
כדאי לקרוא את המסמך הזה כדי לקבל החלטות מושכלות לגבי הארכיטקטורה של האפליקציות שלכם, במטרה להשיג ביצועים גבוהים ומהימנות. המסמך הזה כולל נושאים מתקדמים בנושא Cloud Firestore. אם אתם רק מתחילים להשתמש ב-Cloud Firestore, כדאי לעיין במקום זאת במדריך לתחילת העבודה.
Cloud Firestore הוא מסד נתונים גמיש וניתן להרחבה לפיתוח של אפליקציות לנייד, לאינטרנט ולשרתים מ-Firebase ומ-Google Cloud. קל מאוד להתחיל להשתמש ב-Cloud Firestore ולכתוב אפליקציות עשירות ועוצמתיות.
כדי לוודא שהאפליקציות ימשיכו לפעול בצורה טובה ככל שגודל מסד הנתונים ותעבורת הנתונים יגדלו, חשוב להבין את המנגנונים של פעולות קריאה וכתיבה ב-Cloud Firestore בק-אנד. בנוסף, צריך להבין את האינטראקציה של פעולות הקריאה והכתיבה עם שכבת האחסון והמגבלות הבסיסיות שעשויות להשפיע על הביצועים.
לפני שמתכננים את הארכיטקטורה של האפליקציה, כדאי לעיין בשיטות המומלצות שמפורטות בקטעים הבאים.
הסבר על הרכיבים ברמה גבוהה
הדיאגרמה הבאה מציגה את הרכיבים ברמה הגבוהה שמעורבים בבקשת API של Cloud Firestore.
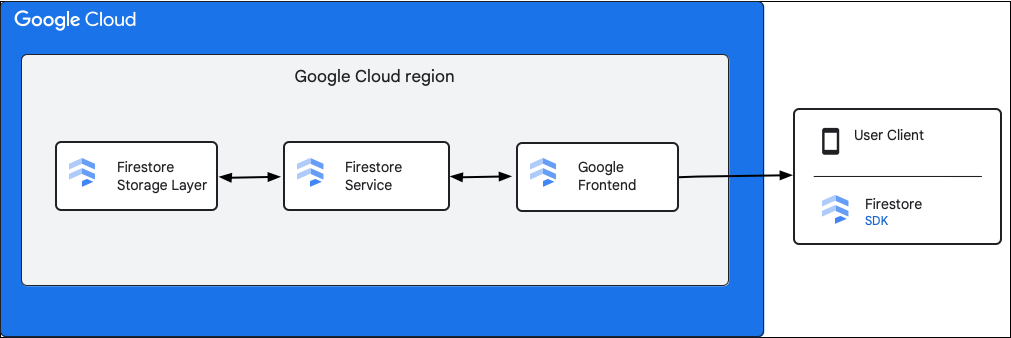
Cloud Firestore SDK וספריות לקוח
Cloud Firestore תומך בערכות SDK ובספריות לקוח לפלטפורמות שונות. אפליקציה יכולה לבצע קריאות HTTP ו-RPC ישירות ל-Cloud Firestore API, אבל ספריות הלקוח מספקות שכבת הפשטה כדי לפשט את השימוש ב-API וליישם שיטות מומלצות. הם עשויים לספק גם תכונות נוספות כמו גישה אופליין, מטמונים וכו'.
ממשק קצה של Google (GFE)
זהו שירות תשתיתי שמשותף לכל שירותי הענן של Google. ממשק הקצה של Google (GFE) מקבל בקשות נכנסות ומעביר אותן לשירות Google הרלוונטי (שירות Cloud Firestore בהקשר הזה). הוא גם מספק פונקציות חשובות אחרות, כולל הגנה מפני התקפות מניעת שירות (DoS).
שירות Cloud Firestore
שירות Cloud Firestore מבצע בדיקות של בקשת ה-API, כולל אימות, הרשאה, בדיקות של מכסת השימוש וכללי אבטחה, ומנהל גם עסקאות. שירות Cloud Firestore כולל לקוח אחסון שמתקשר עם שכבת האחסון לצורך קריאה וכתיבה של נתונים.
