
Die in Swift 4 eingeführte Codable API von Swift ermöglicht es uns, die Leistungsfähigkeit des Compilers zu nutzen, um die Zuordnung von Daten aus serialisierten Formaten zu Swift-Typen zu vereinfachen.
Sie haben Codable vielleicht verwendet, um Daten von einer Web API zum Datenmodell Ihrer App zuzuordnen (und umgekehrt), aber es ist viel flexibler.
In dieser Anleitung sehen wir uns an, wie Codable verwendet werden kann, um Daten aus Cloud Firestore zu Swift-Typen zuzuordnen und umgekehrt.
Wenn Sie ein Dokument aus Cloud Firestore abrufen, erhält Ihre App ein Dictionary mit Schlüssel/Wert-Paaren (oder ein Array von Dictionaries, wenn Sie einen der Vorgänge verwenden, der mehrere Dokumente zurückgibt).
Sie können Dictionaries natürlich weiterhin direkt in Swift verwenden. Sie bieten eine große Flexibilität, die genau das sein könnte, was Ihr Anwendungsfall erfordert. Dieser Ansatz ist jedoch nicht typsicher und es ist einfach, schwer zu findende Fehler einzuführen, indem Sie Attributnamen falsch schreiben oder vergessen, das neue Attribut zuzuordnen, das Ihr Team hinzugefügt hat, als es letzte Woche diese aufregende neue Funktion veröffentlicht hat.
In der Vergangenheit haben viele Entwickler diese Mängel umgangen, indem sie eine einfache Zuordnungsebene implementiert haben, mit der sie Dictionaries zu Swift-Typen zuordnen konnten. Die meisten dieser Implementierungen basieren jedoch darauf, dass die Zuordnung zwischen Cloud Firestore Dokumenten und den entsprechenden Typen des Datenmodells Ihrer App manuell angegeben wird.
Mit der Unterstützung von Cloud Firestore's für die Codable API von Swift wird dies viel einfacher:
- Sie müssen keinen Zuordnungscode mehr manuell implementieren.
- Es ist einfach zu definieren, wie Attribute mit unterschiedlichen Namen zugeordnet werden.
- Es bietet integrierte Unterstützung für viele Swift-Typen.
- Und es ist einfach, Unterstützung für die Zuordnung benutzerdefinierter Typen hinzuzufügen.
- Das Beste: Bei einfachen Datenmodellen müssen Sie überhaupt keinen Zuordnungscode schreiben.
Daten zuordnen
Cloud Firestore speichert Daten in Dokumenten, die Schlüssel Werten zuordnen. Um
Daten aus einem einzelnen Dokument abzurufen, können wir DocumentSnapshot.data() aufrufen, das
ein Dictionary zurückgibt, das die Feldnamen einem Any zuordnet:
func data() -> [String : Any]?.
Das bedeutet, dass wir die Indexsyntax von Swift verwenden können, um auf jedes einzelne Feld zuzugreifen.
import FirebaseFirestore
#warning("DO NOT MAP YOUR DOCUMENTS MANUALLY. USE CODABLE INSTEAD.")
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
let id = document.documentID
let data = document.data()
let title = data?["title"] as? String ?? ""
let numberOfPages = data?["numberOfPages"] as? Int ?? 0
let author = data?["author"] as? String ?? ""
self.book = Book(id:id, title: title, numberOfPages: numberOfPages, author: author)
}
}
}
}
Dieser Code mag einfach und leicht zu implementieren erscheinen, ist aber fehleranfällig, schwer zu pflegen und fehleranfällig.
Wie Sie sehen, treffen wir Annahmen über die Datentypen der Dokumentfelder. Diese können richtig oder falsch sein.
Da es kein Schema gibt, können Sie ganz einfach ein neues Dokument zur Sammlung hinzufügen und einen anderen Typ für ein Feld auswählen. Möglicherweise wählen Sie versehentlich „String“ für das Feld numberOfPages, was zu einem schwer zu findenden Zuordnungsproblem führen kann. Außerdem müssen Sie Ihren Zuordnungscode aktualisieren, wenn ein neues Feld hinzugefügt wird, was ziemlich umständlich ist.
Und vergessen wir nicht, dass wir das starke Typsystem von Swift nicht nutzen, das genau den richtigen Typ für jede der Eigenschaften von Book kennt.
