
L'API Codable de Swift, lancée dans Swift 4, nous permet d'exploiter la puissance du compilateur pour mapper plus facilement les données des formats sérialisés vers les types Swift.
Vous avez peut-être utilisé Codable pour mapper les données d'une API Web au modèle de données de votre application (et vice versa), mais il est beaucoup plus flexible que cela.
Dans ce guide, nous allons voir comment utiliser Codable pour mapper les données de Cloud Firestore vers des types Swift et vice versa.
Lorsque vous récupérez un document à partir de Cloud Firestore, votre application reçoit un dictionnaire de paires clé/valeur (ou un tableau de dictionnaires, si vous utilisez l'une des opérations renvoyant plusieurs documents).
Vous pouvez bien sûr continuer à utiliser directement les dictionnaires en Swift. Ils offrent une grande flexibilité qui pourrait être exactement ce dont votre cas d'utilisation a besoin. Toutefois, cette approche n'est pas sûre en termes de type et il est facile d'introduire des bugs difficiles à traquer en orthographiant mal les noms d'attributs ou en oubliant de mapper le nouvel attribut que votre équipe a ajouté lors du lancement de cette nouvelle fonctionnalité la semaine dernière.
Par le passé, de nombreux développeurs ont contourné ces lacunes en implémentant une simple couche de mappage qui leur permettait de mapper des dictionnaires à des types Swift. Mais, encore une fois, la plupart de ces implémentations sont basées sur la spécification manuelle du mappage entre les documents Cloud Firestore et les types correspondants du modèle de données de votre application.
Grâce à la compatibilité de Cloud Firestore avec l'API Codable de Swift, cela devient beaucoup plus facile :
- Vous n'aurez plus à implémenter manuellement de code de mappage.
- Il est facile de définir comment mapper des attributs portant des noms différents.
- Il est compatible avec de nombreux types Swift.
- Il est également facile d'ajouter la prise en charge du mappage de types personnalisés.
- Le meilleur de tout : pour les modèles de données simples, vous n'aurez pas à écrire de code de mappage.
Données de mappage
Cloud Firestore stocke les données dans des documents qui mappent les clés aux valeurs. Pour extraire des données d'un document individuel, nous pouvons appeler DocumentSnapshot.data(), qui renvoie un dictionnaire mappant les noms de champs à un Any :
func data() -> [String : Any]?.
Cela signifie que nous pouvons utiliser la syntaxe d'indice de Swift pour accéder à chaque champ individuel.
import FirebaseFirestore
#warning("DO NOT MAP YOUR DOCUMENTS MANUALLY. USE CODABLE INSTEAD.")
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
let id = document.documentID
let data = document.data()
let title = data?["title"] as? String ?? ""
let numberOfPages = data?["numberOfPages"] as? Int ?? 0
let author = data?["author"] as? String ?? ""
self.book = Book(id:id, title: title, numberOfPages: numberOfPages, author: author)
}
}
}
}
Bien qu'il puisse sembler simple et facile à implémenter, ce code est fragile, difficile à gérer et sujet aux erreurs.
Comme vous pouvez le voir, nous faisons des hypothèses sur les types de données des champs du document. Elles peuvent être correctes ou non.
N'oubliez pas que, comme il n'y a pas de schéma, vous pouvez facilement ajouter un document à la collection et choisir un autre type pour un champ. Vous pouvez choisir accidentellement la chaîne pour le champ numberOfPages, ce qui entraînerait un problème de mappage difficile à trouver. De plus, vous devrez mettre à jour votre code de mappage chaque fois qu'un nouveau champ sera ajouté, ce qui est plutôt fastidieux.
N'oublions pas que nous ne profitons pas du système de typage fort de Swift, qui connaît exactement le type correct pour chacune des propriétés de Book.
Qu'est-ce que Codable ?
Selon la documentation d'Apple, Codable est "un type qui peut se convertir en représentation externe et inversement". En fait, Codable est un alias de type pour les protocoles Encodable et Decodable. En rendant un type Swift conforme à ce protocole, le compilateur synthétisera le code nécessaire pour encoder/décoder une instance de ce type à partir d'un format sérialisé, tel que JSON.
Un type simple pour stocker des données sur un livre peut se présenter comme suit :
struct Book: Codable {
var title: String
var numberOfPages: Int
var author: String
}
Comme vous pouvez le constater, la conformité du type à Codable est peu invasive. Nous n'avons eu qu'à ajouter la conformité au protocole. Aucune autre modification n'était requise.
