
Interfejs Codable API w języku Swift, wprowadzony w Swift 4, umożliwia wykorzystanie możliwości kompilatora, aby ułatwić mapowanie danych z formatów serializowanych na typy Swift.
Być może używasz interfejsu Codable do mapowania danych z interfejsu API w internecie na model danych aplikacji (i odwrotnie), ale jest on znacznie bardziej elastyczny.
W tym przewodniku pokażemy, jak używać interfejsu Codable do mapowania danych z Cloud Firestore na typy Swift i odwrotnie.
Podczas pobierania dokumentu z Cloud Firestore aplikacja otrzyma słownik par klucz-wartość (lub tablicę słowników, jeśli używasz jednej z operacji zwracających wiele dokumentów).
Możesz oczywiście nadal używać słowników bezpośrednio w Swift. Oferują one dużą elastyczność, która może być dokładnie tym, czego potrzebujesz. To podejście nie jest jednak bezpieczne pod względem typów i łatwo jest wprowadzić trudne do wykrycia błędy, np. przez błędne wpisanie nazw atrybutów lub zapomnienie o zmapowaniu nowego atrybutu dodanego przez zespół podczas wdrażania nowej funkcji w zeszłym tygodniu.
W przeszłości wielu deweloperów radziło sobie z tymi niedociągnięciami, implementując prostą warstwę mapowania, która umożliwiała mapowanie słowników na typy Swift. Jednak większość tych implementacji opiera się na ręcznym określaniu mapowania między Cloud Firestore dokumentami a odpowiednimi typami modelu danych aplikacji.
Dzięki obsłudze interfejsu Codable API w Swift przez Cloud Firestore staje się to znacznie łatwiejsze:
- Nie musisz już ręcznie implementować kodu mapowania.
- Łatwo jest zdefiniować sposób mapowania atrybutów o różnych nazwach.
- Interfejs ma wbudowaną obsługę wielu typów Swift.
- Łatwo jest dodać obsługę mapowania typów niestandardowych.
- A co najważniejsze: w przypadku prostych modeli danych nie musisz w ogóle pisać kodu mapowania.
Mapowanie danych
Cloud Firestore przechowuje dane w dokumentach, które mapują klucze na wartości. Aby pobrać
dane z pojedynczego dokumentu, możemy wywołać funkcję DocumentSnapshot.data(), która
zwraca słownik mapujący nazwy pól na Any:
func data() -> [String : Any]?.
Oznacza to, że możemy użyć składni indeksowania w Swift, aby uzyskać dostęp do każdego pola.
import FirebaseFirestore
#warning("DO NOT MAP YOUR DOCUMENTS MANUALLY. USE CODABLE INSTEAD.")
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
let id = document.documentID
let data = document.data()
let title = data?["title"] as? String ?? ""
let numberOfPages = data?["numberOfPages"] as? Int ?? 0
let author = data?["author"] as? String ?? ""
self.book = Book(id:id, title: title, numberOfPages: numberOfPages, author: author)
}
}
}
}
Chociaż ten kod może wydawać się prosty i łatwy do wdrożenia, jest on podatny na błędy, trudny w utrzymaniu i podatny na błędy.
Jak widzisz, zakładamy, że znamy typy danych pól dokumentu. Mogą one być poprawne lub nie.
Pamiętaj, że ponieważ nie ma schematu, możesz łatwo dodać nowy dokument do kolekcji i wybrać inny typ pola. Możesz przypadkowo wybrać ciąg znaków dla pola numberOfPages, co spowoduje trudny do wykrycia problem z mapowaniem. Ponadto za każdym razem, gdy dodasz nowe pole, musisz zaktualizować kod mapowania, co jest dość uciążliwe.
Nie zapominajmy też, że nie korzystamy z systemu silnych typów Swift, który dokładnie zna prawidłowy typ każdej właściwości Book.
Czym jest interfejs Codable?