Was ist Codable?
Laut der Dokumentation von Apple ist Codable „ein Typ, der sich in eine externe Darstellung umwandeln und daraus wiederherstellen kann“. Tatsächlich ist Codable ein Typalias für die Protokolle Encodable und Decodable. Wenn Sie einen Swift-Typ an dieses Protokoll anpassen, synthetisiert der Compiler den Code, der zum Codieren/Decodieren einer Instanz dieses Typs aus einem serialisierten Format wie JSON erforderlich ist.
Ein einfacher Typ zum Speichern von Daten zu einem Buch könnte so aussehen:
struct Book: Codable {
var title: String
var numberOfPages: Int
var author: String
}
Wie Sie sehen, ist die Anpassung des Typs an Codable minimal invasiv. Wir mussten nur die Anpassung an das Protokoll hinzufügen. Es waren keine weiteren Änderungen erforderlich.
Damit können wir jetzt ganz einfach ein Buch in ein JSON-Objekt codieren:
do {
let book = Book(title: "The Hitchhiker's Guide to the Galaxy",
numberOfPages: 816,
author: "Douglas Adams")
let encoder = JSONEncoder()
let data = try encoder.encode(book)
}
catch {
print("Error when trying to encode book: \(error)")
}
Das Decodieren eines JSON-Objekts in eine Book-Instanz funktioniert so:
let decoder = JSONDecoder()
let data = /* fetch data from the network */
let decodedBook = try decoder.decode(Book.self, from: data)
Zuordnung zu und von einfachen Typen in Cloud Firestore Dokumenten mit Codable
Cloud Firestore unterstützt eine breite Palette von Datentypen, von einfachen Strings bis hin zu verschachtelten Maps. Die meisten davon entsprechen direkt den integrierten Typen von Swift. Sehen wir uns zuerst die Zuordnung einiger einfacher Datentypen an, bevor wir uns mit den komplexeren beschäftigen.
So ordnen Sie Cloud Firestore Dokumente Swift-Typen zu:
- Achten Sie darauf, dass Sie das Framework
FirebaseFirestorezu Ihrem Projekt hinzugefügt haben. Sie können dazu entweder Swift Package Manager oder CocoaPods verwenden. - Importieren Sie
FirebaseFirestorein Ihre Swift-Datei. - Passen Sie Ihren Typ an
Codablean. - Optional: Wenn Sie den Typ in einer
List-Ansicht verwenden möchten, fügen Sie Ihrem Typ eineid-Eigenschaft hinzu und verwenden Sie@DocumentID, um Cloud Firestore mitzuteilen, dass diese der Dokument-ID zugeordnet werden soll. Wir werden dies weiter unten genauer erläutern. - Verwenden Sie
documentReference.data(as: ), um eine Dokumentreferenz einem Swift-Typ zuzuordnen. - Verwenden Sie
documentReference.setData(from: ), um Daten aus Swift-Typen einem Cloud Firestore Dokument zuzuordnen. - Optional, aber sehr empfehlenswert: Implementieren Sie eine ordnungsgemäße Fehlerbehandlung.
Aktualisieren wir unseren Book-Typ entsprechend:
struct Book: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
}
Da dieser Typ bereits codierbar war, mussten wir nur die id-Eigenschaft hinzufügen und sie mit dem Property-Wrapper @DocumentID annotieren.
Wenn wir das vorherige Code-Snippet zum Abrufen und Zuordnen eines Dokuments verwenden, können wir den gesamten manuellen Zuordnungscode durch eine einzige Zeile ersetzen:
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
do {
self.book = try document.data(as: Book.self)
}
catch {
print(error)
}
}
}
}
}
Sie können dies noch prägnanter formulieren, indem Sie den Typ des Dokuments angeben, wenn Sie getDocument(as:) aufrufen. Dadurch wird die Zuordnung für Sie ausgeführt und ein Result-Typ zurückgegeben, der das zugeordnete Dokument oder einen Fehler enthält, falls die Decodierung fehlgeschlagen ist:
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
Das Aktualisieren eines vorhandenen Dokuments ist so einfach wie das Aufrufen von documentReference.setData(from: ). Hier ist der Code zum Speichern einer Book-Instanz mit einer grundlegenden Fehlerbehandlung:
func updateBook(book: Book) {
if let id = book.id {
let docRef = db.collection("books").document(id)
do {
try docRef.setData(from: book)
}
catch {
print(error)
}
}
}
Wenn Sie ein neues Dokument hinzufügen, Cloud Firestore weist dem Dokument automatisch eine neue Dokument-ID zu. Das funktioniert auch, wenn die App gerade offline ist.
