
A API Codable do Swift, lançada no Swift 4, permite aproveitar a capacidade do compilador para facilitar o mapeamento de dados de formatos serializados para tipos Swift.
Talvez você já tenha usado o Codable para mapear dados de uma API da Web para o modelo de dados do seu app (e vice-versa), mas ele é muito mais flexível que isso.
Neste guia, vamos descobrir como o Codable pode ser usado para mapear dados do Cloud Firestore para os tipos Swift e vice-versa.
Durante a busca de um documento do Cloud Firestore, seu app recebe um dicionário de pares de chave-valor ou uma matriz de dicionários, se você usar uma das operações que retornam vários documentos.
É possível continuar a usar os dicionários diretamente no Swift, e eles oferecem uma grande flexibilidade que talvez seja exatamente o que seu caso de uso exige. No entanto, essa abordagem não tem segurança de tipos e é fácil de introduzir bugs difíceis de identificar, por exemplo, escrever nomes de atributos incorretos ou esquecer de mapear o novo atributo adicionado pela equipe no lançamento de um novo recurso incrível semana passada.
No passado, muitos desenvolvedores resolveram essas limitações com a implementação de uma camada de mapeamento simples que permitia mapear dicionários para os tipos Swift. Novamente, a maioria dessas implementações se baseia na especificação manual do mapeamento entre os documentos do Cloud Firestore e os tipos correspondentes do modelo de dados do app.
Com o suporte do Cloud Firestore para a API Codable do Swift, isso fica muito mais fácil:
- Não será mais necessário implementar manualmente um código de mapeamento.
- É fácil definir como mapear atributos com nomes diferentes.
- Ele tem suporte integrado a muitos tipos Swift.
- Além disso, é fácil adicionar suporte ao mapeamento de tipos personalizados.
- O melhor de tudo é que, em modelos de dados simples, não é preciso escrever nenhum código de mapeamento.
Mapeamento de dados
O Cloud Firestore armazena dados em documentos que mapeiam chaves para valores. Para buscar dados de um documento, podemos chamar o DocumentSnapshot.data(), que retorna um dicionário que mapeia os nomes dos campos para um Any: func data() -> [String : Any]?.
Isso significa que podemos usar a sintaxe de subscrito do Swift para acessar cada campo.
import FirebaseFirestore
#warning("DO NOT MAP YOUR DOCUMENTS MANUALLY. USE CODABLE INSTEAD.")
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
let id = document.documentID
let data = document.data()
let title = data?["title"] as? String ?? ""
let numberOfPages = data?["numberOfPages"] as? Int ?? 0
let author = data?["author"] as? String ?? ""
self.book = Book(id:id, title: title, numberOfPages: numberOfPages, author: author)
}
}
}
}
Embora esse código pareça simples e fácil de implementar, ele é frágil, difícil de manter e propenso a erros.
Como você pode perceber, estamos fazendo suposições sobre os tipos de dados dos campos do documento. As suposições podem estar corretas ou não.
Como não há um esquema, é possível adicionar com facilidade um novo documento
à coleção e escolher um tipo diferente para um campo. Talvez você
escolha por engano a string do campo numberOfPages, o que resultaria
em um erro de mapeamento difícil de encontrar. Além disso, você precisará atualizar seu código de mapeamento sempre que um novo campo for adicionado, o que é difícil.
Não se esqueça de que não estamos aproveitando o sistema de tipo forte do Swift, que sabe exatamente o tipo correto para cada propriedade de
Book.
Mas o que é o Codable?
De acordo com a documentação da Apple, ele é "um tipo que permite a conversão de/para uma representação externa". Na verdade, ele é um alias de tipo para os protocolos Encodable e Decodable. Ao adequar um tipo Swift a esse protocolo, o compilador sintetiza o código necessário para codificar/decodificar uma instância desse tipo em um formato serializado, como JSON.
Um tipo simples de armazenamento de dados de um livro é semelhante ao seguinte:
struct Book: Codable {
var title: String
var numberOfPages: Int
var author: String
}
Como você pode perceber, adequar o tipo no Codable é minimamente invasivo. Só foi preciso adicionar a conformidade ao protocolo; nenhuma outra alteração foi necessária.