שכבת אחסון בנפח Cloud Firestore
שכבת האחסון Cloud Firestore אחראית לאחסון הנתונים והמטא-נתונים, ולתכונות של מסד הנתונים שמשויכות ל-Cloud Firestore. בקטעים הבאים מוסבר איך הנתונים מאורגנים בשכבת האחסון Cloud Firestore ואיך המערכת מתרחבת. הבנת האופן שבו הנתונים מאורגנים יכולה לעזור לכם לעצב מודל נתונים שניתן להרחבה ולהבין טוב יותר את השיטות המומלצות ב-Cloud Firestore.
טווחים ופיצולים של מקשים
Cloud Firestore הוא מסד נתונים מסוג NoSQL שמבוסס על מסמכים. הנתונים מאוחסנים במסמכים, שמסודרים בהיררכיות של אוספים. היררכיית האוסף ומזהה המסמך מתורגמים למפתח יחיד לכל מסמך. המסמכים מאוחסנים באופן לוגי ומסודרים לקסיקוגרפית לפי המפתח היחיד הזה. אנחנו משתמשים במונח 'טווח מפתחות' כדי להתייחס לטווח רציף של מפתחות בסדר לקסיקוגרפי.
מסד נתונים טיפוסי של Cloud Firestore גדול מדי מכדי להיכנס למכונה פיזית אחת. יש גם תרחישים שבהם עומס העבודה על הנתונים כבד מדי בשביל שמכונה אחת תוכל לטפל בו. כדי לטפל בעומסי עבודה גדולים, Cloud Firestore מחלק את הנתונים לחלקים נפרדים שאפשר לאחסן במכונות מרובות או בשרתי אחסון ולשלוף מהם נתונים. החלוקה הזו מתבצעת בטבלאות של מסד הנתונים בבלוקים של טווחי מפתחות שנקראים פיצולים.
שכפול סינכרוני
חשוב לציין שהמסד נתונים תמיד משוכפל באופן אוטומטי וסינכרוני. לפילוגים של הנתונים יש רפליקות באזורים שונים, כדי שהם יישארו זמינים גם אם לא תהיה גישה לאזור מסוים. השכפול העקבי של העותקים השונים של הפיצול מנוהל על ידי אלגוריתם Paxos להשגת הסכמה. עותק אחד של כל פיצול נבחר לפעול כמנהיג Paxos, שאחראי לטיפול בפעולות כתיבה לפיצול הזה. השכפול הסינכרוני מאפשר לכם תמיד לקרוא את הגרסה העדכנית ביותר של הנתונים מ-Cloud Firestore.