Zgodnie z dokumentacją Apple interfejs Codable to „typ, który może przekształcać się w reprezentację zewnętrzną i z niej”. W rzeczywistości interfejs Codable to alias typu dla protokołów Encodable i Decodable. Dzięki dostosowaniu typu Swift do tego protokołu kompilator zsyntetyzuje kod potrzebny do kodowania i dekodowania instancji tego typu z formatu serializowanego, takiego jak JSON.
Prosty typ do przechowywania danych o książce może wyglądać tak:
struct Book: Codable {
var title: String
var numberOfPages: Int
var author: String
}
Jak widzisz, dostosowanie typu do interfejsu Codable jest minimalnie inwazyjne. Musieliśmy tylko dodać zgodność z protokołem. Nie były wymagane żadne inne zmiany.
Dzięki temu możemy teraz łatwo zakodować książkę w obiekcie JSON:
do {
let book = Book(title: "The Hitchhiker's Guide to the Galaxy",
numberOfPages: 816,
author: "Douglas Adams")
let encoder = JSONEncoder()
let data = try encoder.encode(book)
}
catch {
print("Error when trying to encode book: \(error)")
}
Dekodowanie obiektu JSON do instancji Book działa w ten sposób:
let decoder = JSONDecoder()
let data = /* fetch data from the network */
let decodedBook = try decoder.decode(Book.self, from: data)
Mapowanie na proste typy w dokumentach Cloud Firestore i z nich za pomocą interfejsu Codable
Cloud Firestore obsługuje szeroki zakres typów danych, od prostych ciągów znaków po zagnieżdżone mapy. Większość z nich odpowiada bezpośrednio wbudowanym typom Swift. Zanim przejdziemy do bardziej złożonych typów, przyjrzyjmy się najpierw mapowaniu prostych typów danych.
Aby zmapować dokumenty Cloud Firestore na typy Swift:
- Upewnij się, że do projektu został dodany framework
FirebaseFirestore. Możesz to zrobić za pomocą narzędzia Swift Package Manager lub CocoaPods. - Zaimportuj
FirebaseFirestoredo pliku Swift. - Dostosuj typ do
Codable. - (Opcjonalnie, jeśli chcesz użyć typu w widoku
List) Dodaj do typu właściwośćidi użyj@DocumentID, aby poinformować Cloud Firestore, że ma ją zmapować na identyfikator dokumentu. Omówimy to bardziej szczegółowo poniżej. - Użyj
documentReference.data(as: ), aby zmapować odwołanie do dokumentu na typ Swift. - Użyj
documentReference.setData(from: ), aby zmapować dane z typów Swift na dokument Cloud Firestore. - (Opcjonalnie, ale zdecydowanie zalecane) Zaimplementuj odpowiednią obsługę błędów.
Zaktualizujmy odpowiednio typ Book:
struct Book: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
}
Ponieważ ten typ był już kodowalny, musieliśmy tylko dodać właściwość id i opatrzyć ją otoczką właściwości @DocumentID.
Biorąc pod uwagę poprzedni fragment kodu do pobierania i mapowania dokumentu, możemy zastąpić cały kod mapowania ręcznego jednym wierszem:
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
do {
self.book = try document.data(as: Book.self)
}
catch {
print(error)
}
}
}
}
}
Możesz to zapisać jeszcze bardziej zwięźle, określając typ dokumentu podczas wywoływania funkcji getDocument(as:). Spowoduje to wykonanie mapowania i zwrócenie typu Result zawierającego zmapowany dokument lub błąd w przypadku niepowodzenia dekodowania:
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
Aktualizowanie istniejącego dokumentu jest tak proste jak wywołanie funkcji documentReference.setData(from: ). Oto kod do zapisywania instancji Book z podstawową obsługą błędów:
func updateBook(book: Book) {
if let id = book.id {
let docRef = db.collection("books").document(id)
do {
try docRef.setData(from: book)
}
catch {
print(error)
}
}
}
Podczas dodawania nowego dokumentu Cloud Firestore automatycznie zajmie się przypisaniem mu nowego identyfikatora. Działa to nawet wtedy, gdy aplikacja jest offline.
func addBook(book: Book) {
let collectionRef = db.collection("books")
do {
let newDocReference = try collectionRef.addDocument(from: self.book)
print("Book stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
Oprócz mapowania prostych typów danych, Cloud Firestore obsługuje szereg innych typów danych, z których niektóre są typami strukturalnymi, których można używać do tworzenia zagnieżdżonych obiektów w dokumencie.