Com isso em vigor, agora é fácil codificar um livro para um objeto JSON:
do {
let book = Book(title: "The Hitchhiker's Guide to the Galaxy",
numberOfPages: 816,
author: "Douglas Adams")
let encoder = JSONEncoder()
let data = try encoder.encode(book)
}
catch {
print("Error when trying to encode book: \(error)")
}
Decodificar um objeto JSON para uma instância Book funciona da seguinte maneira:
let decoder = JSONDecoder()
let data = /* fetch data from the network */
let decodedBook = try decoder.decode(Book.self, from: data)
Como fazer mapeamento de/para tipos simples em documentos do Cloud Firestore com o Codable
O Cloud Firestore oferece suporte a um amplo conjunto de tipos de dados, que variam de strings simples a mapas aninhados. A maioria deles tem correspondência direta com os tipos integrados do Swift. Primeiro vamos analisar o mapeamento de alguns tipos de dados simples antes de passar para os mais complexos.
Para mapear documentos do Cloud Firestore para tipos Swift, siga estas etapas:
- Verifique se você adicionou o framework
FirebaseFirestoreao seu projeto. Para fazer isso, use o Gerenciador de pacotes do Swift ou o CocoaPods. - Importe
FirebaseFirestorepara seu arquivo Swift. - Adeque o tipo a
Codable. - Opcional, se você quiser usar o tipo em uma visualização
List: adicione uma propriedadeidao seu tipo e use@DocumentIDpara instruir o Cloud Firestore a fazer o mapeamento para o ID do documento. Isso será detalhado abaixo. - Use
documentReference.data(as: )para fazer o mapeamento de uma referência do documento para um tipo Swift. - Use
documentReference.setData(from: )para mapear dados de tipos Swift para um documento do Cloud Firestore. - Opcional, mas altamente recomendado: implemente o tratamento de erros adequado.
Vamos atualizar o tipo Book conforme essas instruções:
struct Book: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
}
Como esse tipo já era codificável, só precisamos adicionar a propriedade id e
anotá-la com o wrapper de propriedade @DocumentID.
Com o snippet de código anterior para buscar e mapear um documento, podemos substituir todo o código de mapeamento manual por uma linha:
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
do {
self.book = try document.data(as: Book.self)
}
catch {
print(error)
}
}
}
}
}
Para escrever isso de maneira ainda mais concisa, especifique o tipo de documento
ao chamar getDocument(as:). Isso realiza o mapeamento e retorna
um tipo Result com o documento mapeado ou um erro em caso de
falha na decodificação:
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
Atualizar um documento é tão simples
quanto chamar documentReference.setData(from: ). Após realizar um tratamento de erros básico,
salve uma instância Book com este código:
func updateBook(book: Book) {
if let id = book.id {
let docRef = db.collection("books").document(id)
do {
try docRef.setData(from: book)
}
catch {
print(error)
}
}
}
Ao adicionar um novo documento, o Cloud Firestore atribui automaticamente um novo ID a ele. Isso funciona até mesmo quando o app está off-line.
func addBook(book: Book) {
let collectionRef = db.collection("books")
do {
let newDocReference = try collectionRef.addDocument(from: self.book)
print("Book stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
Além de mapear tipos de dados simples, o Cloud Firestore oferece suporte a vários tipos de dados, alguns deles podem ser usados para criar objetos aninhados em um documento.
Tipos personalizados aninhados
A maioria dos atributos que queremos mapear nos documentos são valores simples, como o título do livro ou o nome do autor. Mas e quando precisamos armazenar um objeto mais complexo? Por exemplo, se quisermos armazenar os URLs para a capa do livro em diferentes resoluções.
