
Codable API ของ Swift ซึ่งเปิดตัวใน Swift 4 ช่วยให้เราใช้ประโยชน์จากความสามารถของคอมไพเลอร์เพื่อทำให้การแมปข้อมูลจากรูปแบบที่ซีเรียลไลซ์ไปยังประเภท Swift เป็นเรื่องง่ายขึ้น
คุณอาจเคยใช้ Codable เพื่อแมปข้อมูลจากเว็บ API ไปยังโมเดลข้อมูลของแอป (และในทางกลับกัน) แต่ Codable มีความยืดหยุ่นมากกว่านั้นมาก
ในคู่มือนี้ เราจะดูวิธีใช้ Codable เพื่อแมปข้อมูลจาก Cloud Firestore ไปยังประเภท Swift และในทางกลับกัน
เมื่อดึงข้อมูลเอกสารจาก Cloud Firestore แอปของคุณจะได้รับ พจนานุกรมของคู่คีย์/ค่า (หรืออาร์เรย์ของพจนานุกรม หากคุณใช้การดำเนินการอย่างใดอย่างหนึ่งที่แสดงผลเอกสารหลายรายการ)
แน่นอนว่าคุณสามารถใช้พจนานุกรมใน Swift ต่อไปได้โดยตรง และพจนานุกรมก็มีความยืดหยุ่นสูงมากซึ่งอาจตรงกับสิ่งที่กรณีการใช้งานของคุณต้องการ อย่างไรก็ตาม วิธีนี้ไม่ปลอดภัยต่อประเภท และการสะกดชื่อแอตทริบิวต์ผิดหรือลืมแมปแอตทริบิวต์ใหม่ที่ทีมของคุณเพิ่มเข้าไปเมื่อสัปดาห์ที่แล้วที่เผยแพร่ฟีเจอร์ใหม่ที่น่าตื่นเต้นนั้นอาจทำให้เกิดข้อบกพร่องที่ติดตามได้ยาก
ในอดีต นักพัฒนาซอฟต์แวร์จำนวนมากได้หลีกเลี่ยงข้อบกพร่องเหล่านี้โดยการติดตั้งใช้งานเลเยอร์การแมปอย่างง่ายที่ช่วยให้แมปพจนานุกรมกับประเภท Swift ได้ แต่การติดตั้งใช้งานส่วนใหญ่ยังคงอิงตามการระบุการแมประหว่างเอกสาร Cloud Firestore กับประเภทที่เกี่ยวข้องของโมเดลข้อมูลของแอปด้วยตนเอง
การรองรับ Codable API ของ Swift ใน Cloud Firestore ทำให้การดำเนินการนี้ง่ายขึ้นมาก
- คุณไม่จำเป็นต้องติดตั้งใช้งานโค้ดการแมปด้วยตนเองอีกต่อไป
- กำหนดวิธีแมปแอตทริบิวต์ที่มีชื่อต่างๆ ได้ง่าย
- รองรับประเภทต่างๆ ของ Swift ในตัว
- และเพิ่มการรองรับการแมปประเภทที่กำหนดเองได้ง่าย
- ที่สำคัญที่สุดคือสำหรับโมเดลข้อมูลอย่างง่าย คุณไม่จำเป็นต้องเขียนโค้ดการแมปเลย
การแมปข้อมูล
Cloud Firestore จัดเก็บข้อมูลในเอกสารที่แมปคีย์กับค่า หากต้องการดึง
ข้อมูลจากเอกสารแต่ละรายการ เราสามารถเรียก DocumentSnapshot.data() ซึ่ง
จะแสดงผลพจนานุกรมที่แมปชื่อฟิลด์กับ Any ดังนี้
func data() -> [String : Any]?
ซึ่งหมายความว่าเราสามารถใช้ไวยากรณ์ตัวห้อยของ Swift เพื่อเข้าถึงแต่ละฟิลด์ได้
import FirebaseFirestore
#warning("DO NOT MAP YOUR DOCUMENTS MANUALLY. USE CODABLE INSTEAD.")