Maintenant que cela est en place, nous pouvons facilement encoder un livre en objet JSON :
do {
let book = Book(title: "The Hitchhiker's Guide to the Galaxy",
numberOfPages: 816,
author: "Douglas Adams")
let encoder = JSONEncoder()
let data = try encoder.encode(book)
}
catch {
print("Error when trying to encode book: \(error)")
}
Le décodage d'un objet JSON en instance Book fonctionne comme suit :
let decoder = JSONDecoder()
let data = /* fetch data from the network */
let decodedBook = try decoder.decode(Book.self, from: data)
Mappage vers et depuis des types simples dans les documents Cloud Firestore à l'aide de Codable
Cloud Firestore est compatible avec un large éventail de types de données, allant des chaînes simples aux cartes imbriquées. La plupart d'entre eux correspondent directement aux types intégrés de Swift. Commençons par examiner le mappage de certains types de données simples avant de passer aux plus complexes.
Pour mapper les documents Cloud Firestore aux types Swift, procédez comme suit :
- Assurez-vous d'avoir ajouté le framework
FirebaseFirestoreà votre projet. Pour ce faire, vous pouvez utiliser Swift Package Manager ou CocoaPods. - Importez
FirebaseFirestoredans votre fichier Swift. - Conformez votre type à
Codable. - (Facultatif, si vous souhaitez utiliser le type dans une vue
List) Ajoutez une propriétéidà votre type et utilisez@DocumentIDpour indiquer à Cloud Firestore de mapper cette propriété à l'ID du document. Nous aborderons ce point plus en détail ci-dessous. - Utilisez
documentReference.data(as: )pour mapper une référence de document à un type Swift. - Utilisez
documentReference.setData(from: )pour mapper les données des types Swift vers un document Cloud Firestore. - (Facultatif, mais vivement recommandé) Implémentez une gestion des erreurs appropriée.
Mettons à jour notre type Book en conséquence :
struct Book: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
}
Comme ce type était déjà codable, nous n'avons eu qu'à ajouter la propriété id et à l'annoter avec le wrapper de propriété @DocumentID.
En reprenant l'extrait de code précédent pour extraire et mapper un document, nous pouvons remplacer tout le code de mappage manuel par une seule ligne :
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
do {
self.book = try document.data(as: Book.self)
}
catch {
print(error)
}
}
}
}
}
Vous pouvez écrire cela de manière encore plus concise en spécifiant le type de document lors de l'appel de getDocument(as:). Cela effectuera le mappage pour vous et renverra un type Result contenant le document mappé ou une erreur en cas d'échec du décodage :
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
Pour mettre à jour un document existant, il vous suffit d'appeler documentReference.setData(from: ). Voici le code permettant d'enregistrer une instance Book, y compris une gestion des exceptions de base :
func updateBook(book: Book) {
if let id = book.id {
let docRef = db.collection("books").document(id)
do {
try docRef.setData(from: book)
}
catch {
print(error)
}
}
}
Lorsque vous ajoutez un document, Cloud Firestore se charge automatiquement de lui attribuer un nouvel ID. Cela fonctionne même lorsque l'application est actuellement hors connexion.
func addBook(book: Book) {
let collectionRef = db.collection("books")
do {
let newDocReference = try collectionRef.addDocument(from: self.book)
print("Book stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
En plus de mapper des types de données simples, Cloud Firestore est compatible avec un certain nombre d'autres types de données, dont certains sont des types structurés que vous pouvez utiliser pour créer des objets imbriqués dans un document.
Types personnalisés imbriqués
La plupart des attributs que nous souhaitons mapper dans nos documents sont des valeurs simples, telles que le titre du livre ou le nom de l'auteur. Mais qu'en est-il des cas où nous devons stocker un objet plus complexe ? Par exemple, nous pouvons stocker les URL de la couverture du livre dans différentes résolutions.
Le moyen le plus simple de le faire dans Cloud Firestore est d'utiliser une carte :

Lorsque nous écrivons la structure Swift correspondante, nous pouvons utiliser le fait que Cloud Firestore prend en charge les URL. Lorsque nous stockons un champ contenant une URL, il est converti en chaîne et inversement :
struct CoverImages: Codable {
var small: URL
var medium: URL
var large: URL
}
struct BookWithCoverImages: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var cover: CoverImages?