A maneira mais fácil de fazer isso no Cloud Firestore é usar um mapa:

Ao escrever o struct Swift correspondente, é possível usar o suporte do Cloud Firestore aos URLs. Durante o armazenamento de um campo que contém um URL, ele será convertido em uma string e vice-versa:
struct CoverImages: Codable {
var small: URL
var medium: URL
var large: URL
}
struct BookWithCoverImages: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var cover: CoverImages?
}
Observe como definimos um struct, CoverImages, para o mapa da capa no documento do Cloud Firestore. Ao marcar a propriedade da capa em BookWithCoverImages como opcional, é possível processar o fato de que talvez alguns documentos não tenham um atributo de capa.
Se tiver curiosidade de saber por que não há um snippet de código para buscar ou atualizar dados, saiba que não é necessário corrigir o código para ler ou gravar no Cloud Firestore, ele funciona com o código que criamos na seção inicial.
Matrizes
Às vezes, queremos armazenar uma coleção de valores em um documento. Os gêneros de um livro são um bom exemplo: uma história como O Guia do Mochileiro das Galáxias se enquadra em várias categorias, neste caso "Ficção científica" e "Comédia":

No Cloud Firestore, podemos modelar isso usando uma matriz de valores. Esse recurso recebe suporte de qualquer tipo codificável, como String, Int etc. O exemplo abaixo mostra como adicionar uma matriz de gêneros ao nosso modelo Book:
public struct BookWithGenre: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var genres: [String]
}
Como esse método funciona para qualquer tipo codificável, também é possível usar tipos personalizados. Suponha que queremos armazenar uma lista de tags para cada livro. Além do nome da tag, também queremos armazenar a cor dela:
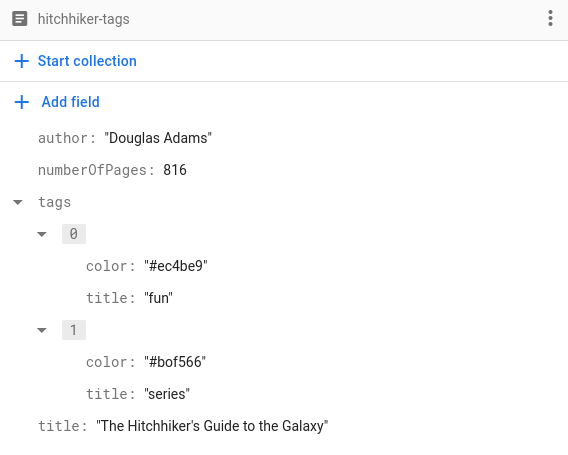
Para armazenar tags dessa maneira, basta implementar um struct Tag para representar
uma tag e torná-la codificável:
struct Tag: Codable, Hashable {
var title: String
var color: String
}
Assim, é possível armazenar uma matriz de Tags nos documentos Book.
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Um resumo sobre o mapeamento de IDs de documentos
Antes de mapear mais tipos, vamos falar sobre o mapeamento de IDs de documentos por um momento.
Usamos o wrapper da propriedade @DocumentID em alguns dos exemplos anteriores para fazer o mapeamento do ID dos documentos do Cloud Firestore para a propriedade id dos tipos Swift. Essa etapa é importante por vários motivos:
- Ela informa qual documento atualizar caso o usuário faça alterações locais.
- O
Listdo SwiftUI exige que os elementos sejamIdentifiablepara evitar que eles mudem de lugar na inserção.
Vale ressaltar que um atributo marcado como @DocumentID não será codificado pelo codificador do Cloud Firestore ao gravar o documento de novo. Isso ocorre
porque o ID do documento não é um atributo
do próprio documento. Portanto, gravá-lo seria um erro.
Ao trabalhar com tipos aninhados, como a matriz de tags em Book em um exemplo anterior neste guia, não é necessário adicionar uma propriedade @DocumentID: as propriedades aninhadas são parte de um documento do Cloud Firestore e constituem um outro separado. Portanto, elas não precisam de um ID de documento.
Datas e horas
O Cloud Firestore tem um tipo de dados integrado para processar datas e horas. Graças ao suporte do Cloud Firestore ao Codable, é simples usá-los.