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
let id = document.documentID
let data = document.data()
let title = data?["title"] as? String ?? ""
let numberOfPages = data?["numberOfPages"] as? Int ?? 0
let author = data?["author"] as? String ?? ""
self.book = Book(id:id, title: title, numberOfPages: numberOfPages, author: author)
}
}
}
}
แม้ว่าโค้ดนี้อาจดูตรงไปตรงมาและติดตั้งใช้งานได้ง่าย แต่ก็มีความเปราะบาง ดูแลรักษายาก และมีแนวโน้มที่จะเกิดข้อผิดพลาด
อย่างที่คุณเห็น เรากำลังตั้งสมมติฐานเกี่ยวกับประเภทข้อมูลของฟิลด์เอกสาร ซึ่งอาจถูกต้องหรือไม่ก็ได้
โปรดทราบว่าเนื่องจากไม่มีสคีมา คุณจึงเพิ่มเอกสารใหม่ลงในคอลเล็กชันและเลือกประเภทอื่นสำหรับฟิลด์ได้อย่างง่ายดาย คุณอาจเลือกสตริงสำหรับฟิลด์ numberOfPages โดยไม่ได้ตั้งใจ ซึ่งจะทำให้เกิดปัญหาการแมปที่ค้นหาได้ยาก นอกจากนี้ คุณจะต้องอัปเดตโค้ดการแมปทุกครั้งที่เพิ่มฟิลด์ใหม่ ซึ่งค่อนข้างยุ่งยาก
และอย่าลืมว่าเราไม่ได้ใช้ประโยชน์จากระบบประเภทที่เข้มงวดของ Swift ซึ่งทราบประเภทที่ถูกต้องสำหรับพร็อพเพอร์ตี้แต่ละรายการของ Book
Codable คืออะไร
ตามเอกสารประกอบของ Apple ระบุว่า Codable คือ "ประเภทที่สามารถแปลงตัวเองเป็นและออกจากตัวแทนภายนอกได้" อันที่จริงแล้ว Codable เป็นนามแฝงประเภทสำหรับโปรโตคอล Encodable และ Decodable การทำให้ประเภท Swift เป็นไปตามโปรโตคอลนี้จะทำให้คอมไพเลอร์สังเคราะห์โค้ดที่จำเป็นในการเข้ารหัส/ถอดรหัสอินสแตนซ์ของประเภทนี้จากรูปแบบที่ซีเรียลไลซ์ เช่น JSON
ประเภทอย่างง่ายสำหรับการจัดเก็บข้อมูลเกี่ยวกับหนังสืออาจมีลักษณะดังนี้
struct Book: Codable {
var title: String
var numberOfPages: Int
var author: String
}
อย่างที่คุณเห็น การทำให้ประเภทเป็นไปตาม Codable นั้นรบกวนน้อยมาก เราเพียงแค่ต้องเพิ่มการปฏิบัติตามโปรโตคอลเท่านั้น ไม่จำเป็นต้องเปลี่ยนแปลงอื่นๆ
เมื่อดำเนินการนี้แล้ว ตอนนี้เราก็สามารถเข้ารหัสหนังสือเป็นออบเจ็กต์ JSON ได้อย่างง่ายดาย
do {
let book = Book(title: "The Hitchhiker's Guide to the Galaxy",
numberOfPages: 816,
author: "Douglas Adams")
let encoder = JSONEncoder()
let data = try encoder.encode(book)
}
catch {
print("Error when trying to encode book: \(error)")
}
การถอดรหัสออบเจ็กต์ JSON เป็นอินสแตนซ์ Book มีลักษณะดังนี้
let decoder = JSONDecoder()
let data = /* fetch data from the network */
let decodedBook = try decoder.decode(Book.self, from: data)
การแมปไปยังและจากประเภทอย่างง่ายในเอกสาร Cloud Firestore โดยใช้ Codable
Cloud Firestore รองรับข้อมูลหลากหลายประเภท ตั้งแต่ สตริงอย่างง่ายไปจนถึงแผนที่ซ้อนกัน ข้อมูลเหล่านี้ส่วนใหญ่สอดคล้องกับประเภทในตัวของ Swift โดยตรง เรามาดูการแมปข้อมูลบางประเภทอย่างง่ายก่อนที่จะเจาะลึกข้อมูลที่ซับซ้อนมากขึ้น
หากต้องการแมปเอกสาร Cloud Firestore กับประเภท Swift ให้ทำตามขั้นตอนต่อไปนี้
- ตรวจสอบว่าคุณได้เพิ่มเฟรมเวิร์ก
FirebaseFirestoreลงในโปรเจ็กต์แล้ว คุณสามารถใช้ Swift Package Manager หรือ CocoaPods ก็ได้ - นำเข้า
FirebaseFirestoreลงในไฟล์ Swift - ทำให้ประเภทเป็นไปตาม
Codable - (ไม่บังคับ หากต้องการใช้ประเภทในมุมมอง
List) เพิ่มพร็อพเพอร์ตี้idลงในประเภท และใช้@DocumentIDเพื่อบอก Cloud Firestore ให้ แมปพร็อพเพอร์ตี้นี้กับรหัสเอกสาร เราจะพูดถึงเรื่องนี้โดยละเอียดเพิ่มเติมด้านล่าง - ใช้
documentReference.data(as: )เพื่อแมปการอ้างอิงเอกสารกับประเภท Swift - ใช้
