
আপনার অ্যাপ্লিকেশনগুলোকে উচ্চ পারফরম্যান্স ও নির্ভরযোগ্যতার জন্য ডিজাইন করার বিষয়ে সঠিক সিদ্ধান্ত নিতে এই ডকুমেন্টটি পড়ুন। এই ডকুমেন্টে Cloud Firestore উন্নত বিষয়গুলো অন্তর্ভুক্ত রয়েছে। আপনি যদি Cloud Firestore ব্যবহার সবে শুরু করে থাকেন, তবে এর পরিবর্তে কুইকস্টার্ট গাইডটি দেখুন।
Cloud Firestore হলো ফায়ারবেস এবং Google Cloud তৈরি মোবাইল ডিভাইস, ওয়েব এবং সার্ভার ডেভেলপমেন্টের জন্য একটি নমনীয় ও পরিবর্ধনযোগ্য ডেটাবেস। Cloud Firestore দিয়ে কাজ শুরু করা এবং সমৃদ্ধ ও শক্তিশালী অ্যাপ্লিকেশন তৈরি করা খুবই সহজ।
আপনার ডাটাবেসের আকার এবং ট্র্যাফিক বাড়ার সাথে সাথে অ্যাপ্লিকেশনগুলো যেন ভালোভাবে কাজ করতে থাকে, তা নিশ্চিত করার জন্য Cloud Firestore ব্যাকএন্ডে রিড এবং রাইটের কার্যপ্রণালী বোঝা সহায়ক। এছাড়াও, স্টোরেজ লেয়ারের সাথে আপনার রিড ও রাইটের মিথস্ক্রিয়া এবং পারফরম্যান্সকে প্রভাবিত করতে পারে এমন অন্তর্নিহিত সীমাবদ্ধতাগুলোও আপনাকে বুঝতে হবে।
আপনার অ্যাপ্লিকেশনটির নকশা করার আগে সর্বোত্তম অনুশীলনগুলো জানতে নিম্নলিখিত বিভাগগুলো দেখুন।
উচ্চ স্তরের উপাদানগুলি বুঝুন
নিম্নলিখিত ডায়াগ্রামটি একটি Cloud Firestore এপিআই অনুরোধের সাথে জড়িত উচ্চ-স্তরের উপাদানগুলো দেখায়।
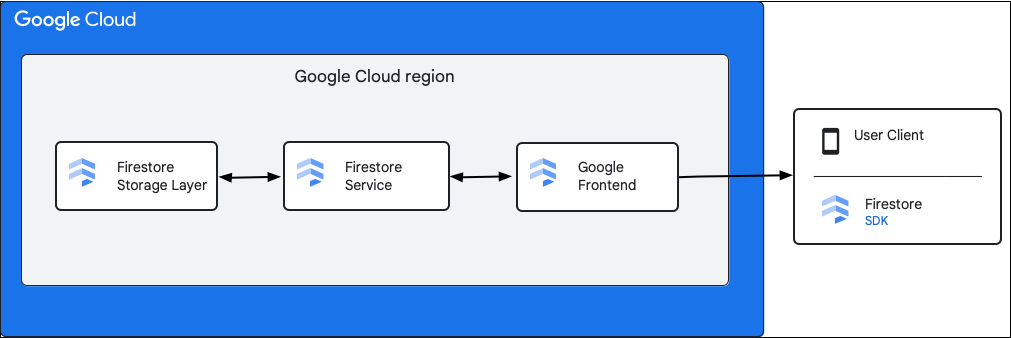
Cloud Firestore এসডিকে এবং ক্লায়েন্ট লাইব্রেরি
Cloud Firestore বিভিন্ন প্ল্যাটফর্মের জন্য এসডিকে (SDK) এবং ক্লায়েন্ট লাইব্রেরি সমর্থন করে। যদিও একটি অ্যাপ সরাসরি Cloud Firestore এপিআই-তে এইচটিটিপি (HTTP) এবং আরপিসি (RPC) কল করতে পারে, ক্লায়েন্ট লাইব্রেরিগুলো এপিআই-এর ব্যবহার সহজ করতে এবং সর্বোত্তম অনুশীলনগুলো বাস্তবায়ন করার জন্য একটি অ্যাবস্ট্রাকশন লেয়ার প্রদান করে। এগুলো অফলাইন অ্যাক্সেস, ক্যাশে ইত্যাদির মতো অতিরিক্ত বৈশিষ্ট্যও প্রদান করতে পারে।
গুগল ফ্রন্ট এন্ড (জিএফই)
এটি সকল গুগল ক্লাউড পরিষেবার জন্য একটি সাধারণ অবকাঠামোগত পরিষেবা। জিএফই আগত অনুরোধ গ্রহণ করে এবং সেগুলোকে প্রাসঙ্গিক গুগল পরিষেবাতে (এই প্রসঙ্গে Cloud Firestore পরিষেবা) পাঠিয়ে দেয়। এটি ডিনায়াল অফ সার্ভিস আক্রমণের বিরুদ্ধে সুরক্ষাসহ অন্যান্য গুরুত্বপূর্ণ কার্যকারিতাও প্রদান করে।
Cloud Firestore পরিষেবা
Cloud Firestore পরিষেবাটি এপিআই অনুরোধের উপর বিভিন্ন যাচাই-বাছাই করে, যার মধ্যে প্রমাণীকরণ, অনুমোদন, কোটা যাচাই এবং নিরাপত্তা নিয়মাবলী অন্তর্ভুক্ত থাকে, এবং এটি লেনদেনও পরিচালনা করে। এই Cloud Firestore পরিষেবাটিতে একটি স্টোরেজ ক্লায়েন্ট রয়েছে যা ডেটা পড়া এবং লেখার জন্য স্টোরেজ লেয়ারের সাথে যোগাযোগ করে।
Cloud Firestore স্টোরেজ লেয়ার