Vamos conferir este documento que representa a Ada, a mãe de todas as linguagens de programação, inventada em 1843:

Um tipo Swift para mapeamento deste documento tem a seguinte aparência:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
}
Não podemos concluir esta seção sobre datas
e horas sem falar sobre @ServerTimestamp. Esse wrapper de propriedade tem alta capacidade
de processamento de carimbos de data/hora no app.
Em qualquer sistema distribuído, é provável que os relógios nos sistemas individuais não estejam em total sincronia o tempo todo. Você pode achar que isso não é importante, mas imagine as implicações de um relógio estar um pouco fora de sincronia para um sistema de negociação de ações: até mesmo um desvio em milissegundos resulta em uma diferença de milhões de dólares ao realizar um negócio.
O Cloud Firestore processa atributos marcados com @ServerTimestamp como se segue: se o atributo for nil quando você o armazenar (usando addDocument(), para
exemplo), o Cloud Firestore preencherá o campo com o servidor atual no momento em que ele é gravado no banco de dados. Se o campo não for nil, quando você ligar para addDocument() ou updateData(), o Cloud Firestore deixará o valor do atributo intacto. Dessa forma, é fácil implementar campos como createdAt e lastUpdatedAt.
Geopontos
As geolocalizações são onipresentes nos nossos apps. Armazená-las possibilita muitos recursos interessantes. Por exemplo, talvez seja útil armazenar o local de uma tarefa para que seu app lembre quando você chegar a um destino.
O Cloud Firestore tem um tipo de dados integrado, GeoPoint, que pode armazenar a latitude e a longitude de qualquer local. Para fazer mapeamento de locais de/para um documento do Cloud Firestore, é possível usar o tipo GeoPoint:
struct Office: Codable {
@DocumentID var id: String?
var name: String
var location: GeoPoint
}
O tipo correspondente no Swift é CLLocationCoordinate2D e podemos mapear
os dois com a seguinte operação:
CLLocationCoordinate2D(latitude: office.location.latitude,
longitude: office.location.longitude)
Para saber mais sobre como consultar documentos por local físico, confira este guia de solução.
Enums
É provável que os tipos enumerados sejam um dos recursos de linguagem mais subestimados do Swift.
As aparências enganam. Um caso de uso comum para tipos enumerados é
modelar os estados distintos de algo. Por exemplo, vamos criar um app
para gerenciar artigos. Para acompanhar o status de um artigo,
usamos um tipo enumerado Status:
enum Status: String, Codable {
case draft
case inReview
case approved
case published
}
O Cloud Firestore não oferece suporte aos tipos enumerados nativamente, ou seja, não pode aplicar o conjunto de valores, mas como eles podem ser digitados, é possível escolher um tipo codificável. Neste exemplo, selecionamos String, o que significa que todos os valores de tipos enumerados serão mapeados para/da string quando armazenados em um documento do Cloud Firestore.
E, como o Swift oferece suporte aos valores brutos personalizados, é possível até mesmo personalizar quais valores
se referem aos casos de tipo enumerado. Por exemplo, se decidirmos armazenar o
caso Status.inReview como "em análise", basta atualizar o tipo enumerado acima da
seguinte maneira:
enum Status: String, Codable {
case draft
case inReview = "in review"
case approved
case published
}
Personalizar o mapeamento
Às vezes, os nomes de atributos dos documentos do Cloud Firestore que queremos mapear não correspondem aos nomes das propriedades no modelo de dados no Swift. Por exemplo, um de nossos colegas de trabalho é um desenvolvedor em Python e decidiu escolher snake_case para todos os nomes de atributos.
Não se preocupe: o Codable tem a solução.
Em casos como esses, é possível usar CodingKeys. Ele é um tipo enumerado que pode ser
adicionado a um struct codificável para especificar como determinados atributos serão mapeados.