Zagnieżdżone typy niestandardowe
Większość atrybutów, które chcemy zmapować w naszych dokumentach, to proste wartości, takie jak tytuł książki czy imię i nazwisko autora. Ale co w przypadku, gdy musimy zapisać bardziej złożony obiekt? Możemy na przykład chcieć zapisać adresy URL okładki książki w różnych rozdzielczościach.
Najłatwiej to zrobić w Cloud Firestore za pomocą mapy:

Podczas pisania odpowiedniej struktury Swift możemy wykorzystać fakt, że Cloud Firestore obsługuje adresy URL. Podczas zapisywania pola zawierającego adres URL zostanie ono przekonwertowane na ciąg znaków i odwrotnie:
struct CoverImages: Codable {
var small: URL
var medium: URL
var large: URL
}
struct BookWithCoverImages: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var cover: CoverImages?
}
Zwróć uwagę, jak zdefiniowaliśmy strukturę CoverImages dla mapy okładki w dokumencie
Cloud Firestore. Oznaczając właściwość cover w BookWithCoverImages jako opcjonalną, możemy uwzględnić fakt, że niektóre dokumenty mogą nie zawierać atrybutu cover.
Jeśli zastanawiasz się, dlaczego nie ma fragmentu kodu do pobierania ani aktualizowania danych, ucieszy Cię wiadomość, że nie musisz dostosowywać kodu do odczytywania danych z Cloud Firestore ani zapisywania w nim. Wszystko to działa z kodem, który napisaliśmy w pierwszej sekcji.
Tablice
Czasami chcemy zapisać w dokumencie kolekcję wartości. Dobrym przykładem są gatunki książki. Książka taka jak Autostopem przez Galaktykę może należeć do kilku kategorii – w tym przypadku „Sci-Fi” i „Komedia”:

W Cloud Firestore możemy to modelować za pomocą tablicy wartości. Jest to obsługiwane w przypadku każdego typu kodowalnego (np. String, Int itp.). Poniżej pokazujemy, jak dodać tablicę gatunków do modelu Book:
public struct BookWithGenre: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var genres: [String]
}
Ponieważ działa to w przypadku każdego typu kodowalnego, możemy też używać typów niestandardowych. Wyobraź sobie, że chcemy przechowywać listę tagów dla każdej książki. Oprócz nazwy tagu chcemy też przechowywać jego kolor, np. tak:
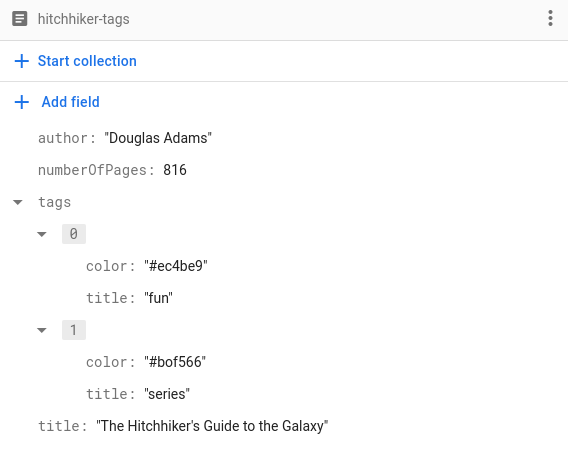
Aby przechowywać tagi w ten sposób, musimy tylko zaimplementować strukturę Tag reprezentującą tag i uczynić ją kodowalną:
struct Tag: Codable, Hashable {
var title: String
var color: String
}
W ten sposób możemy przechowywać tablicę Tags w dokumentach Book.