התוצאה הכוללת היא מערכת ניתנת להרחבה עם זמינות גבוהה, שמספקת זמני אחזור נמוכים לקריאה ולכתיבה, ללא קשר לעומסי עבודה כבדים ובקנה מידה גדול מאוד.
פריסת הנתונים
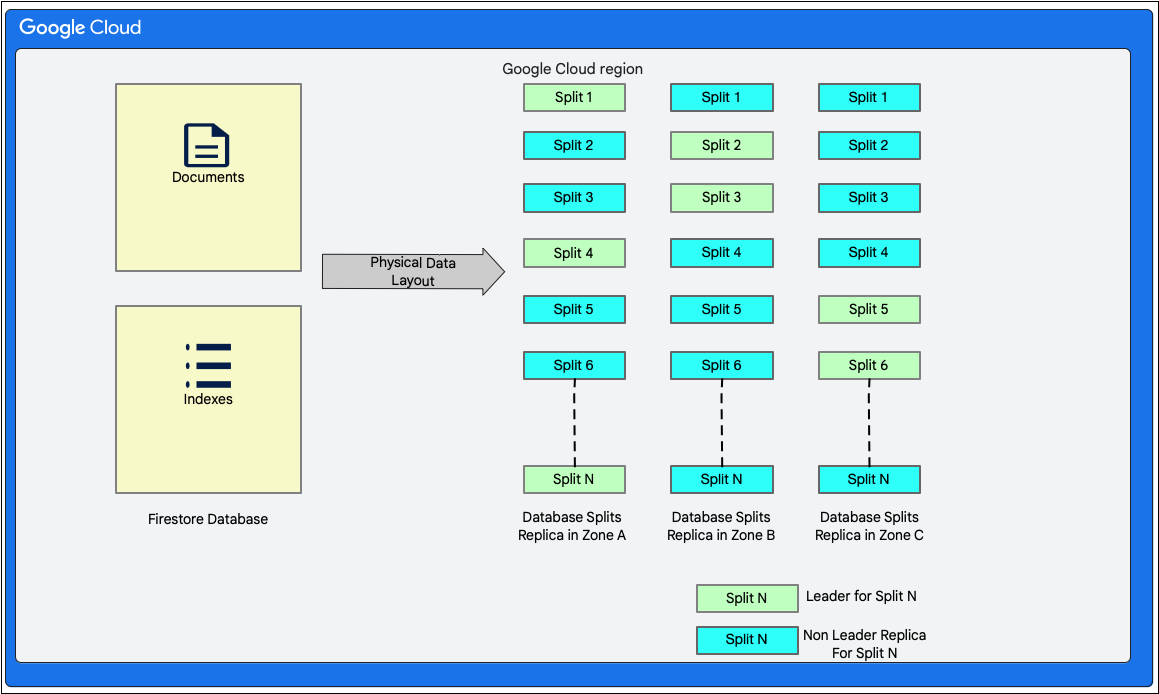
Cloud Firestore הוא מסד נתונים של מסמכים ללא סכימה. עם זאת, באופן פנימי, הנתונים מסודרים בעיקר בשתי טבלאות בסגנון של מסד נתונים יחסי בשכבת האחסון, באופן הבא:
- טבלת Documents: המסמכים מאוחסנים בטבלה הזו.
- טבלת Indexes: בטבלה הזו מאוחסנים רשומות אינדקס שמאפשרות לקבל תוצאות ביעילות ולמיין אותן לפי ערך האינדקס.
בתרשים הבא מוצגות טבלאות של מסד נתונים Cloud Firestore עם פיצולים. הפיצולים משוכפלים בשלושה אזורים שונים, ולכל פיצול מוקצה מנהיג Paxos.
אזור יחיד לעומת מספר אזורים
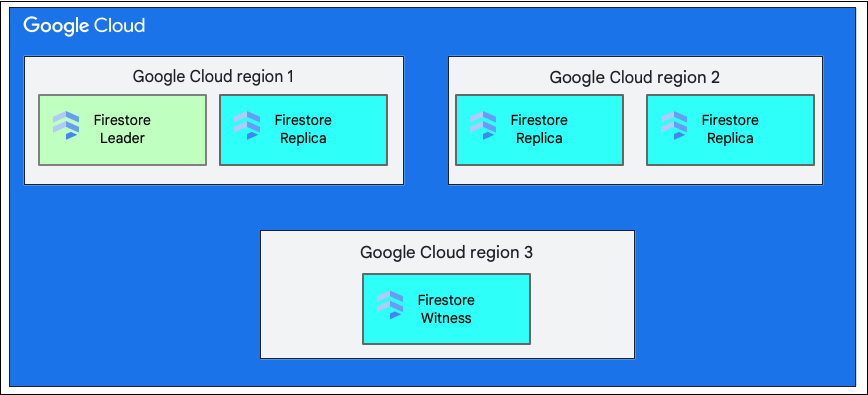
כשיוצרים מסד נתונים, צריך לבחור אזור או אזור גיאוגרפי נרחב יותר שכולל מספר אזורים.
מיקום אזורי יחיד הוא מיקום גיאוגרפי ספציפי, כמו us-west1. כמו שהוסבר קודם, לנתונים של מסד נתונים מסוג Cloud Firestore יש רפליקות באזורים שונים בתוך האזור שנבחר.
מיקום רב-אזורי כולל קבוצה מוגדרת של אזורים שבהם מאוחסנות רפליקות של מסד הנתונים. בפריסה של Cloud Firestore במספר אזורים, שניים מהאזורים כוללים רפליקות מלאות של כל הנתונים במסד הנתונים. באזור שלישי יש עותק משני של עֵד שלא מכיל את כל הנתונים, אבל משתתף בשכפול. העתקת הנתונים בין כמה אזורים מאפשרת לכתוב ולקרוא נתונים גם במקרה של אובדן אזור שלם.
מידע נוסף על המיקומים של אזור זמין במאמר Cloud Firestore מיקומים.