func addBook(book: Book) {
let collectionRef = db.collection("books")
do {
let newDocReference = try collectionRef.addDocument(from: self.book)
print("Book stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
Neben der Zuordnung einfacher Datentypen unterstützt Cloud Firestore eine Reihe weiterer Datentypen, darunter strukturierte Typen, mit denen Sie verschachtelte Objekte in einem Dokument erstellen können.
Verschachtelte benutzerdefinierte Typen
Die meisten Attribute, die wir in unseren Dokumenten zuordnen möchten, sind einfache Werte wie der Titel des Buchs oder der Name des Autors. Was aber, wenn wir ein komplexeres Objekt speichern müssen? Wir möchten beispielsweise die URLs zum Cover des Buchs in verschiedenen Auflösungen speichern.
Die einfachste Möglichkeit, dies in Cloud Firestore zu tun, ist die Verwendung einer Map:

Wenn wir die entsprechende Swift-Struktur schreiben, können wir die Tatsache nutzen, dass Cloud Firestore URLs unterstützt. Wenn wir ein Feld speichern, das eine URL enthält, wird es in einen String konvertiert und umgekehrt:
struct CoverImages: Codable {
var small: URL
var medium: URL
var large: URL
}
struct BookWithCoverImages: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var cover: CoverImages?
}
Beachten Sie, dass wir eine Struktur CoverImages für die Cover-Map im
Cloud Firestore Dokument definiert haben. Indem wir die Cover-Eigenschaft für BookWithCoverImages als optional kennzeichnen, können wir die Tatsache berücksichtigen, dass einige Dokumente möglicherweise kein Cover-Attribut enthalten.
Wenn Sie sich fragen, warum es kein Code-Snippet zum Abrufen oder Aktualisieren von Daten gibt, werden Sie sich freuen zu hören, dass der Code zum Lesen oder Schreiben von/in Cloud Firestore nicht angepasst werden muss. Das alles funktioniert mit dem Code, den wir im ersten Abschnitt geschrieben haben.
Arrays
Manchmal möchten wir eine Sammlung von Werten in einem Dokument speichern. Die Genres eines Buchs sind ein gutes Beispiel: Ein Buch wie Per Anhalter durch die Galaxis kann in mehrere Kategorien fallen, in diesem Fall „Sci-Fi“ und „Comedy“:

In Cloud Firestore, können wir dies mit einem Array von Werten modellieren. Dies wird für jeden codierbaren Typ unterstützt (z. B. String, Int usw.). Im Folgenden wird gezeigt, wie Sie unserem Book-Modell ein Array von Genres hinzufügen:
public struct BookWithGenre: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var genres: [String]
}
Da dies für jeden codierbaren Typ funktioniert, können wir auch benutzerdefinierte Typen verwenden. Angenommen, wir möchten eine Liste von Tags für jedes Buch speichern. Neben dem Namen des Tags möchten wir auch die Farbe des Tags speichern, wie hier:
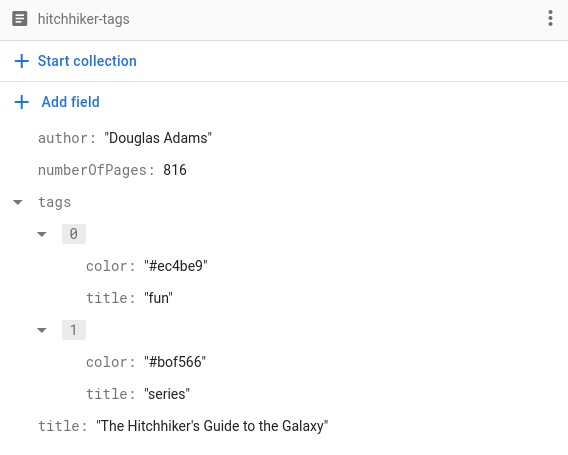
Um Tags auf diese Weise zu speichern, müssen wir nur eine Tag-Struktur implementieren, um ein Tag darzustellen und es codierbar zu machen:
struct Tag: Codable, Hashable {
var title: String
var color: String
}
Und schon können wir ein Array von Tags in unseren Book-Dokumenten speichern.