Cloud Firestore স্টোরেজ লেয়ার ডেটা ও মেটাডেটা এবং Cloud Firestore দ্বারা প্রদত্ত সংশ্লিষ্ট ডেটাবেস ফিচারগুলো সংরক্ষণের জন্য দায়ী। নিম্নলিখিত বিভাগগুলিতে বর্ণনা করা হয়েছে Cloud Firestore স্টোরেজ লেয়ারে ডেটা কীভাবে সাজানো হয় এবং সিস্টেমটি কীভাবে স্কেল করে। ডেটা কীভাবে সাজানো হয় সে সম্পর্কে জানা আপনাকে একটি স্কেলেবল ডেটা মডেল ডিজাইন করতে এবং Cloud Firestore সেরা অনুশীলনগুলো আরও ভালোভাবে বুঝতে সাহায্য করতে পারে।
মূল পরিসর এবং বিভাজন
Cloud Firestore একটি NoSQL, ডকুমেন্ট-ভিত্তিক ডেটাবেস। আপনি ডকুমেন্টগুলিতে ডেটা সংরক্ষণ করেন, যা কালেকশনের হায়ারার্কিতে সাজানো থাকে। কালেকশন হায়ারার্কি এবং ডকুমেন্ট আইডি প্রতিটি ডকুমেন্টের জন্য একটি একক কী-তে রূপান্তরিত হয়। ডকুমেন্টগুলি এই একক কী দ্বারা যৌক্তিকভাবে সংরক্ষিত এবং লেক্সিকোগ্রাফিকভাবে সাজানো থাকে। আমরা কী-গুলির একটি লেক্সিকোগ্রাফিকভাবে সংলগ্ন পরিসরকে বোঝাতে 'কী রেঞ্জ' শব্দটি ব্যবহার করি।
একটি সাধারণ Cloud Firestore ডেটাবেস এতটাই বড় যে তা একটিমাত্র ফিজিক্যাল মেশিনে রাখা সম্ভব নয়। এমন পরিস্থিতিও তৈরি হয় যেখানে ডেটার উপর কাজের চাপ এতটাই বেশি থাকে যে একটি মেশিনের পক্ষে তা সামলানো সম্ভব হয় না। বিপুল পরিমাণ কাজের চাপ সামলানোর জন্য, Cloud Firestore ডেটাকে আলাদা আলাদা অংশে বিভক্ত করে, যা একাধিক মেশিন বা স্টোরেজ সার্ভারে সংরক্ষণ ও পরিবেশন করা যায়। এই বিভাজনগুলো ডেটাবেস টেবিলের উপর কী-রেঞ্জের ব্লক আকারে করা হয়, যেগুলোকে স্প্লিট বলা হয়।
সিঙ্ক্রোনাস প্রতিলিপি
এটা মনে রাখা গুরুত্বপূর্ণ যে ডাটাবেসটি সর্বদা স্বয়ংক্রিয়ভাবে এবং সিনক্রোনাসভাবে রেপ্লিকেট করা হয়। ডেটার স্প্লিটগুলোর বিভিন্ন জোনে রেপ্লিকা থাকে, যাতে কোনো একটি জোন অ্যাক্সেসযোগ্য না হলেও সেগুলো উপলব্ধ থাকে। স্প্লিটের বিভিন্ন কপিতে সামঞ্জস্যপূর্ণ রেপ্লিকেশন কনসেনসাসের জন্য প্যাক্সোস অ্যালগরিদম দ্বারা পরিচালিত হয়। প্রতিটি স্প্লিটের একটি রেপ্লিকাকে প্যাক্সোস লিডার হিসেবে নির্বাচিত করা হয়, যা সেই স্প্লিটে রাইট পরিচালনার জন্য দায়ী। সিনক্রোনাস রেপ্লিকেশন আপনাকে Cloud Firestore থেকে সর্বদা ডেটার সর্বশেষ সংস্করণ পড়ার ক্ষমতা দেয়।
এর সামগ্রিক ফল হলো একটি স্কেলেবল ও অত্যন্ত নির্ভরযোগ্য সিস্টেম, যা ভারী ওয়ার্কলোড এবং খুব বৃহৎ পরিসর নির্বিশেষে রিড ও রাইট উভয়ের জন্যই স্বল্প ল্যাটেন্সি প্রদান করে।
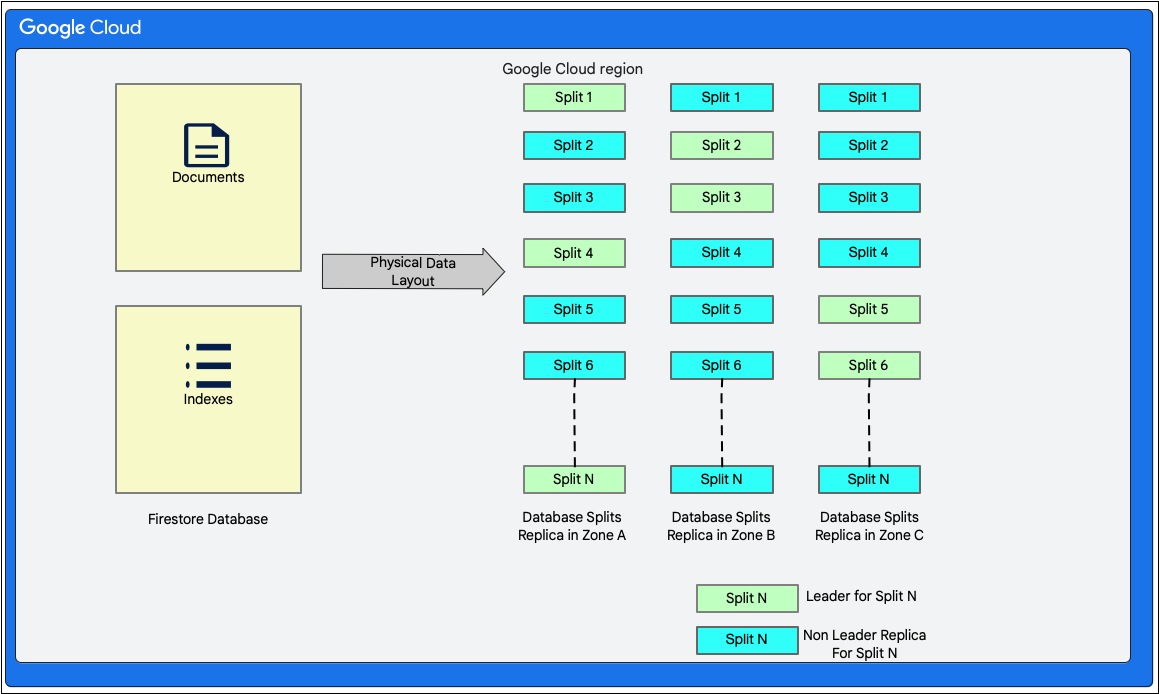
ডেটা বিন্যাস
Cloud Firestore একটি স্কিমাবিহীন ডকুমেন্ট ডেটাবেস। তবে, অভ্যন্তরীণভাবে এটি তার স্টোরেজ লেয়ারে প্রধানত দুটি রিলেশনাল ডেটাবেস-ধাঁচের টেবিলে ডেটা সাজিয়ে রাখে, যা নিম্নরূপ:
- ডকুমেন্টস টেবিল: এই টেবিলে ডকুমেন্টগুলো সংরক্ষণ করা হয়।
- ইনডেক্স টেবিল: এই টেবিলে সেইসব ইনডেক্স এন্ট্রি সংরক্ষণ করা হয়, যা ইনডেক্স মান অনুসারে দক্ষতার সাথে ও সাজিয়ে ফলাফল পেতে সাহায্য করে।