Analise este documento:

Para fazer o mapeamento desse documento para um struct com uma propriedade de nome do tipo String,
adicione um tipo enumerado CodingKeys ao struct ProgrammingLanguage e especifique
o nome do atributo no documento:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
Por padrão, a API Codable usará os nomes de propriedades dos nossos tipos Swift para determinar os nomes dos atributos nos documentos do Cloud Firestore que queremos mapear. Portanto, desde que os nomes dos atributos correspondam, não é necessário adicionar CodingKeys aos tipos codificáveis. No entanto, depois de usar CodingKeys em um tipo específico, é preciso adicionar todos os nomes de propriedades que queremos mapear.
No snippet de código acima, definimos uma propriedade id a ser usada como
o identificador em uma visualização de List do SwiftUI. Se o valor não for especificado em
CodingKeys, ele não será mapeado ao buscar dados e se tornará nil.
Isso faria com que a visualização de List fosse preenchida com o primeiro documento.
Qualquer propriedade que não esteja listada como um caso no respectivo tipo enumerado CodingKeys será ignorada durante o processo de mapeamento. Isso pode ser conveniente
se quisermos excluir algumas propriedades específicas do mapeamento.
Por exemplo, se quisermos excluir a propriedade reasonWhyILoveThis do
mapeamento, basta removê-la do tipo enumerado CodingKeys:
struct ProgrammingLanguage: Identifiable, Codable {
@DocumentID var id: String?
var name: String
var year: Date
var reasonWhyILoveThis: String = ""
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
Ocasionalmente podemos querer escrever um atributo vazio de volta no documento do Cloud Firestore. O Swift tem a noção de opcionais para indicar a ausência de um valor, e o Cloud Firestore também aceita valores null.
No entanto, o comportamento padrão para a codificação de opcionais com um valor nil é omiti-los. O @ExplicitNull permite algum controle sobre como os opcionais do Swift são processados na codificação. Ao sinalizar uma propriedade opcional como @ExplicitNull, é possível instruir o Cloud Firestore a gravar essa propriedade no documento com um valor nulo se ele contiver o valor nil.
Como usar codificadores e decodificadores personalizados para mapear cores
No último tópico do mapeamento de dados com o Codable, vamos explicar codificadores e decodificadores personalizados. Esta seção não abrange um tipo de dados nativo do Cloud Firestore, mas codificadores e decodificadores personalizados são muito úteis nos apps do Cloud Firestore.
"Como mapear cores" é uma das perguntas mais frequentes dos desenvolvedores, não apenas para o Cloud Firestore, mas também para o mapeamento entre Swift e JSON. Há muitas soluções disponíveis, mas a maioria delas se concentra no JSON. e quase todas mapeiam cores como um dicionário aninhado formado pelos componentes RGB.
Parece que deveria haver uma solução melhor e mais simples. Por que não usamos cores da Web (ou, em específico, a notação de cor hexadecimal CSS)? Elas são fáceis de usar (precisam de apenas uma string) e dão suporte para transparência.
Para fazer o mapeamento um Color do Swift para o valor hexadecimal, é preciso criar uma extensão
do Swift que adicione o Codable ao Color.
extension Color {
init(hex: String) {
let rgba = hex.toRGBA()
self.init(.sRGB,
red: Double(rgba.r),
green: Double(rgba.g),
blue: Double(rgba.b),
opacity: Double(rgba.alpha))
}
//... (code for translating between hex and RGBA omitted for brevity)
}
extension Color: Codable {
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let hex = try container.decode(String.self)
self.init(hex: hex)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(toHex)
}
}
Com o decoder.singleValueContainer(), é possível decodificar um String para o
Color equivalente, sem precisar aninhar os componentes RGBA. Além disso, é possível
usar esses valores na IU da Web do seu app sem precisar convertê-los
primeiro.
Com isso, é possível atualizar o código do mapeamento de tags, o que facilita o processamento direto das cores das tags, sem precisar mapeá-las manualmente no código da IU do app:
struct Tag: Codable, Hashable {
var title: String
var color: Color
}
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Tratamento de erros
Nos snippets de código acima, tratamos o mínimo de erros intencionalmente, mas, em um app de produção, é preciso resolver todos os erros.