הסבר על מחזור החיים של פעולת כתיבה ב-Cloud Firestore
Cloud Firestore לקוח יכול לכתוב נתונים על ידי יצירה, עדכון או מחיקה של מסמך יחיד. כתיבה למסמך יחיד מחייבת עדכון אטומי של המסמך ושל רשומות האינדקס שמשויכות אליו בשכבת האחסון. Cloud Firestore תומך גם בפעולות אטומיות שכוללות כמה קריאות או כתיבות למסמך אחד או יותר.
לכל סוגי הכתיבה, Cloud Firestore מספק את מאפייני ה-ACID (אטומיות, עקביות, בידוד ועמידות) של מסדי נתונים יחסיים. Cloud Firestore מספק גם אפשרות להרצה טורית, כלומר כל העסקאות מוצגות כאילו הן בוצעו בסדר טור.
שלבים כלליים בעסקת כתיבה
כשלקוח Cloud Firestore מבצע פעולת כתיבה או מאשר עסקה באמצעות אחת מהשיטות שצוינו קודם, הפעולה הזו מבוצעת באופן פנימי כעסקה של קריאה וכתיבה במסד נתונים בשכבת האחסון. הטרנזקציה מאפשרת ל-Cloud Firestore לספק את מאפייני ה-ACID שצוינו קודם.
בשלב הראשון של העסקה, Cloud Firestore קורא את המסמך הקיים וקובע את השינויים שיש לבצע בנתונים בטבלת המסמכים.
הפעולה הזו כוללת גם ביצוע עדכונים נדרשים בטבלת האינדקסים, באופן הבא:
- לשדות שמוסיפים למסמכים צריך להוסיף הוספות תואמות בטבלת האינדקסים.
- כשמסירים שדות מהמסמכים, צריך להסיר אותם גם מטבלת האינדקסים.
- בשדות שמשתנים במסמכים, צריך גם מחיקות (של ערכים ישנים) וגם הוספות (של ערכים חדשים) בטבלת האינדקסים.
כדי לחשב את המוטציות שצוינו קודם, Cloud Firestore קורא את הגדרת האינדקס של הפרויקט. הגדרת האינדקס שומרת מידע על האינדקסים של הפרויקט. Cloud Firestore משתמש בשני סוגים של אינדקסים: אינדקסים של שדה יחיד ואינדקסים מורכבים. כדי להבין לעומק את האינדקסים שנוצרו ב-Cloud Firestore, אפשר לעיין במאמר סוגי אינדקסים ב-Cloud Firestore.
אחרי שהמוטציות מחושבות, Cloud Firestore אוסף אותן בתוך טרנזקציה ואז מבצע commit.
הסבר על עסקת כתיבה בשכבת האחסון
כמו שצוין קודם, פעולת כתיבה ב-Cloud Firestore כוללת טרנזקציה של קריאה וכתיבה בשכבת האחסון. בהתאם לפריסת הנתונים, פעולת כתיבה עשויה לכלול פיצול אחד או יותר, כפי שמוצג בפריסת הנתונים.
בתרשים הבא, מסד הנתונים Cloud Firestore מחולק לשמונה חלקים (מסומנים ב-1 עד 8) שמתארחים בשלושה שרתי אחסון שונים באותו אזור, וכל חלק משוכפל ב-3(או יותר) אזורים שונים. לכל פיצול יש מנהיג Paxos, שיכול להיות באזור אחר עבור פיצולים שונים.