নিম্নলিখিত ডায়াগ্রামটি দেখায় যে স্প্লিটগুলো সহ একটি Cloud Firestore ডাটাবেসের টেবিলগুলো কেমন দেখতে হতে পারে। স্প্লিটগুলো তিনটি ভিন্ন জোনে রেপ্লিকেট করা হয় এবং প্রতিটি স্প্লিটের জন্য একজন প্যাক্সোস লিডার নিযুক্ত থাকে।
একক অঞ্চল বনাম বহু-অঞ্চল
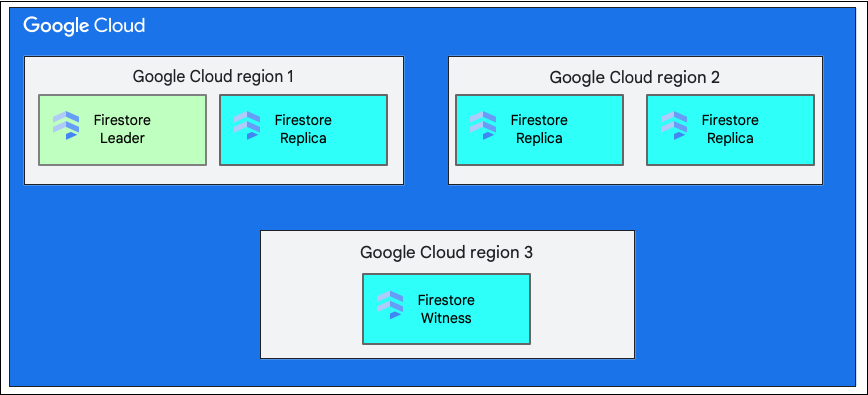
ডাটাবেস তৈরি করার সময়, আপনাকে অবশ্যই একটি অঞ্চল অথবা একাধিক অঞ্চল নির্বাচন করতে হবে।
একটি একক আঞ্চলিক অবস্থান হলো একটি নির্দিষ্ট ভৌগোলিক অবস্থান, যেমন us-west1 । পূর্বে ব্যাখ্যা করা অনুযায়ী, একটি Cloud Firestore ডেটাবেসের ডেটার বিভাজনগুলোর নির্বাচিত অঞ্চলের মধ্যে বিভিন্ন জোনে রেপ্লিকা থাকে।
একটি মাল্টি-রিজিওন লোকেশন হলো কয়েকটি নির্দিষ্ট অঞ্চলের সমষ্টি, যেখানে ডাটাবেসের রেপ্লিকাগুলো সংরক্ষিত থাকে। Cloud Firestore একটি মাল্টি-রিজিওন ডেপ্লয়মেন্টে, দুটি অঞ্চলে ডাটাবেসের সম্পূর্ণ ডেটার পূর্ণাঙ্গ রেপ্লিকা থাকে। তৃতীয় একটি অঞ্চলে একটি উইটনেস রেপ্লিকা থাকে, যা সম্পূর্ণ ডেটা সেট সংরক্ষণ করে না, কিন্তু রেপ্লিকেশনে অংশগ্রহণ করে। একাধিক অঞ্চলের মধ্যে ডেটা রেপ্লিকেট করার ফলে, একটি সম্পূর্ণ অঞ্চল নষ্ট হয়ে গেলেও ডেটা লেখা এবং পড়া সম্ভব হয়।
কোনো অঞ্চলের অবস্থান সম্পর্কে আরও তথ্যের জন্য, Cloud Firestore অবস্থানসমূহ দেখুন।
Cloud Firestore রাইট-ইন-এর জীবনচক্র বুঝুন
একটি Cloud Firestore ক্লায়েন্ট একটিমাত্র ডকুমেন্ট তৈরি, আপডেট বা ডিলিট করার মাধ্যমে ডেটা লিখতে পারে। একটিমাত্র ডকুমেন্টে লেখার জন্য স্টোরেজ লেয়ারে ডকুমেন্টটি এবং এর সাথে যুক্ত ইনডেক্স এন্ট্রি উভয়কেই অ্যাটমিকভাবে আপডেট করতে হয়। Cloud Firestore এক বা একাধিক ডকুমেন্টে একাধিকবার রিড এবং/অথবা রাইট করার অ্যাটমিক অপারেশনও সমর্থন করে।
সব ধরনের রাইট অপারেশনের জন্য, Cloud Firestore রিলেশনাল ডেটাবেসের ACID বৈশিষ্ট্যগুলো (অ্যাটোমিসিসিটি, কনসিসটেন্সি, আইসোলেশন এবং ডিউরেবিলিটি) প্রদান করে। Cloud Firestore সিরিয়ালাইজেবিলিটিও প্রদান করে, যার অর্থ হলো সমস্ত ট্রানজ্যাকশন এমনভাবে প্রদর্শিত হয় যেন সেগুলো একটি ক্রমিক ক্রমে সম্পাদিত হয়েছে।
একটি রাইট ট্রানজ্যাকশনের উচ্চ-স্তরের ধাপসমূহ
যখন Cloud Firestore ক্লায়েন্ট পূর্বে উল্লিখিত যেকোনো পদ্ধতি ব্যবহার করে একটি রাইট বা ট্রানজ্যাকশন কমিট করে, তখন অভ্যন্তরীণভাবে এটি স্টোরেজ লেয়ারে একটি ডাটাবেস রিড-রাইট ট্রানজ্যাকশন হিসেবে সম্পাদিত হয়। এই ট্রানজ্যাকশনটি Cloud Firestore পূর্বে উল্লিখিত ACID বৈশিষ্ট্যগুলো প্রদান করতে সক্ষম করে।
একটি লেনদেনের প্রথম ধাপ হিসেবে, Cloud Firestore বিদ্যমান ডকুমেন্টটি পড়ে এবং ডকুমেন্টস টেবিলের ডেটাতে যে পরিবর্তনগুলো করতে হবে তা নির্ধারণ করে।
এর মধ্যে ইনডেক্স টেবিলে নিম্নরূপ প্রয়োজনীয় আপডেট করাও অন্তর্ভুক্ত:
- ডকুমেন্টগুলিতে যে ফিল্ডগুলি যোগ করা হচ্ছে, সেগুলির জন্য ইনডেক্স টেবিলে সংশ্লিষ্ট ইনসার্ট প্রয়োজন।