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Ein kurzer Hinweis zur Zuordnung von Dokument-IDs
Bevor wir mit der Zuordnung weiterer Typen fortfahren, sprechen wir kurz über die Zuordnung von Dokument-IDs.
In einigen der vorherigen Beispiele haben wir den @DocumentID Property-Wrapper verwendet,
um die Dokument-ID unserer Cloud Firestore Dokumente der id Eigenschaft
unserer Swift-Typen zuzuordnen. Das ist aus mehreren Gründen wichtig:
- So wissen wir, welches Dokument aktualisiert werden muss, wenn der Nutzer lokale Änderungen vornimmt.
- Für
Listvon SwiftUI müssen die ElementeIdentifiablesein, damit sie beim Einfügen nicht hin und her springen.
Es ist wichtig zu beachten, dass ein als @DocumentID gekennzeichnetes Attribut von
Encoder von Cloud Firestore's nicht codiert wird, wenn das Dokument zurückgeschrieben wird. Das liegt daran, dass die Dokument-ID kein Attribut des Dokuments selbst ist. Sie in das Dokument zu schreiben wäre also ein Fehler.
Wenn Sie mit verschachtelten Typen arbeiten (z. B. dem Array von Tags für das Book in einem
früheren Beispiel in dieser Anleitung), ist es nicht erforderlich, eine @DocumentID
Eigenschaft hinzuzufügen. Verschachtelte Eigenschaften sind Teil des Cloud Firestore Dokuments und
stellen kein separates Dokument dar. Daher benötigen sie keine Dokument-ID.
Datums- und Uhrzeitwerte
Cloud Firestore hat einen integrierten Datentyp für die Verarbeitung von Datums- und Uhrzeitwerten. Dank der Unterstützung von Cloud Firestore für Codable ist die Verwendung ganz einfach.
Sehen wir uns dieses Dokument an, das die Mutter aller Programmiersprachen darstellt: Ada, erfunden 1843:

Ein Swift-Typ zum Zuordnen dieses Dokuments könnte so aussehen:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
}
Wir können diesen Abschnitt über Datums- und Uhrzeitwerte nicht beenden, ohne über @ServerTimestamp zu sprechen. Dieser Property-Wrapper ist ein Kraftpaket, wenn es um den Umgang mit Zeitstempeln in Ihrer App geht.
In jedem verteilten System ist es wahrscheinlich, dass die Uhren auf den einzelnen Systemen nicht immer vollständig synchronisiert sind. Sie denken vielleicht, dass das kein großes Problem ist, aber stellen Sie sich die Auswirkungen einer Uhr vor, die für ein Aktienhandelssystem leicht aus dem Takt gerät: Selbst eine Abweichung von einer Millisekunde kann bei der Ausführung eines Handels zu einem Unterschied von Millionen von Dollar führen.
Cloud Firestore verarbeitet Attribute, die mit @ServerTimestamp gekennzeichnet sind, so: Wenn das Attribut nil ist, wenn Sie es speichern (z. B. mit addDocument()), füllt Cloud Firestore das Feld mit dem aktuellen Serverzeitstempel zum Zeitpunkt des Schreibens in die Datenbank. Wenn das Feld nicht nil
ist, wenn Sie addDocument() oder updateData() aufrufen, lässt Cloud Firestore den Attributwert unverändert. So lassen sich ganz einfach Felder wie createdAt und lastUpdatedAt implementieren.
Geopunkte
Standortdaten sind in unseren Apps allgegenwärtig. Durch das Speichern dieser Daten werden viele interessante Funktionen möglich. Es kann beispielsweise nützlich sein, einen Standort für eine Aufgabe zu speichern, damit Ihre App Sie an eine Aufgabe erinnern kann, wenn Sie ein Ziel erreichen.