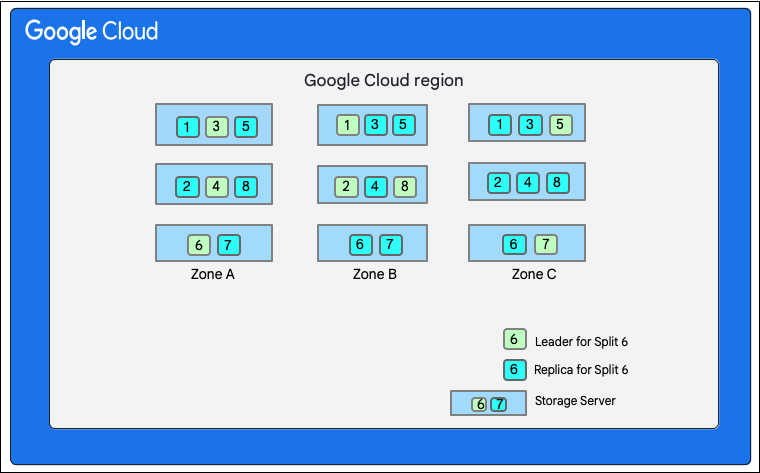 פיצול מסד נתונים ב-Cloud Firestore">
פיצול מסד נתונים ב-Cloud Firestore">
נניח שיש מסד נתונים Cloud Firestore עם אוסף Restaurants באופן הבא:
לקוח Cloud Firestore מבקש לבצע את השינוי הבא במסמך באוסף Restaurant על ידי עדכון הערך של השדה priceCategory.
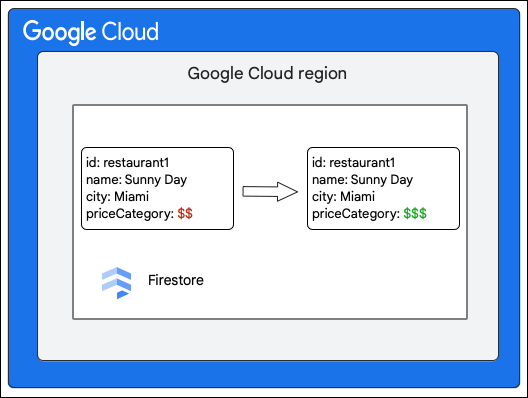
בשלבים הבאים מוסבר מה קורה במהלך הכתיבה:
- יוצרים טרנזקציה עם הרשאות קריאה וכתיבה.
- קריאת המסמך
restaurant1באוסףRestaurantsמהטבלה Documents משכבת האחסון. - קוראים את האינדקסים של המסמך מהטבלה Indexes.
- מחשבים את השינויים שצריך לבצע בנתונים. במקרה הזה, יש חמישה שינויים:
- M1: מעדכנים את השורה של
restaurant1בטבלה Documents כך שתשקף את השינוי בערך של השדהpriceCategory. - M2 ו-M3: מוחקים את השורות של הערך הישן של
priceCategoryבטבלה Indexes (אינדקסים) עבור אינדקסים בסדר יורד ואינדקסים בסדר עולה. - M4 ו-M5: מוסיפים את השורות לערך החדש של
priceCategoryבטבלה Indexes לאינדקסים בסדר יורד ועולה.
- M1: מעדכנים את השורה של
- מאשרים את המוטציות האלה.
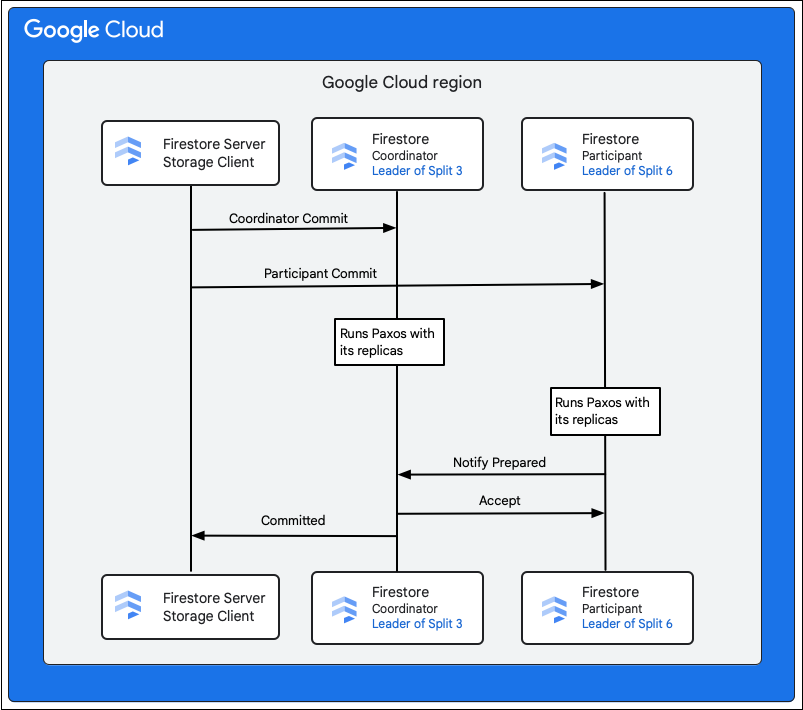
לקוח האחסון בשירות Cloud Firestore מחפש את הפיצולים שכוללים את המפתחות של השורות שרוצים לשנות. נניח שפיצול 3 מציג את M1, ופיצול 6 מציג את M2 עד M5. מדובר בעסקה מבוזרת, שבה כל הפיצולים האלה הם משתתפים. הפיצולים של המשתתפים עשויים לכלול גם פיצולים אחרים שמהם נתונים נקראו קודם כחלק מעסקת הקריאה והכתיבה.