- ডকুমেন্ট থেকে যে ফিল্ডগুলো সরানো হচ্ছে, ইনডেক্স টেবিলেও সেগুলোর অনুরূপ ডিলিট কমান্ড চালাতে হবে।
- ডকুমেন্টে যে ফিল্ডগুলো পরিবর্তন করা হচ্ছে, সেগুলোর জন্য ইনডেক্স টেবিলে পুরোনো ভ্যালু ডিলিট এবং নতুন ভ্যালু ইনসার্ট—উভয়ই করার প্রয়োজন হয়।
পূর্বে উল্লিখিত মিউটেশনগুলি গণনা করার জন্য, Cloud Firestore প্রজেক্টের ইনডেক্সিং কনফিগারেশন পড়ে। ইনডেক্সিং কনফিগারেশন একটি প্রজেক্টের ইনডেক্সগুলি সম্পর্কে তথ্য সংরক্ষণ করে। Cloud Firestore দুই ধরনের ইনডেক্স ব্যবহার করে: সিঙ্গেল-ফিল্ড এবং কম্পোজিট। Cloud Firestore তৈরি ইনডেক্সগুলি সম্পর্কে বিস্তারিত জানতে, Cloud Firestore ইনডেক্সের প্রকারভেদ দেখুন।
মিউটেশনগুলো গণনা করা হয়ে গেলে, Cloud Firestore সেগুলোকে একটি ট্রানজ্যাকশনের মধ্যে সংগ্রহ করে এবং তারপর কমিট করে।
স্টোরেজ লেয়ারে একটি রাইট ট্রানজ্যাকশন বুঝুন
পূর্বে যেমন আলোচনা করা হয়েছে, Cloud Firestore একটি রাইট অপারেশন স্টোরেজ লেয়ারে একটি রিড-রাইট ট্রানজ্যাকশনকে বোঝায়। ডেটার বিন্যাসের উপর নির্ভর করে, একটি রাইট অপারেশনে এক বা একাধিক স্প্লিট অন্তর্ভুক্ত থাকতে পারে, যেমনটি ডেটা লেআউটে দেখা যায়।
নিম্নলিখিত ডায়াগ্রামে, Cloud Firestore ডাটাবেসটিতে আটটি স্প্লিট (১-৮ চিহ্নিত) রয়েছে, যা একটিমাত্র জোনের তিনটি ভিন্ন স্টোরেজ সার্ভারে হোস্ট করা আছে এবং প্রতিটি স্প্লিট ৩ (বা তার বেশি) ভিন্ন জোনে রেপ্লিকেট করা আছে। প্রতিটি স্প্লিটের একজন প্যাক্সোস লিডার রয়েছে, যিনি বিভিন্ন স্প্লিটের জন্য ভিন্ন ভিন্ন জোনে থাকতে পারেন।
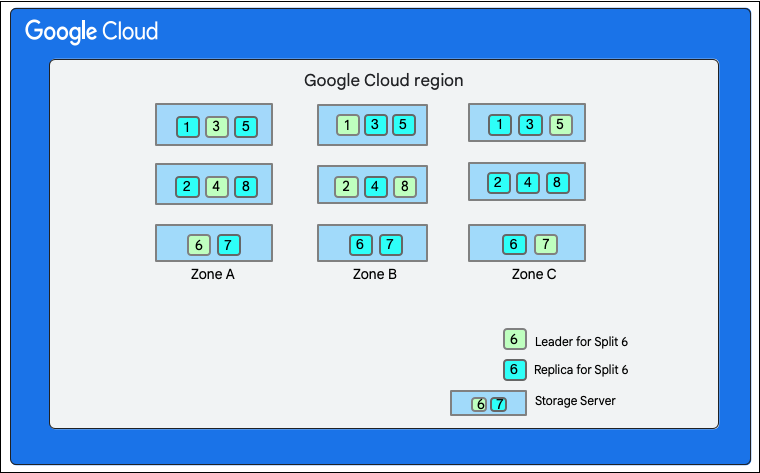 ক্লাউড ফায়ারস্টোর ডেটাবেস বিভক্ত">
ক্লাউড ফায়ারস্টোর ডেটাবেস বিভক্ত">
একটি Cloud Firestore ডাটাবেস বিবেচনা করুন যেখানে Restaurants কালেকশনটি নিম্নরূপ:
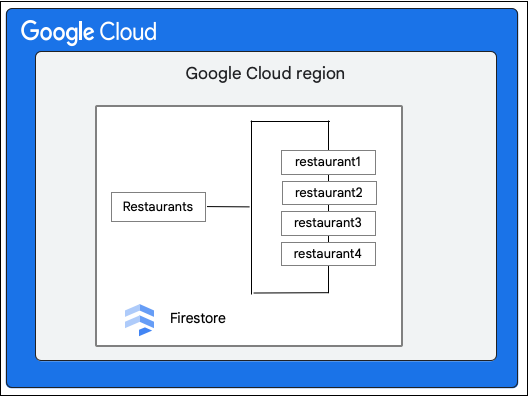
Cloud Firestore ক্লায়েন্ট Restaurant কালেকশনের একটি ডকুমেন্টের priceCategory ফিল্ডের মান আপডেট করার মাধ্যমে নিম্নলিখিত পরিবর্তনটি অনুরোধ করে।
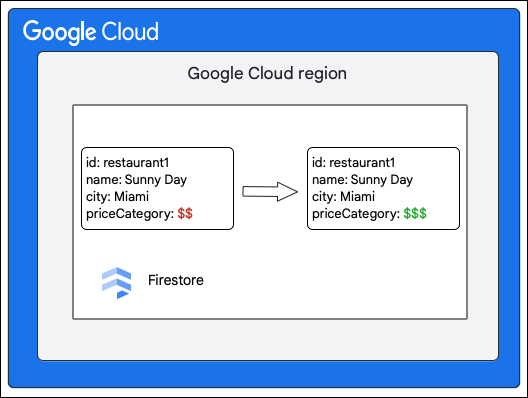
নিম্নলিখিত উচ্চ-স্তরের ধাপগুলোতে লেখার অংশ হিসেবে কী ঘটে তা বর্ণনা করা হয়েছে:
- একটি পঠন-লিখন লেনদেন তৈরি করুন।
- স্টোরেজ লেয়ারের ডকুমেন্টস টেবিল থেকে
Restaurantsকালেকশনের অন্তর্গতrestaurant1ডকুমেন্টটি পড়ুন। - ইনডেক্স টেবিল থেকে ডকুমেন্টটির ইনডেক্সগুলো পড়ুন।
- ডেটাতে যে পরিবর্তনগুলো করতে হবে তা গণনা করুন। এক্ষেত্রে, পাঁচটি পরিবর্তন রয়েছে:
- M1:
priceCategoryফিল্ডের মানের পরিবর্তন প্রতিফলিত করতে `Documents` টেবিলে `restaurant1এর সারিটি আপডেট করুন। - M2 এবং M3: Indexes টেবিলের ডিসেন্ডিং এবং অ্যাসেন্ডিং ইনডেক্সগুলোর জন্য
priceCategoryএর পুরোনো মানের সারিগুলো মুছে ফেলুন। - M4 এবং M5: indexes টেবিলে ডিসেন্ডিং এবং অ্যাসেন্ডিং ইনডেক্সের জন্য
priceCategoryএর নতুন মানের সারিগুলো সন্নিবেশ করুন।
