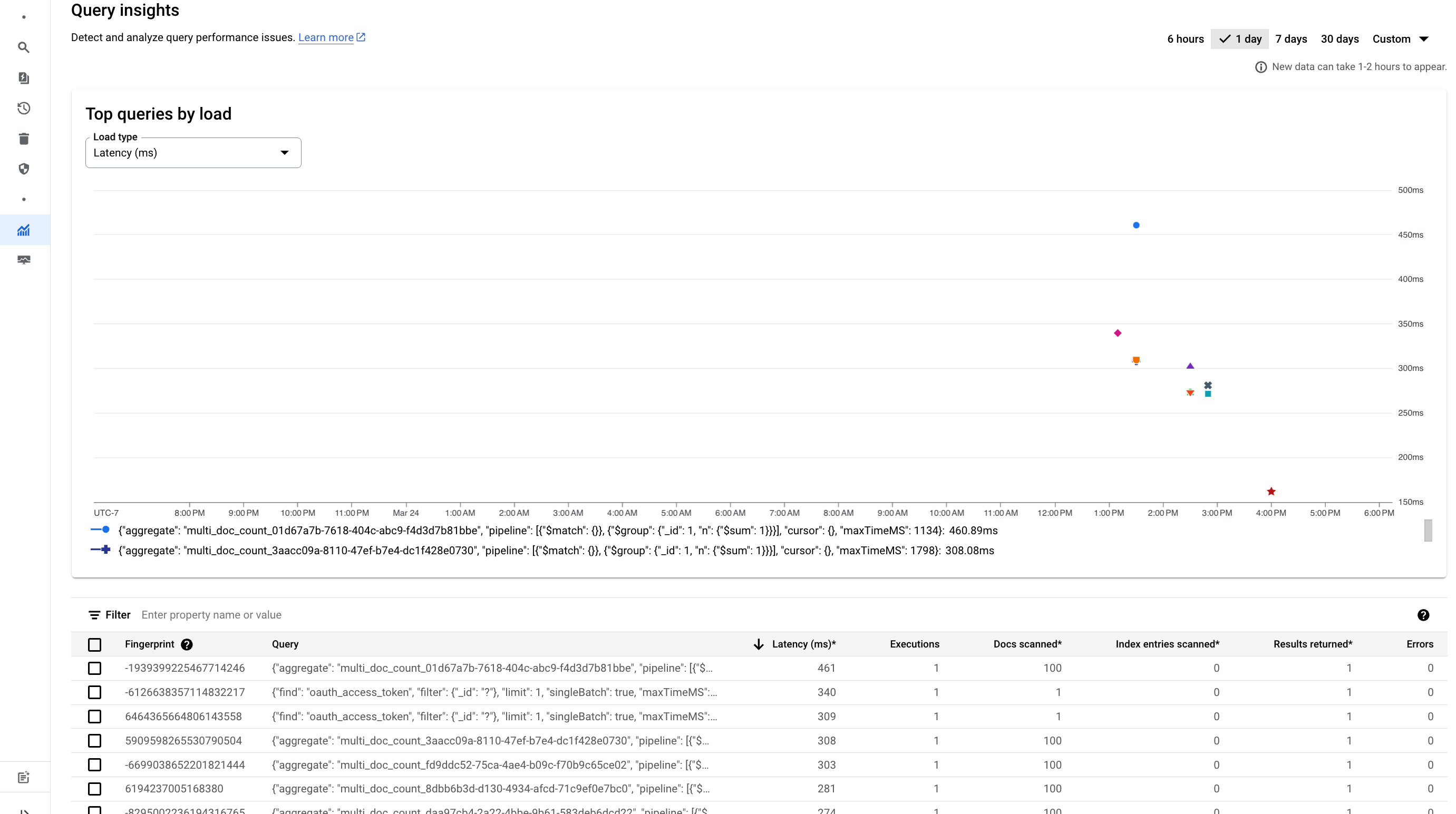
लेटेंसी या रीड ऑपरेशन की संख्या के आधार पर सबसे ज़्यादा क्वेरी देखने के लिए, लेटेंसी या रीड ऑपरेशन पर क्लिक करें.