}
Notez que nous avons défini une structure, CoverImages, pour la carte de couverture dans le document Cloud Firestore. En marquant la propriété de couverture sur BookWithCoverImages comme facultative, nous pouvons gérer le fait que certains documents ne contiennent pas d'attribut de couverture.
Si vous vous demandez pourquoi il n'y a pas d'extrait de code pour récupérer ou mettre à jour des données, sachez qu'il n'est pas nécessaire d'ajuster le code pour lire ou écrire à partir de/vers Cloud Firestore : tout cela fonctionne avec le code que nous avons écrit dans la section initiale.
Tableaux
Parfois, nous souhaitons stocker une collection de valeurs dans un document. Les genres d'un livre en sont un bon exemple : un livre comme Le Guide du voyageur galactique peut appartenir à plusieurs catégories, en l'occurrence "Science-fiction" et "Comédie" :

Dans Cloud Firestore, nous pouvons modéliser cela à l'aide d'un tableau de valeurs. Cette fonctionnalité est compatible avec tous les types codables (tels que String, Int, etc.). L'exemple suivant montre comment ajouter un tableau de genres à notre modèle Book :
public struct BookWithGenre: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var genres: [String]
}
Comme cela fonctionne pour n'importe quel type codable, nous pouvons également utiliser des types personnalisés. Imaginons que nous voulions stocker une liste de tags pour chaque livre. En plus du nom du tag, nous aimerions également stocker sa couleur, comme ceci :
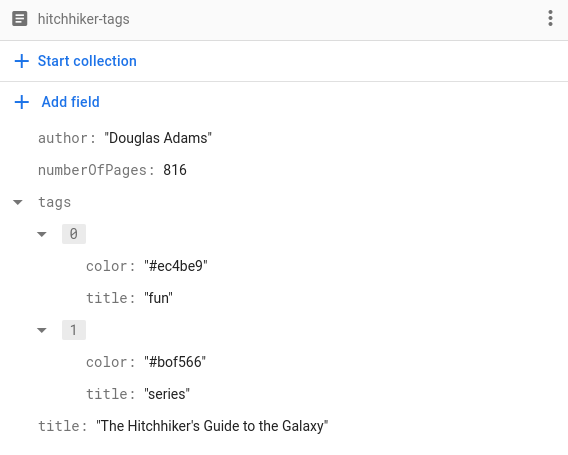
Pour stocker les tags de cette manière, il suffit d'implémenter une structure Tag pour représenter un tag et le rendre codable :
struct Tag: Codable, Hashable {
var title: String
var color: String
}
Et voilà, nous pouvons stocker un tableau de Tags dans nos documents Book !
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Quelques mots sur le mappage des ID de document
Avant de passer au mappage d'autres types, parlons un instant du mappage des ID de document.
Nous avons utilisé le wrapper de propriété @DocumentID dans certains des exemples précédents pour mapper l'ID de document de nos documents Cloud Firestore à la propriété id de nos types Swift. C'est important pour plusieurs raisons :
- Cela nous aide à savoir quel document mettre à jour si l'utilisateur apporte des modifications locales.
- Le
Listde SwiftUI exige que ses éléments soientIdentifiablepour éviter qu'ils ne sautent lorsqu'ils sont insérés.
Il est important de noter qu'un attribut marqué comme @DocumentID ne sera pas encodé par l'encodeur de Cloud Firestore lors de la réécriture du document. En effet, l'ID du document n'est pas un attribut du document lui-même. L'écrire dans le document serait donc une erreur.
Lorsque vous travaillez avec des types imbriqués (tels que le tableau de tags sur Book dans un exemple précédent de ce guide), il n'est pas nécessaire d'ajouter une propriété @DocumentID : les propriétés imbriquées font partie du document Cloud Firestore et ne constituent pas un document distinct. Par conséquent, ils n'ont pas besoin d'ID de document.
Dates et heures
Cloud Firestore dispose d'un type de données intégré pour gérer les dates et les heures. Grâce à la compatibilité de Cloud Firestore avec Codable, il est facile de les utiliser.
Examinons ce document qui représente la mère de tous les langages de programmation, Ada, inventé en 1843 :

Un type Swift pour mapper ce document peut se présenter comme suit :
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
}
Nous ne pouvons pas quitter cette section sur les dates et heures sans parler de @ServerTimestamp. Ce wrapper de propriété est un outil puissant pour gérer les codes temporels dans votre application.