- M1:
- এই মিউটেশনগুলো সংঘটিত করুন।
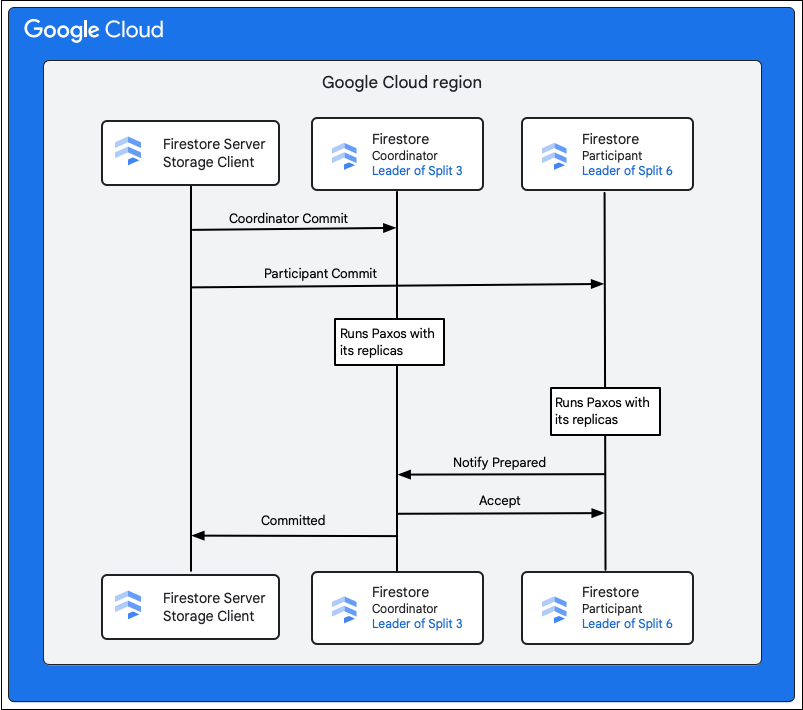
Cloud Firestore সার্ভিসের স্টোরেজ ক্লায়েন্ট পরিবর্তনযোগ্য সারিগুলোর কী-গুলোর মালিকানা থাকা স্প্লিটগুলোকে খুঁজে বের করে। ধরা যাক, স্প্লিট ৩ M1-কে এবং স্প্লিট ৬ M2-M5-কে পরিষেবা দেয়। এখানে একটি ডিস্ট্রিবিউটেড ট্রানজ্যাকশন রয়েছে, যেখানে এই সমস্ত স্প্লিট অংশগ্রহণকারী হিসেবে জড়িত। অংশগ্রহণকারী স্প্লিটগুলোর মধ্যে এমন যেকোনো স্প্লিটও অন্তর্ভুক্ত থাকতে পারে, যেখান থেকে রিড-রাইট ট্রানজ্যাকশনের অংশ হিসেবে পূর্বে ডেটা পড়া হয়েছিল।
কমিট প্রক্রিয়ার অংশ হিসেবে কী ঘটে, তা নিম্নলিখিত ধাপগুলিতে বর্ণনা করা হয়েছে:
- স্টোরেজ ক্লায়েন্ট একটি কমিট জারি করে। কমিটটিতে M1-M5 মিউটেশনগুলো রয়েছে।
- স্প্লিট ৩ এবং ৬ এই ট্রানজ্যাকশনের অংশগ্রহণকারী। অংশগ্রহণকারীদের মধ্যে একজনকে, যেমন স্প্লিট ৩-কে, কোঅর্ডিনেটর হিসেবে বেছে নেওয়া হয়। কোঅর্ডিনেটরের কাজ হলো সকল অংশগ্রহণকারীর মধ্যে ট্রানজ্যাকশনটি যেন অ্যাটমিকভাবে কমিট বা অ্যাবোর্ট হয়, তা নিশ্চিত করা।
- এই বিভাজনগুলোর নেতা প্রতিনিধিরা অংশগ্রহণকারী এবং সমন্বয়কারীদের দ্বারা সম্পাদিত কাজের জন্য দায়ী।
- প্রত্যেক অংশগ্রহণকারী এবং সমন্বয়কারী তাদের নিজ নিজ রেপ্লিকা ব্যবহার করে একটি প্যাক্সোস অ্যালগরিদম চালান।
- লিডার রেপ্লিকাগুলোর সাথে একটি প্যাক্সোস অ্যালগরিদম চালায়। অধিকাংশ রেপ্লিকা লিডারকে
ok to commitউত্তর দিলে কোরাম অর্জিত হয়। - এরপর প্রত্যেক অংশগ্রহণকারী প্রস্তুত হলে সমন্বয়কারীকে জানায় (টু-ফেজ কমিটের প্রথম পর্যায়)। যদি কোনো অংশগ্রহণকারী ট্রানজ্যাকশনটি কমিট করতে না পারে, তাহলে পুরো ট্রানজ্যাকশনটি
aborts।
- লিডার রেপ্লিকাগুলোর সাথে একটি প্যাক্সোস অ্যালগরিদম চালায়। অধিকাংশ রেপ্লিকা লিডারকে
- যখন কোঅর্ডিনেটর জানতে পারে যে সে নিজে সহ সকল অংশগ্রহণকারী প্রস্তুত, তখন এটি সকল অংশগ্রহণকারীকে ট্রানজ্যাকশন
acceptফলাফলটি জানিয়ে দেয় (টু-ফেজ কমিটের দ্বিতীয় পর্যায়)। এই পর্যায়ে, প্রতিটি অংশগ্রহণকারী স্টেবল স্টোরেজে কমিটের সিদ্ধান্তটি রেকর্ড করে এবং ট্রানজ্যাকশনটি কমিট করা হয়। - কোঅর্ডিনেটর Cloud Firestore স্টোরেজ ক্লায়েন্টকে জানায় যে ট্রানজ্যাকশনটি কমিট করা হয়েছে। একই সাথে, কোঅর্ডিনেটর এবং সমস্ত পার্টিসিপ্যান্ট ডেটার উপর পরিবর্তনগুলো প্রয়োগ করে।
যখন Cloud Firestore ডাটাবেস ছোট হয়, তখন এমন হতে পারে যে একটিমাত্র স্প্লিট M1-M5 মিউটেশনগুলোর সমস্ত কী-এর মালিক। এমন ক্ষেত্রে, ট্রানজ্যাকশনে কেবল একজন অংশগ্রহণকারী থাকে এবং পূর্বে উল্লিখিত টু-ফেজ কমিটের প্রয়োজন হয় না, ফলে রাইট অপারেশনগুলো আরও দ্রুত হয়।
বহু-অঞ্চলে লেখেন