O seguinte snippet de código mostra como resolver qualquer erro que você se deparar:
class MappingSimpleTypesViewModel: ObservableObject {
@Published var book: Book = .empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
func fetchAndMap() {
fetchBook(documentId: "hitchhiker")
}
func fetchAndMapNonExisting() {
fetchBook(documentId: "does-not-exist")
}
func fetchAndTryMappingInvalidData() {
fetchBook(documentId: "invalid-data")
}
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self.errorMessage = "\(error.localizedDescription): \(key)"
default:
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
}
}
Tratamento de erros em atualizações em tempo real
O snippet de código anterior demonstra como tratar erros durante a busca de um documento. Além de buscar dados uma vez, o Cloud Firestore também dá suporte ao envio de atualizações para o app em tempo real usando os chamados listeners de snapshots. É possível registrar um listener de snapshot em uma coleção (ou consulta) e o Cloud Firestore o chama sempre que há uma atualização.
O snippet de código a seguir mostra como registrar um listener de snapshot, mapear dados com o Codable e tratar possíveis erros. Ele também mostra como adicionar um novo documento à coleção. Como você pode notar, não é necessário atualizar a matriz local que contém os documentos mapeados, já que isso é feito pelo código no listener de snapshot.
class MappingColorsViewModel: ObservableObject {
@Published var colorEntries = [ColorEntry]()
@Published var newColor = ColorEntry.empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
private var listenerRegistration: ListenerRegistration?
public func unsubscribe() {
if listenerRegistration != nil {
listenerRegistration?.remove()
listenerRegistration = nil
}
}
func subscribe() {
if listenerRegistration == nil {
listenerRegistration = db.collection("colors")
.addSnapshotListener { [weak self] (querySnapshot, error) in
guard let documents = querySnapshot?.documents else {
self?.errorMessage = "No documents in 'colors' collection"
return
}
self?.colorEntries = documents.compactMap { queryDocumentSnapshot in
let result = Result { try queryDocumentSnapshot.data(as: ColorEntry.self) }
switch result {
case .success(let colorEntry):
if let colorEntry = colorEntry {
// A ColorEntry value was successfully initialized from the DocumentSnapshot.
self?.errorMessage = nil
return colorEntry
}
else {
// A nil value was successfully initialized from the DocumentSnapshot,
// or the DocumentSnapshot was nil.
self?.errorMessage = "Document doesn't exist."
return nil
}
case .failure(let error):
// A ColorEntry value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self?.errorMessage = "\(error.localizedDescription): \(key)"
default:
self?.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
return nil
}
}
}
}
}
func addColorEntry() {
let collectionRef = db.collection("colors")
do {
let newDocReference = try collectionRef.addDocument(from: newColor)
print("ColorEntry stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
}
Todos os snippets de código usados nesta postagem fazem parte do aplicativo de exemplo disponível para download neste repositório do GitHub.
Aproveite os recursos do Codable!
A API Codable do Swift faz o mapeamento de dados de formatos serializados de/para o modelo de dados do aplicativo de modo flexível e eficaz. Neste guia, você descobriu como é fácil usá-la em apps que usam o Cloud Firestore como repositório de dados.
Começamos com um exemplo básico de tipos de dados simples, aumentamos gradativamente a complexidade do modelo de dados, com a confiança na implementação do Codable e do Firebase para realizar o mapeamento.
Para saber mais detalhes sobre o Codable, recomendo os seguintes recursos:
- John Sundell tem um artigo interessante sobre Noções básicas do Codable.
- Se você gosta mais de livros, confira o Flight School Guide to Swift Codable do Mattt.
- Por fim, assista à série sobre o Codable de Donny Wals.
Fizemos o possível para compilar um guia abrangente de mapeamento de documentos do Cloud Firestore, mas esse documento não é absoluto e talvez você use outras estratégias para mapear os tipos. Use o botão Enviar feedback abaixo para informar quais estratégias você usa para mapear outros tipos de dados do Cloud Firestore ou representar dados no Swift.
Não deixe de usar o suporte do Codable do Cloud Firestore.