Cloud Firestore hat einen integrierten Datentyp, GeoPoint, der den
Längen- und Breitengrad eines beliebigen Standorts speichern kann. Um Standorte aus/in ein
Cloud Firestore Dokument zuzuordnen, können wir den GeoPoint Typ verwenden:
struct Office: Codable {
@DocumentID var id: String?
var name: String
var location: GeoPoint
}
Der entsprechende Typ in Swift ist CLLocationCoordinate2D. Mit dem folgenden Vorgang können wir zwischen diesen beiden Typen zuordnen:
CLLocationCoordinate2D(latitude: office.location.latitude,
longitude: office.location.longitude)
Weitere Informationen zum Abfragen von Dokumenten nach physischem Standort finden Sie in dieser Lösungsanleitung.
Enums
Enums sind wahrscheinlich eine der am meisten unterschätzten Sprachfunktionen in Swift. Sie haben viel mehr zu bieten, als man auf den ersten Blick sieht. Ein häufiger Anwendungsfall für Enums ist die Modellierung der diskreten Zustände von etwas. Angenommen, wir schreiben eine App zum Verwalten von Artikeln. Um den Status eines Artikels zu verfolgen, können wir ein Enum Status verwenden:
enum Status: String, Codable {
case draft
case inReview
case approved
case published
}
Cloud Firestore unterstützt Enums nicht nativ (d.h., es kann die
Menge der Werte nicht erzwingen), aber wir können trotzdem die Tatsache nutzen, dass Enums typisiert werden können,
und einen codierbaren Typ auswählen. In diesem Beispiel haben wir String ausgewählt. Das bedeutet,
dass alle Enum-Werte beim Speichern in einem
Cloud Firestore Dokument in Strings konvertiert werden und umgekehrt.
Da Swift benutzerdefinierte Rohwerte unterstützt, können wir sogar anpassen, welche Werte sich auf welchen Enum-Fall beziehen. Wenn wir beispielsweise den Fall Status.inReview als „in review“ speichern möchten, können wir das obige Enum so aktualisieren:
enum Status: String, Codable {
case draft
case inReview = "in review"
case approved
case published
}
Zuordnung anpassen
Manchmal stimmen die Attributnamen der Cloud Firestore Dokumente, die wir zu ordnen möchten, nicht mit den Namen der Eigenschaften in unserem Datenmodell in Swift überein. Einer unserer Kollegen ist beispielsweise ein Python-Entwickler und hat sich für alle Attributnamen für snake_case entschieden.
Keine Sorge, Codable hat die Lösung.
In solchen Fällen können wir CodingKeys verwenden. Das ist ein Enum, das wir einer codierbaren Struktur hinzufügen können, um anzugeben, wie bestimmte Attribute zugeordnet werden.
Sehen wir uns dieses Dokument an:

Um dieses Dokument einer Struktur zuzuordnen, die eine Name-Eigenschaft vom Typ String hat, müssen wir der Struktur ProgrammingLanguage ein CodingKeys-Enum hinzufügen und den Namen des Attributs im Dokument angeben:
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
Standardmäßig verwendet die Codable API die Eigenschaftsnamen unserer Swift-Typen, um
die Attributnamen in den Cloud Firestore Dokumenten zu bestimmen, die wir zuordnen
möchten. Solange die Attributnamen übereinstimmen, ist es nicht erforderlich, unseren codierbaren Typen CodingKeys hinzuzufügen. Wenn wir jedoch CodingKeys für einen bestimmten Typ verwenden, müssen wir alle Eigenschaftsnamen hinzufügen, die wir zuordnen möchten.
Im obigen Code-Snippet haben wir eine id-Eigenschaft definiert, die wir möglicherweise als Kennung in einer List-Ansicht von SwiftUI verwenden möchten. Wenn wir sie nicht in CodingKeys angeben, wird sie beim Abrufen von Daten nicht zugeordnet und somit nil.
Dadurch wird die List-Ansicht mit dem ersten Dokument gefüllt.
Alle Eigenschaften, die nicht als Fall im entsprechenden CodingKeys-Enum aufgeführt sind, werden während der Zuordnung ignoriert. Das kann praktisch sein, wenn wir bestimmte Eigenschaften von der Zuordnung ausschließen möchten.