একাধিক অঞ্চলের ডেপ্লয়মেন্টে, বিভিন্ন অঞ্চলে রেপ্লিকাগুলোর বিস্তার প্রাপ্যতা বাড়ায়, কিন্তু এর জন্য পারফরম্যান্সে কিছুটা ঘাটতি দেখা দেয়। বিভিন্ন অঞ্চলের রেপ্লিকাগুলোর মধ্যে যোগাযোগের জন্য বেশি রাউন্ড ট্রিপ টাইম লাগে। তাই, একক অঞ্চলের ডেপ্লয়মেন্টের তুলনায় Cloud Firestore অপারেশনের বেসলাইন ল্যাটেন্সি কিছুটা বেশি হয়।
আমরা রেপ্লিকাগুলোকে এমনভাবে কনফিগার করি যাতে স্প্লিট-এর জন্য লিডারশিপ সবসময় প্রাইমারি রিজিয়নে থাকে। প্রাইমারি রিজিয়ন হলো সেটি, যেখান থেকে Cloud Firestore সার্ভারে ট্র্যাফিক আসে। লিডারশিপের এই সিদ্ধান্তটি Cloud Firestore স্টোরেজ ক্লায়েন্ট এবং রেপ্লিকা লিডারের (অথবা মাল্টি-স্প্লিট ট্রানজ্যাকশনের জন্য কোঅর্ডিনেটর) মধ্যে যোগাযোগের রাউন্ড-ট্রিপ ডিলে কমিয়ে দেয়।
Cloud Firestore Cloud Firestore রাইট অপারেশনের সাথে এর রিয়েল-টাইম ইঞ্জিনেরও কিছু মিথস্ক্রিয়া জড়িত থাকে। রিয়েল-টাইম কোয়েরি সম্পর্কে আরও তথ্যের জন্য, "আন্ডারস্ট্যান্ড রিয়েল-টাইম কোয়েরিস অ্যাট স্কেল" দেখুন।
Cloud Firestore একটি রিডের জীবনচক্র বুঝুন
এই অংশে Cloud Firestore স্বতন্ত্র, নন-রিয়েলটাইম রিড নিয়ে বিস্তারিত আলোচনা করা হয়েছে। অভ্যন্তরীণভাবে, Cloud Firestore সার্ভার এই কোয়েরিগুলোর বেশিরভাগই দুটি প্রধান পর্যায়ে পরিচালনা করে:
- ইনডেক্স টেবিলের উপর একটি একক রেঞ্জ স্ক্যান
- পূর্ববর্তী স্ক্যানের ফলাফলের উপর ভিত্তি করে ডকুমেন্টস টেবিলে পয়েন্ট অনুসন্ধান।
স্টোরেজ লেয়ার থেকে ডেটা রিড করার কাজটি অভ্যন্তরীণভাবে একটি ডাটাবেস ট্রানজ্যাকশন ব্যবহার করে করা হয়, যা সামঞ্জস্যপূর্ণ রিড নিশ্চিত করে। তবে, রাইটের জন্য ব্যবহৃত ট্রানজ্যাকশনের মতো নয়, এই ট্রানজ্যাকশনগুলো লক নেয় না। এর পরিবর্তে, এগুলো একটি টাইমস্ট্যাম্প বেছে নিয়ে কাজ করে এবং তারপর সেই টাইমস্ট্যাম্পে সমস্ত রিড সম্পাদন করে। যেহেতু এগুলো লক গ্রহণ করে না, তাই এগুলো যুগপৎ রিড-রাইট ট্রানজ্যাকশনকে বাধা দেয় না। এই ট্রানজ্যাকশনটি সম্পাদন করার জন্য, Cloud Firestore স্টোরেজ ক্লায়েন্ট একটি টাইমস্ট্যাম্প বাউন্ড নির্দিষ্ট করে, যা স্টোরেজ লেয়ারকে বলে দেয় কীভাবে একটি রিড টাইমস্ট্যাম্প বেছে নিতে হবে। Cloud Firestore স্টোরেজ ক্লায়েন্ট দ্বারা নির্বাচিত টাইমস্ট্যাম্প বাউন্ডের ধরনটি রিড রিকোয়েস্টের রিড অপশন দ্বারা নির্ধারিত হয়।
স্টোরেজ লেয়ারে একটি রিড ট্রানজ্যাকশন বুঝুন
এই অংশে বিভিন্ন ধরণের রিড এবং Cloud Firestore স্টোরেজ লেয়ারে সেগুলি কীভাবে প্রসেস করা হয়, তা বর্ণনা করা হয়েছে।
শক্তিশালী পাঠ
ডিফল্টরূপে, Cloud Firestore রিডগুলো স্ট্রংলি কনসিস্টেন্ট হয়। এই স্ট্রং কনসিস্টেন্সির অর্থ হলো, একটি Cloud Firestore রিড ডেটার সর্বশেষ সংস্করণটি ফেরত দেয়, যা রিড শুরু হওয়ার আগ পর্যন্ত কমিট করা সমস্ত রাইটকে প্রতিফলিত করে।
একক বিভক্ত পাঠ
Cloud Firestore স্টোরেজ ক্লায়েন্ট যে সারিগুলো পড়তে হবে, সেগুলোর কী-গুলো যে স্প্লিটগুলোর কাছে থাকে, সেগুলোকে খুঁজে বের করে। ধরা যাক, এটিকে আগের অংশের স্প্লিট ৩ থেকে ডেটা পড়তে হবে। রাউন্ড ট্রিপ ল্যাটেন্সি কমানোর জন্য ক্লায়েন্টটি নিকটতম রেপ্লিকাতে রিড রিকোয়েস্ট পাঠায়।