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Krótka uwaga na temat mapowania identyfikatorów dokumentów
Zanim przejdziemy do mapowania większej liczby typów, porozmawiajmy przez chwilę o mapowaniu identyfikatorów dokumentów.
W niektórych poprzednich przykładach użyliśmy otoczki właściwości @DocumentID, aby zmapować identyfikator dokumentu w dokumentach Cloud Firestore na właściwość id w typach Swift. Jest to ważne z kilku powodów:
- Pomaga nam to określić, który dokument należy zaktualizować, jeśli użytkownik wprowadzi zmiany lokalne.
- Aby zapobiec przeskakiwaniu elementów podczas ich wstawiania, elementy
Listw SwiftUI muszą byćIdentifiable.
Warto zauważyć, że atrybut oznaczony jako @DocumentID nie będzie
kodowany przez Cloud Firestore's encoder podczas zapisywania dokumentu. Dzieje się tak, ponieważ identyfikator dokumentu nie jest atrybutem samego dokumentu, więc zapisanie go w dokumencie byłoby błędem.
Podczas pracy z typami zagnieżdżonymi (takimi jak tablica tagów w Book w
poprzednim przykładzie w tym przewodniku) nie trzeba dodawać właściwości @DocumentID
. Właściwości zagnieżdżone są częścią dokumentu Cloud Firestore i
nie stanowią osobnego dokumentu. Dlatego nie potrzebują identyfikatora dokumentu.
Daty i godziny
Cloud Firestore ma wbudowany typ danych do obsługi dat i godzin, a dzięki obsłudze interfejsu Codable przez Cloud Firestore ich używanie jest proste.
Spójrz na ten dokument, który reprezentuje matkę wszystkich języków programowania, czyli język Ada, wynaleziony w 1843 roku:

Typ Swift do mapowania tego dokumentu może wyglądać tak:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
}
Nie możemy pominąć w tej sekcji dotyczącej dat i godzin rozmowy o @ServerTimestamp. Ta otoczka właściwości jest bardzo przydatna, jeśli chodzi o obsługę sygnatur czasowych w aplikacji.
W każdym systemie rozproszonym istnieje prawdopodobieństwo, że zegary w poszczególnych systemach nie będą przez cały czas w pełni zsynchronizowane. Możesz pomyśleć, że to nic wielkiego, ale wyobraź sobie konsekwencje zegara, który jest nieco rozsynchronizowany w systemie handlu akcjami. Nawet milisekundowe odchylenie może spowodować różnicę w wysokości milionów dolarów podczas realizacji transakcji.
Cloud Firestore obsługuje atrybuty oznaczone jako @ServerTimestamp w ten sposób: jeśli atrybut ma wartość nil podczas zapisywania (np. za pomocą funkcji addDocument()), Cloud Firestore wypełni pole bieżącą sygnaturą czasową serwera w momencie zapisywania go w bazie danych. Jeśli pole nie ma wartości nil
podczas wywoływania funkcji addDocument() lub updateData(), Cloud Firestore pozostawi
wartość atrybutu bez zmian. W ten sposób łatwo jest zaimplementować pola takie jak createdAt i lastUpdatedAt.
Punkty geograficzne
Geolokalizacje są wszechobecne w naszych aplikacjach. Dzięki ich przechowywaniu możliwe jest wiele ciekawych funkcji. Może się na przykład przydać zapisanie lokalizacji zadania, aby aplikacja mogła przypomnieć o zadaniu po dotarciu do miejsca docelowego.