Dans tout système distribué, il est probable que les horloges des systèmes individuels ne soient pas complètement synchronisées en permanence. Vous pensez peut-être que ce n'est pas un problème majeur, mais imaginez les conséquences d'une horloge légèrement désynchronisée pour un système de transactions boursières : même un écart d'une milliseconde peut entraîner une différence de plusieurs millions de dollars lors de l'exécution d'une transaction.
Cloud Firestore gère les attributs marqués avec @ServerTimestamp comme suit : si l'attribut est nil lorsque vous le stockez (à l'aide de addDocument(), par exemple), Cloud Firestore remplira le champ avec l'horodatage actuel du serveur au moment de l'écriture dans la base de données. Si le champ n'est pas nil lorsque vous appelez addDocument() ou updateData(), Cloud Firestore laisse la valeur de l'attribut intacte. Il est ainsi facile d'implémenter des champs tels que createdAt et lastUpdatedAt.
Points géographiques
Les géolocalisations sont omniprésentes dans nos applications. Le stockage de ces données permet de proposer de nombreuses fonctionnalités intéressantes. Par exemple, il peut être utile de stocker un lieu pour une tâche afin que votre application puisse vous rappeler une tâche lorsque vous atteignez une destination.
Cloud Firestore dispose d'un type de données intégré, GeoPoint, qui peut stocker la longitude et la latitude de n'importe quel lieu. Pour mapper des lieux depuis/vers un document Cloud Firestore, nous pouvons utiliser le type GeoPoint :
struct Office: Codable {
@DocumentID var id: String?
var name: String
var location: GeoPoint
}
Le type correspondant en Swift est CLLocationCoordinate2D, et nous pouvons mapper ces deux types avec l'opération suivante :
CLLocationCoordinate2D(latitude: office.location.latitude,
longitude: office.location.longitude)
Pour en savoir plus sur l'interrogation de documents par emplacement physique, consultez ce guide de solutions.
Enums
Les énumérations sont probablement l'une des fonctionnalités de langage les plus sous-estimées de Swift. Elles sont bien plus complexes qu'il n'y paraît. Un cas d'utilisation courant des énumérations consiste à modéliser les états discrets d'un élément. Par exemple, nous pouvons écrire une application pour gérer des articles. Pour suivre l'état d'un article, nous pouvons utiliser une énumération Status :
enum Status: String, Codable {
case draft
case inReview
case approved
case published
}
Cloud Firestore ne prend pas en charge les énumérations de manière native (c'est-à-dire qu'il ne peut pas appliquer l'ensemble de valeurs), mais nous pouvons toujours tirer parti du fait que les énumérations peuvent être typées et choisir un type codable. Dans cet exemple, nous avons choisi String, ce qui signifie que toutes les valeurs enum seront mappées vers/depuis une chaîne lorsqu'elles seront stockées dans un document Cloud Firestore.
De plus, comme Swift prend en charge les valeurs brutes personnalisées, nous pouvons même personnaliser les valeurs qui font référence à chaque cas d'énumération. Par exemple, si nous décidons de stocker l'état de la demande Status.inReview comme "en cours d'examen", nous pouvons simplement mettre à jour l'énumération ci-dessus comme suit :
enum Status: String, Codable {
case draft
case inReview = "in review"
case approved
case published
}
Personnaliser le mappage
Parfois, les noms d'attribut des documents Cloud Firestore que nous voulons mapper ne correspondent pas aux noms des propriétés de notre modèle de données dans Swift. Par exemple, l'un de nos collaborateurs peut être un développeur Python et avoir décidé de choisir snake_case pour tous ses noms d'attributs.
Pas de panique, Codable est là pour nous aider !
Dans de tels cas, nous pouvons utiliser CodingKeys. Il s'agit d'une énumération que nous pouvons ajouter à une structure codable pour spécifier la façon dont certains attributs seront mappés.
Prenons l'exemple de ce document :

Pour mapper ce document à une structure qui possède une propriété de nom de type String, nous devons ajouter un énumérateur CodingKeys à la structure ProgrammingLanguage et spécifier le nom de l'attribut dans le document :
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
Par défaut, l'API Codable utilise les noms de propriétés de nos types Swift pour déterminer les noms d'attributs dans les documents Cloud Firestore que nous essayons de mapper. Tant que les noms d'attributs correspondent, il n'est pas nécessaire d'ajouter CodingKeys à nos types codables. Toutefois, une fois que nous utilisons CodingKeys pour un type spécifique, nous devons ajouter tous les noms de propriétés que nous souhaitons mapper.