এই পর্যায়ে, নির্বাচিত প্রতিরূপের উপর নির্ভর করে নিম্নলিখিত ঘটনাগুলো ঘটতে পারে:
- রিড রিকোয়েস্ট একটি লিডার রেপ্লিকা (জোন A)-তে যায়।
- যেহেতু নেতা সর্বদা হালনাগাদ থাকেন, তাই পাঠটি সরাসরি এগিয়ে যেতে পারে।
- রিড রিকোয়েস্ট একটি নন-লিডার রেপ্লিকাতে (যেমন, জোন বি) যায়।
- স্প্লিট ৩ তার অভ্যন্তরীণ অবস্থা থেকে হয়তো জানতে পারে যে রিডটি সম্পন্ন করার জন্য তার কাছে যথেষ্ট তথ্য আছে এবং স্প্লিটটি তা-ই করে।
- স্প্লিট ৩ নিশ্চিত নয় যে এটি সর্বশেষ ডেটা দেখেছে কিনা। রিড প্রক্রিয়াটি সম্পন্ন করার জন্য প্রয়োজনীয় সর্বশেষ ট্রানজ্যাকশনের টাইমস্ট্যাম্প জানতে চেয়ে এটি লিডারের কাছে একটি বার্তা পাঠায়। সেই ট্রানজ্যাকশনটি প্রয়োগ করা হয়ে গেলে, রিড প্রক্রিয়াটি এগিয়ে যেতে পারে।
এরপর Cloud Firestore তার ক্লায়েন্টকে প্রতিক্রিয়াটি ফেরত পাঠায়।
মাল্টি-স্প্লিট রিড
যে পরিস্থিতিতে একাধিক স্প্লিট থেকে ডেটা রিড করতে হয়, সেখানে সমস্ত স্প্লিট জুড়ে একই প্রক্রিয়া কাজ করে। সমস্ত স্প্লিট থেকে ডেটা ফিরে আসার পর, Cloud Firestore স্টোরেজ ক্লায়েন্ট ফলাফলগুলোকে একত্রিত করে। এরপর Cloud Firestore এই ডেটা দিয়ে তার ক্লায়েন্টকে সাড়া দেয়।
পুরনো পাঠ
Cloud Firestore স্ট্রং রিড হলো ডিফল্ট মোড। তবে, লিডারের সাথে প্রয়োজনীয় যোগাযোগের কারণে এর ফলে ল্যাটেন্সি বেড়ে যাওয়ার একটি ঝুঁকি থাকে। প্রায়শই আপনার Cloud Firestore অ্যাপ্লিকেশনের ডেটার সর্বশেষ সংস্করণটি পড়ার প্রয়োজন হয় না এবং এই কার্যকারিতাটি কয়েক সেকেন্ড পুরোনো ডেটার সাথেও ভালোভাবে কাজ করে।
এমন ক্ষেত্রে, ক্লায়েন্ট read_time রিড অপশন ব্যবহার করে পুরনো রিড গ্রহণ করার সিদ্ধান্ত নিতে পারে। এক্ষেত্রে, read_time এ ডেটা যেমন ছিল, সেভাবেই রিড সম্পন্ন করা হয় এবং সবচেয়ে কাছের রেপ্লিকাটির নির্দিষ্ট read_time এ ডেটা আছে কিনা তা ইতোমধ্যেই যাচাই করে ফেলার সম্ভাবনা খুব বেশি থাকে। উল্লেখযোগ্যভাবে উন্নত পারফরম্যান্সের জন্য, ১৫ সেকেন্ড একটি যুক্তিসঙ্গত পুরনো হওয়ার মান। এমনকি পুরনো রিডের ক্ষেত্রেও, প্রাপ্ত সারিগুলো একে অপরের সাথে সামঞ্জস্যপূর্ণ থাকে।
হটস্পট এড়িয়ে চলুন
Cloud Firestore স্প্লিটগুলো স্বয়ংক্রিয়ভাবে ছোট ছোট অংশে বিভক্ত হয়ে যায়, যাতে প্রয়োজনে বা কী স্পেস প্রসারিত হলে ট্র্যাফিক সামলানোর কাজটি আরও বেশি স্টোরেজ সার্ভারে ভাগ করে দেওয়া যায়। অতিরিক্ত ট্র্যাফিক সামলানোর জন্য তৈরি করা স্প্লিটগুলো ট্র্যাফিক চলে গেলেও প্রায় ২৪ ঘণ্টা পর্যন্ত সংরক্ষিত থাকে। তাই, যদি বারবার ট্র্যাফিকের আকস্মিক বৃদ্ধি ঘটে, তাহলে স্প্লিটগুলো বজায় থাকে এবং প্রয়োজন অনুযায়ী আরও স্প্লিট যুক্ত করা হয়। এই পদ্ধতিগুলো Cloud Firestore ডেটাবেসকে ক্রমবর্ধমান ট্র্যাফিক লোড বা ডেটাবেসের আকারের অধীনে স্বয়ংক্রিয়ভাবে স্কেল করতে সাহায্য করে। তবে, এর কিছু সীমাবদ্ধতা রয়েছে যা সম্পর্কে সচেতন থাকা প্রয়োজন, এবং সেগুলো নিচে ব্যাখ্যা করা হলো।