Cloud Firestore ma wbudowany typ danych GeoPoint, który może przechowywać
długość i szerokość geograficzną dowolnej lokalizacji. Aby zmapować lokalizacje z dokumentu
Cloud Firestore i do niego, możemy użyć typu GeoPoint:
struct Office: Codable {
@DocumentID var id: String?
var name: String
var location: GeoPoint
}
Odpowiednim typem w Swift jest CLLocationCoordinate2D, a mapowanie między tymi dwoma typami możemy wykonać za pomocą tej operacji:
CLLocationCoordinate2D(latitude: office.location.latitude,
longitude: office.location.longitude)
Więcej informacji o wysyłaniu zapytań o dokumenty według lokalizacji fizycznej znajdziesz w tym przewodniku.
Wartości w polu enum
Wartości w polu enum są prawdopodobnie jedną z najbardziej niedocenianych funkcji języka Swift. Mają one znacznie więcej możliwości, niż się wydaje. Typowym przypadkiem użycia wartości w polu enum jest modelowanie dyskretnych stanów czegoś. Możemy na przykład pisać aplikację do zarządzania artykułami. Aby śledzić stan artykułu, możemy użyć wartości w polu enum Status:
enum Status: String, Codable {
case draft
case inReview
case approved
case published
}
Cloud Firestore nie obsługuje wartości w polu enum natywnie (tzn. nie może wymuszać
zbioru wartości), ale możemy nadal korzystać z faktu, że wartości w polu enum mogą być typowane,
i wybrać typ kodowalny. W tym przykładzie wybraliśmy String, co oznacza
że wszystkie wartości w polu enum będą mapowane na ciąg znaków i z niego podczas przechowywania w
Cloud Firestore dokumencie.
A ponieważ Swift obsługuje niestandardowe wartości pierwotne, możemy nawet dostosować, które wartości odnoszą się do którego przypadku wartości w polu enum. Jeśli na przykład zdecydujemy się przechowywać przypadek Status.inReview jako „in review”, możemy zaktualizować powyższą wartość w polu enum w ten sposób:
enum Status: String, Codable {
case draft
case inReview = "in review"
case approved
case published
}
Dostosowywanie mapowania
Czasami nazwy atrybutów dokumentów Cloud Firestore, które chcemy zmapować, nie pasują do nazw właściwości w naszym modelu danych w Swift. Na przykład jeden z naszych współpracowników może być deweloperem Pythona i zdecydować się na użycie snake_case dla wszystkich nazw atrybutów.
Nie martw się, interfejs Codable Ci pomoże.
W takich przypadkach możemy użyć CodingKeys. Jest to wartość w polu enum, którą możemy dodać do struktury kodowalnej, aby określić, jak mają być mapowane określone atrybuty.
Rozważ ten dokument:

Aby zmapować ten dokument na strukturę, która ma właściwość name typu String, musimy dodać wartość w polu enum CodingKeys do struktury ProgrammingLanguage i określić nazwę atrybutu w dokumencie:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
Domyślnie interfejs Codable API używa nazw właściwości typów Swift do
określania nazw atrybutów w dokumentach Cloud Firestore, które próbujemy
zmapować. Dopóki nazwy atrybutów są zgodne, nie musimy dodawać CodingKeys do naszych typów kodowalnych. Gdy jednak użyjemy CodingKeys w przypadku określonego typu, musimy dodać wszystkie nazwy właściwości, które chcemy zmapować.
W powyższym fragmencie kodu zdefiniowaliśmy właściwość id, której możemy użyć jako identyfikatora w widoku List w SwiftUI. Jeśli nie określimy jej w CodingKeys, nie zostanie ona zmapowana podczas pobierania danych, a tym samym stanie się nil.
Spowoduje to wypełnienie widoku List pierwszym dokumentem.
Każda właściwość, która nie jest wymieniona jako przypadek w odpowiedniej wartości w polu enum CodingKeys, zostanie zignorowana podczas procesu mapowania. Może to być wygodne, jeśli chcemy wykluczyć niektóre właściwości z mapowania.