Dans l'extrait de code ci-dessus, nous avons défini une propriété id que nous pourrions utiliser comme identifiant dans une vue List SwiftUI. Si nous ne l'avions pas spécifié dans CodingKeys, il n'aurait pas été mappé lors de la récupération des données et serait donc devenu nil.
La vue List sera alors remplie avec le premier document.
Toute propriété qui n'est pas listée comme cas dans l'énumération CodingKeys correspondante sera ignorée lors du processus de mappage. Cela peut être pratique si nous souhaitons exclure spécifiquement certaines propriétés du mappage.
Par exemple, si nous voulons exclure la propriété reasonWhyILoveThis du mappage, il nous suffit de la supprimer de l'énumération CodingKeys :
struct ProgrammingLanguage: Identifiable, Codable {
@DocumentID var id: String?
var name: String
var year: Date
var reasonWhyILoveThis: String = ""
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
Il peut arriver que nous souhaitions réécrire un attribut vide dans le document Cloud Firestore. Swift utilise le concept d'optionnels pour indiquer l'absence de valeur, et Cloud Firestore accepte également les valeurs null.
Toutefois, le comportement par défaut pour l'encodage des optionnels ayant une valeur nil consiste simplement à les omettre. @ExplicitNull nous permet de contrôler la façon dont les optionnels Swift sont gérés lors de leur encodage : en signalant une propriété optionnelle comme @ExplicitNull, nous pouvons indiquer à Cloud Firestore d'écrire cette propriété dans le document avec une valeur nulle si elle contient une valeur de nil.
Utiliser un encodeur et un décodeur personnalisés pour mapper les couleurs
Pour terminer notre couverture du mappage de données avec Codable, présentons les encodeurs et décodeurs personnalisés. Cette section ne couvre pas un type de données Cloud Firestore natif, mais les encodeurs et décodeurs personnalisés sont très utiles dans vos applications Cloud Firestore.
"Comment mapper des couleurs" est l'une des questions les plus fréquemment posées par les développeurs, non seulement pour Cloud Firestore, mais aussi pour le mappage entre Swift et JSON. Il existe de nombreuses solutions, mais la plupart se concentrent sur JSON, et presque toutes mappent les couleurs sous forme de dictionnaire imbriqué composé de ses composants RVB.
Il semble qu'il devrait exister une solution plus simple et plus efficace. Pourquoi n'utilisons-nous pas les couleurs Web (ou, plus précisément, la notation hexadécimale CSS) ? Elles sont faciles à utiliser (essentiellement une chaîne) et prennent même en charge la transparence.
Pour pouvoir mapper un Color Swift à sa valeur hexadécimale, nous devons créer une extension Swift qui ajoute Codable à Color.
extension Color {
init(hex: String) {
let rgba = hex.toRGBA()
self.init(.sRGB,
red: Double(rgba.r),
green: Double(rgba.g),
blue: Double(rgba.b),
opacity: Double(rgba.alpha))
}
//... (code for translating between hex and RGBA omitted for brevity)
}
extension Color: Codable {
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let hex = try container.decode(String.self)
self.init(hex: hex)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(toHex)
}
}
En utilisant decoder.singleValueContainer(), nous pouvons décoder un String en son équivalent Color, sans avoir à imbriquer les composants RGBA. De plus, vous pouvez utiliser ces valeurs dans l'interface utilisateur Web de votre application, sans avoir à les convertir au préalable.
Cela nous permet de mettre à jour le code pour mapper les tags, ce qui facilite la gestion directe des couleurs des tags au lieu de devoir les mapper manuellement dans le code de l'UI de notre application :
struct Tag: Codable, Hashable {
var title: String
var color: Color
}
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Traiter les erreurs
Dans les extraits de code ci-dessus, nous avons intentionnellement réduit la gestion des erreurs au minimum. Toutefois, dans une application de production, vous devez vous assurer de gérer correctement toutes les erreurs.