בשלבים הבאים מתואר מה קורה כחלק מההתחייבות:
- לקוח האחסון שולח אישור. השמירה מכילה את המוטציות M1-M5.
- הפיצולים 3 ו-6 הם המשתתפים בעסקה הזו. אחד מהמשתתפים נבחר להיות המתאם, כמו פיצול 3. תפקיד המתאם הוא לוודא שהעסקה מתבצעת או מבוטלת באופן אטומי אצל כל המשתתפים.
- העותקים המובילים של הפיצולים האלה אחראים לעבודה שמבצעים המשתתפים והמתאמים.
- כל משתתף וכל מתאם מריצים אלגוריתם Paxos עם העותקים המתאימים שלהם.
- המוביל מריץ אלגוריתם Paxos עם העותקים. הקונצנזוס מושג אם רוב העותקים משיבים למנהיג בתגובה
ok to commit. - כל משתתף מודיע לרכז שהוא מוכן (השלב הראשון מתוך שני שלבים של אישור). אם אחד מהמשתתפים לא יכול לאשר את העסקה, העסקה כולה
aborts.
- המוביל מריץ אלגוריתם Paxos עם העותקים. הקונצנזוס מושג אם רוב העותקים משיבים למנהיג בתגובה
- אחרי שהמתאם יודע שכל המשתתפים, כולל הוא עצמו, מוכנים, הוא מעביר את תוצאת העסקה
acceptלכל המשתתפים (השלב השני של אישור דו-שלבי). בשלב הזה, כל משתתף מתעד את החלטת האישור באחסון יציב והעסקה מאושרת. - המתאם משיב ללקוח האחסון ב-Cloud Firestore שהעסקה בוצעה. במקביל, הרכיב המתאם וכל המשתתפים מחילים את השינויים על הנתונים.
כשמסד הנתונים Cloud Firestore קטן, יכול להיות שפיצול יחיד יחזיק בכל המפתחות במוטציות M1-M5. במקרה כזה, יש רק משתתף אחד בעסקה, ולא נדרשת התחייבות דו-שלבית שצוינה קודם, ולכן פעולות הכתיבה מהירות יותר.
כתיבה במספר אזורים
בפריסה מרובת אזורים, פיזור העותקים המשוכפלים בין האזורים מגדיל את הזמינות, אבל יש לכך השפעה על הביצועים. התקשורת בין העותקים באזורים שונים אורכת יותר זמן. לכן, זמן האחזור הבסיסי לפעולות Cloud Firestore גבוה קצת יותר בהשוואה לפריסות באזור יחיד.
אנחנו מגדירים את העותקים המשוכפלים כך שההובלה של הפיצולים תמיד תישאר באזור הראשי. האזור הראשי הוא האזור שממנו מגיעה תנועת הגולשים לשרת Cloud Firestore. ההחלטה הזו של ההנהלה מקטינה את זמן הטעינה הלוך ושוב בתקשורת בין לקוח האחסון ב-Cloud Firestore לבין העותק הראשי (או הרכיב המתאם לעסקאות מרובות פיצולים).
כל פעולת כתיבה ב-Cloud Firestore כוללת גם אינטראקציה עם מנוע בזמן אמת ב-Cloud Firestore. מידע נוסף על שאילתות בזמן אמת זמין במאמר הסבר על שאילתות בזמן אמת בהיקף גדול.