Jeśli na przykład chcemy wykluczyć właściwość reasonWhyILoveThis z mapowania, musimy tylko usunąć ją z wartości w polu enum CodingKeys:
struct ProgrammingLanguage: Identifiable, Codable {
@DocumentID var id: String?
var name: String
var year: Date
var reasonWhyILoveThis: String = ""
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
Czasami możemy chcieć zapisać pusty atrybut z powrotem w
Cloud Firestore dokumencie. Swift ma pojęcie opcjonalności, aby oznaczyć
brak wartości, a Cloud Firestore obsługuje null wartości też.
Domyślnym zachowaniem podczas kodowania opcjonalnych wartości, które mają wartość nil, jest jednak ich pomijanie. @ExplicitNull daje nam pewną kontrolę nad sposobem obsługi opcjonalnych wartości Swift
podczas ich kodowania. Oznaczając opcjonalną właściwość jako
@ExplicitNull, możemy poinformować Cloud Firestore, że ma zapisać tę właściwość w
dokumencie z wartością null, jeśli zawiera ona wartość nil.
Używanie niestandardowego kodera i dekodera do mapowania kolorów
Na koniec omówienia mapowania danych za pomocą interfejsu Codable przedstawimy niestandardowe kodery i dekodery. Ta sekcja nie obejmuje natywnego Cloud Firestore typu danych, ale niestandardowe kodery i dekodery są bardzo przydatne w aplikacjach Cloud Firestore.
„Jak mogę zmapować kolory?” to jedno z najczęściej zadawanych pytań deweloperów, nie tylko w przypadku Cloud Firestore, ale też mapowania między Swift a JSON również. Istnieje wiele rozwiązań, ale większość z nich koncentruje się na JSON, a prawie wszystkie mapują kolory jako zagnieżdżony słownik składający się z komponentów RGB.
Wydaje się, że powinno istnieć lepsze, prostsze rozwiązanie. Dlaczego nie użyć kolorów internetowych (a dokładniej notacji szesnastkowej kolorów CSS)? Są one łatwe w użyciu (w zasadzie to tylko ciąg znaków) i obsługują nawet przezroczystość.
Aby móc zmapować Color w Swift na jego wartość szesnastkową, musimy utworzyć rozszerzenie Swift, które doda interfejs Codable do Color.
extension Color {
init(hex: String) {
let rgba = hex.toRGBA()
self.init(.sRGB,
red: Double(rgba.r),
green: Double(rgba.g),
blue: Double(rgba.b),
opacity: Double(rgba.alpha))
}
//... (code for translating between hex and RGBA omitted for brevity)
}
extension Color: Codable {
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let hex = try container.decode(String.self)
self.init(hex: hex)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(toHex)
}
}
Używając decoder.singleValueContainer(), możemy zdekodować String na jego odpowiednik Color bez konieczności zagnieżdżania komponentów RGBA. Ponadto możesz używać tych wartości w interfejsie internetowym aplikacji bez konieczności ich wcześniejszego konwertowania.
Dzięki temu możemy zaktualizować kod do mapowania tagów, co ułatwi bezpośrednią obsługę kolorów tagów zamiast ręcznego mapowania ich w kodzie interfejsu aplikacji:
struct Tag: Codable, Hashable {
var title: String
var color: Color
}
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Obsługa błędów
W powyższych fragmentach kodu celowo ograniczyliśmy obsługę błędów do minimum, ale w aplikacji produkcyjnej musisz zadbać o prawidłową obsługę wszystkich błędów.
Oto fragment kodu, który pokazuje, jak obsługiwać wszystkie sytuacje, w których mogą wystąpić błędy:
class MappingSimpleTypesViewModel: ObservableObject {
@Published var book: Book = .empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
func fetchAndMap() {
fetchBook(documentId: "hitchhiker")
}
func fetchAndMapNonExisting() {
fetchBook(documentId: "does-not-exist")
}
func fetchAndTryMappingInvalidData() {
fetchBook(documentId: "invalid-data")
}
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self.errorMessage = "\(error.localizedDescription): \(key)"
default:
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
}
}
Obsługa błędów w aktualizacjach na żywo
Poprzedni fragment kodu pokazuje, jak obsługiwać błędy podczas pobierania pojedynczego dokumentu. Oprócz jednorazowego pobierania danych Cloud Firestore obsługuje też dostarczanie aktualizacji do aplikacji w miarę ich pojawiania się za pomocą tzw. słuchaczy migawek: możemy zarejestrować słuchacza migawek w kolekcji (lub zapytaniu), a Cloud Firestore będzie wywoływać naszego słuchacza za każdym razem, gdy pojawi się aktualizacja.