Wenn wir beispielsweise die Zuordnung der Eigenschaft reasonWhyILoveThis ausschließen möchten, müssen wir sie nur aus dem CodingKeys-Enum entfernen:
struct ProgrammingLanguage: Identifiable, Codable {
@DocumentID var id: String?
var name: String
var year: Date
var reasonWhyILoveThis: String = ""
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
Manchmal möchten wir ein leeres Attribut zurück in das
Cloud Firestore Dokument schreiben. Swift kennt optionale Werte, um das
Fehlen eines Werts anzugeben, und Cloud Firestore unterstützt null Werte.
Das Standardverhalten für das Codieren optionaler Werte mit einem nil-Wert besteht jedoch darin, sie einfach wegzulassen. @ExplicitNull gibt uns etwas Kontrolle darüber, wie optionals von Swift
beim Codieren behandelt werden: Wenn wir eine optionale Eigenschaft als
@ExplicitNull kennzeichnen, können wir Cloud Firestore anweisen, diese Eigenschaft mit einem Nullwert in das
Dokument zu schreiben, wenn sie einen Wert von nil enthält.
Benutzerdefinierten Encoder und Decoder für die Zuordnung von Farben verwenden
Als letztes Thema in unserer Behandlung der Zuordnung von Daten mit Codable stellen wir benutzerdefinierte Encoder und Decoder vor. In diesem Abschnitt wird kein nativer Cloud Firestore Datentyp behandelt, aber benutzerdefinierte Encoder und Decoder sind in Ihren Cloud Firestore Apps sehr nützlich.
„Wie kann ich Farben zuordnen?“ ist eine der am häufigsten gestellten Fragen von Entwicklern, nicht nur für Cloud Firestore, sondern auch für die Zuordnung zwischen Swift und JSON sowie. Es gibt viele Lösungen, aber die meisten konzentrieren sich auf JSON und fast alle ordnen Farben als verschachteltes Dictionary zu, das aus den RGB-Komponenten besteht.
Es sollte eine bessere, einfachere Lösung geben. Warum verwenden wir nicht Webfarben (oder genauer gesagt die CSS-Hex-Farbnotation)? Sie sind einfach zu verwenden (im Grunde nur ein String) und unterstützen sogar Transparenz.
Um eine Swift-Color ihrem Hex-Wert zuzuordnen, müssen wir eine Swift-Erweiterung erstellen, die Color Codable hinzufügt.
extension Color {
init(hex: String) {
let rgba = hex.toRGBA()
self.init(.sRGB,
red: Double(rgba.r),
green: Double(rgba.g),
blue: Double(rgba.b),
opacity: Double(rgba.alpha))
}
//... (code for translating between hex and RGBA omitted for brevity)
}
extension Color: Codable {
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let hex = try container.decode(String.self)
self.init(hex: hex)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(toHex)
}
}
Mit decoder.singleValueContainer() können wir einen String in das entsprechende Color decodieren, ohne die RGBA-Komponenten verschachteln zu müssen. Außerdem können Sie diese Werte in der Web-UI Ihrer App verwenden, ohne sie zuerst konvertieren zu müssen.
Damit können wir den Code für die Zuordnung von Tags aktualisieren, sodass die Tag-Farben direkt verarbeitet werden können, anstatt sie manuell im UI-Code unserer App zuordnen zu müssen:
struct Tag: Codable, Hashable {
var title: String
var color: Color
}
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
Fehlerbehebung
In den obigen Code-Snippets haben wir die Fehlerbehandlung absichtlich auf ein Minimum beschränkt. In einer Produktions-App sollten Sie jedoch alle Fehler ordnungsgemäß behandeln.