Voici un extrait de code qui montre comment gérer les situations d'erreur que vous pourriez rencontrer :
class MappingSimpleTypesViewModel: ObservableObject {
@Published var book: Book = .empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
func fetchAndMap() {
fetchBook(documentId: "hitchhiker")
}
func fetchAndMapNonExisting() {
fetchBook(documentId: "does-not-exist")
}
func fetchAndTryMappingInvalidData() {
fetchBook(documentId: "invalid-data")
}
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self.errorMessage = "\(error.localizedDescription): \(key)"
default:
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
}
}
Gérer les erreurs dans les mises à jour en temps réel
L'extrait de code précédent montre comment gérer les erreurs lors de la récupération d'un seul document. En plus de récupérer les données une seule fois, Cloud Firestore permet également de fournir des mises à jour à votre application au fur et à mesure qu'elles se produisent, à l'aide de ce que l'on appelle des écouteurs d'instantanés : nous pouvons enregistrer un écouteur d'instantanés sur une collection (ou une requête), et Cloud Firestore appellera notre écouteur chaque fois qu'une mise à jour sera disponible.
Voici un extrait de code qui montre comment enregistrer un écouteur d'instantané, mapper des données à l'aide de Codable et gérer les erreurs qui peuvent survenir. Il montre également comment ajouter un document à la collection. Comme vous le verrez, il n'est pas nécessaire de mettre à jour nous-mêmes le tableau local contenant les documents mappés, car le code du listener d'instantané s'en charge.
class MappingColorsViewModel: ObservableObject {
@Published var colorEntries = [ColorEntry]()
@Published var newColor = ColorEntry.empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
private var listenerRegistration: ListenerRegistration?
public func unsubscribe() {
if listenerRegistration != nil {
listenerRegistration?.remove()
listenerRegistration = nil
}
}
func subscribe() {
if listenerRegistration == nil {
listenerRegistration = db.collection("colors")
.addSnapshotListener { [weak self] (querySnapshot, error) in
guard let documents = querySnapshot?.documents else {
self?.errorMessage = "No documents in 'colors' collection"
return
}
self?.colorEntries = documents.compactMap { queryDocumentSnapshot in
let result = Result { try queryDocumentSnapshot.data(as: ColorEntry.self) }
switch result {
case .success(let colorEntry):
if let colorEntry = colorEntry {
// A ColorEntry value was successfully initialized from the DocumentSnapshot.
self?.errorMessage = nil
return colorEntry
}
else {
// A nil value was successfully initialized from the DocumentSnapshot,
// or the DocumentSnapshot was nil.
self?.errorMessage = "Document doesn't exist."
return nil
}
case .failure(let error):
// A ColorEntry value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self?.errorMessage = "\(error.localizedDescription): \(key)"
default:
self?.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
return nil
}
}
}
}
}
func addColorEntry() {
let collectionRef = db.collection("colors")
do {
let newDocReference = try collectionRef.addDocument(from: newColor)
print("ColorEntry stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
}
Tous les extraits de code utilisés dans cet article font partie d'un exemple d'application que vous pouvez télécharger à partir de ce dépôt GitHub.
C'est parti pour Codable !
L'API Codable de Swift offre un moyen puissant et flexible de mapper les données à partir de formats sérialisés vers le modèle de données de vos applications et inversement. Dans ce guide, vous avez vu à quel point il est facile à utiliser dans les applications qui utilisent Cloud Firestore comme data store.
En partant d'un exemple de base avec des types de données simples, nous avons progressivement augmenté la complexité du modèle de données, tout en pouvant nous appuyer sur l'implémentation de Codable et de Firebase pour effectuer le mappage à notre place.
Pour en savoir plus sur Codable, je vous recommande les ressources suivantes :
- John Sundell a écrit un excellent article sur les bases de Codable.
- Si vous préférez les livres, consultez le Guide Flight School sur Swift Codable de Mattt.
- Enfin, Donny Wals a consacré une série entière à Codable.
Bien que nous ayons fait de notre mieux pour compiler un guide complet sur le mappage des documents Cloud Firestore, il n'est pas exhaustif et vous pouvez utiliser d'autres stratégies pour mapper vos types. Utilisez le bouton Envoyer des commentaires ci-dessous pour nous indiquer les stratégies que vous utilisez pour mapper d'autres types de données Cloud Firestore ou pour représenter des données dans Swift.
Il n'y a vraiment aucune raison de ne pas utiliser la compatibilité Codable de Cloud Firestore.