Oto fragment kodu, który pokazuje, jak zarejestrować słuchacza migawek, zmapować dane za pomocą interfejsu Codable i obsługiwać błędy, które mogą wystąpić. Pokazuje też, jak dodać nowy dokument do kolekcji. Jak widzisz, nie musimy sami aktualizować lokalnej tablicy zawierającej zmapowane dokumenty, ponieważ zajmuje się tym kod w słuchaczu migawek.
class MappingColorsViewModel: ObservableObject {
@Published var colorEntries = [ColorEntry]()
@Published var newColor = ColorEntry.empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
private var listenerRegistration: ListenerRegistration?
public func unsubscribe() {
if listenerRegistration != nil {
listenerRegistration?.remove()
listenerRegistration = nil
}
}
func subscribe() {
if listenerRegistration == nil {
listenerRegistration = db.collection("colors")
.addSnapshotListener { [weak self] (querySnapshot, error) in
guard let documents = querySnapshot?.documents else {
self?.errorMessage = "No documents in 'colors' collection"
return
}
self?.colorEntries = documents.compactMap { queryDocumentSnapshot in
let result = Result { try queryDocumentSnapshot.data(as: ColorEntry.self) }
switch result {
case .success(let colorEntry):
if let colorEntry = colorEntry {
// A ColorEntry value was successfully initialized from the DocumentSnapshot.
self?.errorMessage = nil
return colorEntry
}
else {
// A nil value was successfully initialized from the DocumentSnapshot,
// or the DocumentSnapshot was nil.
self?.errorMessage = "Document doesn't exist."
return nil
}
case .failure(let error):
// A ColorEntry value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self?.errorMessage = "\(error.localizedDescription): \(key)"
default:
self?.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
return nil
}
}
}
}
}
func addColorEntry() {
let collectionRef = db.collection("colors")
do {
let newDocReference = try collectionRef.addDocument(from: newColor)
print("ColorEntry stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
}
Do dzieła! Używaj interfejsu Codable.
Interfejs Codable API w Swift zapewnia zaawansowany i elastyczny sposób mapowania danych z formatów serializowanych na model danych aplikacji i z niego. W tym przewodniku, pokazaliśmy, jak łatwo jest go używać w aplikacjach, które używają Cloud Firestore jako swojego magazynu danych.
Zaczynając od podstawowego przykładu z prostymi typami danych, stopniowo zwiększaliśmy złożoność modelu danych, cały czas polegając na interfejsie Codable i implementacji Firebase, aby wykonywać mapowanie.
Więcej informacji o interfejsie Codable znajdziesz w tych materiałach:
- John Sundell napisał ciekawy artykuł o podstawach interfejsu Codable.
- Jeśli wolisz książki, zapoznaj się z przewodnikiem Mattta Flight School Guide to Swift Codable.
- Na koniec Donny Wals ma całą serię o interfejsie Codable.
Chociaż dołożyliśmy wszelkich starań, aby przygotować wyczerpujący przewodnik po mapowaniu Cloud Firestore dokumentów, nie jest on wyczerpujący i możesz używać innych strategii mapowania typów. Za pomocą przycisku Prześlij opinię poniżej, poinformuj nas, jakich strategii używasz do mapowania innych typów Cloud Firestore danych lub reprezentowania danych w Swift.
Nie ma powodu, aby nie korzystać z obsługi interfejsu Codable przez Cloud Firestore.