הסבר על מחזור החיים של קריאה ב-Cloud Firestore
בקטע הזה נסביר על קריאות עצמאיות שלא מתבצעות בזמן אמת ב-Cloud Firestore. באופן פנימי, שרת Cloud Firestore מטפל ברוב השאילתות האלה בשני שלבים עיקריים:
- סריקה של טווח יחיד בטבלת האינדקסים
- חיפושים נקודתיים בטבלה מסמכים על סמך תוצאות הסריקה הקודמת
קריאות הנתונים משכבת האחסון מתבצעות באופן פנימי באמצעות טרנזקציה של מסד נתונים, כדי להבטיח קריאות עקביות. עם זאת, בניגוד לטרנזקציות שמשמשות לכתיבה, הטרנזקציות האלה לא נועלות את הנתונים. במקום זאת, הן פועלות על ידי בחירת חותמת זמן, ואז ביצוע כל הקריאות בחותמת הזמן הזו. מכיוון שהן לא נועלות את הנתונים, הן לא חוסמות טרנזקציות מקבילות של קריאה וכתיבה. כדי לבצע את הטרנזקציה הזו, לקוח האחסון ב-Cloud Firestore מציין גבול של חותמת זמן, שמציין לשכבת האחסון איך לבחור חותמת זמן לקריאה. סוג הגבול של חותמת הזמן שנבחר על ידי לקוח האחסון ב-Cloud Firestore נקבע לפי אפשרויות הקריאה של בקשת הקריאה.
הסבר על עסקת קריאה בשכבת האחסון
בקטע הזה מתוארים סוגי הקריאות ואופן העיבוד שלהן בשכבת האחסון ב-Cloud Firestore.
קריאות חזקות
כברירת מחדל, קריאות Cloud Firestore הן עקביות חזקה. העקביות החזקה הזו אומרת שקריאה של Cloud Firestore מחזירה את הגרסה האחרונה של הנתונים שמשקפת את כל פעולות הכתיבה שבוצעו עד תחילת הקריאה.
קריאה של מסך מפוצל יחיד
לקוח האחסון ב-Cloud Firestore מחפש את הפיצולים שבבעלותם המפתחות של השורות שצריך לקרוא. נניח שהיא צריכה לקרוא מ-Split 3 מהקטע הקודם. הלקוח שולח את בקשת הקריאה לרפליקה הקרובה ביותר כדי לצמצם את זמן האחזור של הלוך ושוב.
בשלב הזה, יכולים לקרות המקרים הבאים, בהתאם לשכפול שנבחר:
- בקשת קריאה מועברת לרפליקה ראשית (אזור א').
- המוביל תמיד מעודכן, ולכן הקריאה יכולה להתבצע ישירות.
- בקשת קריאה מועברת לרפליקה שהיא לא רפליקת הלידר (לדוגמה, אזור ב')
- יכול להיות ש-Split 3 ידע לפי המצב הפנימי שלו שיש לו מספיק מידע כדי להציג את הקריאה, והוא יעשה זאת.
- השרת Split 3 לא בטוח אם הוא קיבל את הנתונים האחרונים. הוא שולח הודעה לשרת הראשי כדי לבקש את חותמת הזמן של העסקה האחרונה שהוא צריך להחיל כדי להציג את הקריאה. אחרי שהעסקה הזו מוחלת, אפשר להמשיך בקריאה.
Cloud Firestore ומחזירה את התגובה ללקוח שלה.
קריאה עם פיצול מסך
במצב שבו צריך לקרוא נתונים מכמה פיצולים, אותו מנגנון פועל בכל הפיצולים. אחרי שהנתונים מוחזרים מכל הפיצולים, לקוח האחסון ב-Cloud Firestore משלב את התוצאות. Cloud Firestore משיבה ללקוח עם הנתונים האלה.
קריאות לא עדכניות
קריאות חזקות הן מצב ברירת המחדל ב-Cloud Firestore. עם זאת, הן עלולות לגרום לזמן אחזור גבוה יותר בגלל התקשורת שנדרשת עם הלידר. בדרך כלל, לאפליקציית Cloud Firestore לא נדרשת קריאה של הגרסה האחרונה של הנתונים, והפונקציונליות פועלת היטב עם נתונים שעברו כמה שניות מאז העדכון האחרון שלהם.