স্টোরেজ এবং লোড ভাগ করতে সময় লাগে, এবং খুব দ্রুত ট্র্যাফিক বাড়ালে সার্ভিসটি মানিয়ে নেওয়ার সময় উচ্চ ল্যাটেন্সি বা ডেডলাইন এক্সিডেড এরর দেখা দিতে পারে, যা সাধারণত হটস্পট নামে পরিচিত। সর্বোত্তম পদ্ধতি হলো, কী রেঞ্জ জুড়ে অপারেশনগুলো ভাগ করে দেওয়া এবং একই সাথে ডাটাবেসের কোনো একটি কালেকশনে প্রতি সেকেন্ডে ৫০০টি অপারেশনের হারে ট্র্যাফিক বাড়ানো। এই ধীরে ধীরে বাড়ানোর পর, প্রতি পাঁচ মিনিটে ট্র্যাফিক ৫০% পর্যন্ত বৃদ্ধি করুন। এই প্রক্রিয়াটিকে ৫০০/৫০/৫ নিয়ম বলা হয় এবং এটি আপনার ওয়ার্কলোড মেটাতে ডাটাবেসকে সর্বোত্তমভাবে স্কেল করার জন্য প্রস্তুত করে।
যদিও লোড বাড়ার সাথে সাথে স্বয়ংক্রিয়ভাবে স্প্লিট তৈরি হয়, Cloud Firestore একটি ডেডিকেটেড রেপ্লিকেটেড স্টোরেজ সার্ভার ব্যবহার করে একটি কী রেঞ্জকে শুধুমাত্র ততক্ষণই বিভক্ত করতে পারে, যতক্ষণ না এটি একটি একক ডকুমেন্ট পরিবেশন করছে। ফলস্বরূপ, একটি একক ডকুমেন্টে উচ্চ এবং দীর্ঘস্থায়ী পরিমাণে যুগপৎ অপারেশন সেই ডকুমেন্টে একটি হটস্পট তৈরি করতে পারে। যদি আপনি একটি একক ডকুমেন্টে দীর্ঘস্থায়ী উচ্চ ল্যাটেন্সি অনুভব করেন, তবে একাধিক ডকুমেন্টের মধ্যে ডেটা বিভক্ত বা রেপ্লিকেট করার জন্য আপনার ডেটা মডেল পরিবর্তন করার কথা বিবেচনা করা উচিত।
যখন একাধিক অপারেশন একই সাথে একই ডকুমেন্ট পড়তে এবং/অথবা লিখতে চেষ্টা করে, তখন কনটেনশন এরর ঘটে।
হটস্পটিং-এর আরেকটি বিশেষ পরিস্থিতি ঘটে যখন Cloud Firestore ডকুমেন্ট আইডি হিসেবে ক্রমান্বয়ে বাড়তে বা কমতে থাকা কোনো কী (key) ব্যবহার করা হয় এবং প্রতি সেকেন্ডে অপারেশনের সংখ্যা অনেক বেশি থাকে। এক্ষেত্রে আরও স্প্লিট তৈরি করলেও কোনো লাভ হয় না, কারণ ট্র্যাফিকের এই আকস্মিক বৃদ্ধি কেবল নতুন তৈরি হওয়া স্প্লিটটিতেই স্থানান্তরিত হয়। যেহেতু Cloud Firestore ডিফল্টরূপে ডকুমেন্টের সমস্ত ফিল্ড স্বয়ংক্রিয়ভাবে ইনডেক্স করে, তাই টাইমস্ট্যাম্পের মতো ক্রমান্বয়ে বাড়তে বা কমতে থাকা কোনো ভ্যালু ধারণকারী ডকুমেন্ট ফিল্ডের ইনডেক্স স্পেসেও এই ধরনের চলমান হটস্পট তৈরি হতে পারে।
উল্লেখ্য যে, উপরে বর্ণিত পদ্ধতিগুলো অনুসরণ করলে, আপনাকে কোনো কনফিগারেশন পরিবর্তন না করেই Cloud Firestore ইচ্ছামতো বড় ওয়ার্কলোড সামাল দেওয়ার জন্য স্কেল করতে পারে।
সমস্যা সমাধান
Cloud Firestore ‘কী ভিজ্যুয়ালাইজার’ নামক একটি ডায়াগনস্টিক টুল প্রদান করে, যা ব্যবহারের ধরণ বিশ্লেষণ করতে এবং হটস্পটিং সংক্রান্ত সমস্যা সমাধান করার জন্য ডিজাইন করা হয়েছে।
এরপর কী হবে
- আরও সেরা অনুশীলন সম্পর্কে পড়ুন
- বৃহৎ পরিসরে রিয়েল-টাইম কোয়েরি সম্পর্কে জানুন