Hier ist ein Code-Snippet, das zeigt, wie Sie alle Fehlerfälle behandeln können, auf die Sie stoßen könnten:
class MappingSimpleTypesViewModel: ObservableObject {
@Published var book: Book = .empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
func fetchAndMap() {
fetchBook(documentId: "hitchhiker")
}
func fetchAndMapNonExisting() {
fetchBook(documentId: "does-not-exist")
}
func fetchAndTryMappingInvalidData() {
fetchBook(documentId: "invalid-data")
}
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self.errorMessage = "\(error.localizedDescription): \(key)"
default:
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
}
}
Fehler bei Live-Updates behandeln
Das vorherige Code-Snippet zeigt, wie Fehler beim Abrufen eines einzelnen Dokuments behandelt werden. kann Daten nicht nur einmal abrufen, sondern auch Updates an Ihre App senden, sobald sie auftreten. Dazu werden sogenannte Snapshot-Listener verwendet: Wir können einen Snapshot-Listener für eine Sammlung (oder Abfrage) registrieren und Cloud Firestore ruft unseren Listener auf, wenn es ein Update gibt.Cloud Firestore
Hier ist ein Code-Snippet, das zeigt, wie Sie einen Snapshot-Listener registrieren, Daten mit Codable zuordnen und alle Fehler behandeln, die auftreten können. Außerdem wird gezeigt, wie Sie der Sammlung ein neues Dokument hinzufügen. Wie Sie sehen, müssen wir das lokale Array mit den zugeordneten Dokumenten nicht selbst aktualisieren, da dies vom Code im Snapshot-Listener übernommen wird.
class MappingColorsViewModel: ObservableObject {
@Published var colorEntries = [ColorEntry]()
@Published var newColor = ColorEntry.empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
private var listenerRegistration: ListenerRegistration?
public func unsubscribe() {
if listenerRegistration != nil {
listenerRegistration?.remove()
listenerRegistration = nil
}
}
func subscribe() {
if listenerRegistration == nil {
listenerRegistration = db.collection("colors")
.addSnapshotListener { [weak self] (querySnapshot, error) in
guard let documents = querySnapshot?.documents else {
self?.errorMessage = "No documents in 'colors' collection"
return
}
self?.colorEntries = documents.compactMap { queryDocumentSnapshot in
let result = Result { try queryDocumentSnapshot.data(as: ColorEntry.self) }
switch result {
case .success(let colorEntry):
if let colorEntry = colorEntry {
// A ColorEntry value was successfully initialized from the DocumentSnapshot.
self?.errorMessage = nil
return colorEntry
}
else {
// A nil value was successfully initialized from the DocumentSnapshot,
// or the DocumentSnapshot was nil.
self?.errorMessage = "Document doesn't exist."
return nil
}
case .failure(let error):
// A ColorEntry value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self?.errorMessage = "\(error.localizedDescription): \(key)"
default:
self?.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
return nil
}
}
}
}
}
func addColorEntry() {
let collectionRef = db.collection("colors")
do {
let newDocReference = try collectionRef.addDocument(from: newColor)
print("ColorEntry stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
}
Alle in diesem Beitrag verwendeten Code-Snippets sind Teil einer Beispielanwendung, die Sie aus diesem GitHub-Repository herunterladen können.
Verwenden Sie Codable!
Die Codable API von Swift bietet eine leistungsstarke und flexible Möglichkeit, Daten aus serialisierten Formaten in und aus dem Datenmodell Ihrer Anwendungen zuzuordnen. In dieser Anleitung haben Sie gesehen, wie einfach die Verwendung in Apps ist, die Cloud Firestore als Datenspeicher verwenden.
Ausgehend von einem einfachen Beispiel mit einfachen Datentypen haben wir die Komplexität des Datenmodells schrittweise erhöht, wobei wir uns immer auf Codable und die Implementierung von Firebase verlassen konnten, um die Zuordnung für uns durchzuführen.
Weitere Informationen zu Codable finden Sie in den folgenden Ressourcen:
- John Sundell hat einen guten Artikel zu den Grundlagen von Codable.
- Wenn Sie Bücher bevorzugen, sehen Sie sich den Flight School Guide to Swift Codable von Mattt an .
- Und schließlich hat Donny Wals eine ganze Reihe von Artikeln zu Codable.
Wir haben uns zwar bemüht, eine umfassende Anleitung für die Zuordnung von Cloud Firestore Dokumenten zu erstellen, aber sie ist nicht vollständig. Möglicherweise verwenden Sie andere Strategien, um Ihre Typen zuzuordnen. Über die Schaltfläche Feedback senden unten können Sie uns mitteilen, welche Strategien Sie für die Zuordnung anderer Arten von Cloud Firestore Daten oder für die Darstellung von Daten in Swift verwenden.
Es gibt wirklich keinen Grund, die Codable-Unterstützung von Cloud Firestore's nicht zu nutzen.