במקרה כזה, הלקוח יכול לבחור לקבל קריאות לא עדכניות באמצעות read_time אפשרויות הקריאה. במקרה הזה, פעולות הקריאה מתבצעות כשהנתונים היו ב-read_time, וככל הנראה העותק המשוכפל הכי קרוב כבר אימת שיש בו נתונים ב-read_time שצוין.
כדי ליהנות מביצועים טובים יותר באופן משמעותי, כדאי להגדיר ערך של 15 שניות. גם בקריאות לא עדכניות, השורות שמתקבלות עקביות זו עם זו.
הימנעות מנקודות חמות
הפיצולים ב-Cloud Firestore מפורקים אוטומטית לחלקים קטנים יותר כדי לחלק את העבודה של הצגת התנועה ליותר שרתי אחסון כשצריך או כשמרחב המפתחות מתרחב. פיצולים שנוצרו כדי לטפל בעודף תנועה נשמרים למשך כ-24 שעות, גם אם התנועה נעלמת. לכן, אם יש עליות חוזרות בתנועה, הפיצולים נשמרים ונוספים עוד פיצולים כשנדרש. המנגנונים האלה עוזרים למסדי נתונים של Cloud Firestore לבצע שינוי גודל אוטומטי תחת עומס תנועה או גודל מסד נתונים גדל. עם זאת, יש כמה מגבלות שכדאי להכיר, כפי שמוסבר בהמשך.
פיצול האחסון והעומס לוקח זמן, והגדלת נפח התנועה מהר מדי עלולה לגרום לזמן אחזור גבוה או לשגיאות של חריגה מהזמן הקצוב לתפוגה, שנקראות בדרך כלל נקודות חמות, בזמן שהשירות מבצע התאמות. השיטה המומלצת היא לפזר את הפעולות על פני טווח המפתחות, תוך הגדלת התנועה באוסף במסד נתונים עם 500 פעולות בשנייה. אחרי העלייה ההדרגתית הזו, מגדילים את התנועה ב-50% כל חמש דקות. התהליך הזה נקרא כלל 500/50/5, והוא מאפשר למסד הנתונים להתרחב בצורה אופטימלית כדי לעמוד בעומס העבודה.
למרות שהפיצולים נוצרים באופן אוטומטי עם העלייה בעומס, Cloud Firestore יכול לפצל טווח מפתחות רק עד שהוא משרת מסמך יחיד באמצעות קבוצה ייעודית של שרתי אחסון משוכפלים. כתוצאה מכך, נפחים גבוהים ומתמשכים של פעולות בו-זמניות במסמך יחיד עלולים להוביל לנקודה חמה במסמך הזה. אם נתקלתם בחביון גבוה באופן קבוע במסמך יחיד, כדאי לשקול לשנות את מודל הנתונים כדי לפצל את הנתונים או לשכפל אותם בכמה מסמכים.
שגיאות של התנגשות מתרחשות כשכמה פעולות מנסות לקרוא ו/או לכתוב את אותו מסמך בו-זמנית.
מקרה מיוחד נוסף של נקודות חמות מתרחש כשמשתמשים במפתח עם ערכים עולים או יורדים ברצף כמזהה המסמך ב-Cloud Firestore, ויש מספר גבוה במיוחד של פעולות בשנייה. במקרה כזה, יצירת פיצולים נוספים לא תעזור, כי העלייה החדה בתנועה פשוט תעבור לפיצול החדש שנוצר. מכיוון ש-Cloud Firestore יוצר אינדקס אוטומטי לכל השדות במסמך כברירת מחדל, יכול להיות שנקודות חמות כאלה ייווצרו גם במרחב האינדקס של שדה מסמך שמכיל ערך עם עלייה או ירידה ברצף, כמו חותמת זמן.
שימו לב: אם תפעלו לפי השיטות המומלצות שמתוארות למעלה, Cloud Firestore יוכל להתרחב כדי לטפל בעומסי עבודה גדולים ככל שיידרש, בלי שתצטרכו לשנות את ההגדרות.
פתרון בעיות
Cloud Firestore מספקת את Key Visualizer ככלי אבחון שנועד לנתח דפוסי שימוש ולפתור בעיות שקשורות לנקודות חמות.