documentReference.setData(from: )เพื่อแมปข้อมูลจากประเภท Swift กับเอกสาร Cloud Firestore - (ไม่บังคับ แต่แนะนำอย่างยิ่ง) ติดตั้งใช้งานการจัดการข้อผิดพลาดที่เหมาะสม
มาอัปเดตประเภท Book ตามความเหมาะสมกัน
struct Book: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
}
เนื่องจากประเภทนี้เข้ารหัสได้อยู่แล้ว เราจึงเพียงแค่ต้องเพิ่มพร็อพเพอร์ตี้ id และใส่คำอธิบายประกอบด้วยตัวห่อพร็อพเพอร์ตี้ @DocumentID
เมื่อใช้ข้อมูลโค้ดก่อนหน้านี้สำหรับการดึงข้อมูลและแมปเอกสาร เราสามารถแทนที่โค้ดการแมปด้วยตนเองทั้งหมดด้วยโค้ดบรรทัดเดียวได้ดังนี้
func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument { document, error in
if let error = error as NSError? {
self.errorMessage = "Error getting document: \(error.localizedDescription)"
}
else {
if let document = document {
do {
self.book = try document.data(as: Book.self)
}
catch {
print(error)
}
}
}
}
}
คุณสามารถเขียนโค้ดนี้ให้กระชับยิ่งขึ้นได้โดยการระบุประเภทของเอกสารเมื่อเรียก getDocument(as:) ซึ่งจะทำการแมปให้คุณและแสดงผลประเภท Result ที่มีเอกสารที่แมปแล้ว หรือข้อผิดพลาดในกรณีที่การถอดรหัสล้มเหลว
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
การอัปเดตเอกสารที่มีอยู่ทำได้ง่ายเพียงแค่เรียก documentReference.setData(from: ) โค้ดต่อไปนี้แสดงวิธีบันทึกอินสแตนซ์ Book โดยมีการจัดการข้อผิดพลาดพื้นฐาน
func updateBook(book: Book) {
if let id = book.id {
let docRef = db.collection("books").document(id)
do {
try docRef.setData(from: book)
}
catch {
print(error)
}
}
}
เมื่อเพิ่มเอกสารใหม่ Cloud Firestore จะจัดการ การกำหนดรหัสเอกสารใหม่ให้กับเอกสารโดยอัตโนมัติ ซึ่งจะทำงานได้แม้ว่าแอปจะออฟไลน์อยู่ก็ตาม
func addBook(book: Book) {
let collectionRef = db.collection("books")
do {
let newDocReference = try collectionRef.addDocument(from: self.book)
print("Book stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
นอกจากจะแมปข้อมูลประเภทอย่างง่ายแล้ว Cloud Firestore ยังรองรับข้อมูลประเภทอื่นๆ อีกมากมาย ซึ่งบางประเภทเป็นประเภทที่มีโครงสร้างที่คุณสามารถใช้สร้างออบเจ็กต์ที่ซ้อนกันภายในเอกสารได้
ประเภทที่กำหนดเองที่ซ้อนกัน
แอตทริบิวต์ส่วนใหญ่ที่เราต้องการแมปในเอกสารเป็นค่าอย่างง่าย เช่น ชื่อหนังสือหรือชื่อผู้เขียน แต่ในกรณีที่เราต้องจัดเก็บออบเจ็กต์ที่ซับซ้อนมากขึ้นล่ะ เราจะทำอย่างไร ตัวอย่างเช่น เราอาจต้องการจัดเก็บ URL ของปกหนังสือในความละเอียดต่างๆ
วิธีที่ง่ายที่สุดในการดำเนินการนี้ใน Cloud Firestore คือการใช้แผนที่

เมื่อเขียนโครงสร้าง Swift ที่เกี่ยวข้อง เราสามารถใช้ประโยชน์จากข้อเท็จจริงที่ว่า Cloud Firestore รองรับ URL กล่าวคือ เมื่อจัดเก็บฟิลด์ที่มี URL ระบบจะแปลง URL เป็นสตริงและในทางกลับกัน:
struct CoverImages: Codable {
var small: URL
var medium: URL
var large: URL
}
struct BookWithCoverImages: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var cover: CoverImages?
}
โปรดสังเกตวิธีที่เรากำหนดโครงสร้าง CoverImages สำหรับแผนที่ปกในเอกสาร
Cloud Firestore การทำเครื่องหมายพร็อพเพอร์ตี้ปกใน BookWithCoverImages เป็นพร็อพเพอร์ตี้ที่ไม่บังคับช่วยให้เราจัดการกับข้อเท็จจริงที่ว่าเอกสารบางรายการอาจไม่มีแอตทริบิวต์ปกได้
หากคุณสงสัยว่าเหตุใดจึงไม่มีข้อมูลโค้ดสำหรับการดึงข้อมูลหรืออัปเดตข้อมูล คุณจะยินดีที่ทราบว่าไม่จำเป็นต้องปรับโค้ดสำหรับการอ่าน หรือเขียนจาก/ไปยัง Cloud Firestore: เนื่องจากโค้ดที่เราเขียนไว้ในส่วนเริ่มต้นจะทำงานได้
อาร์เรย์
บางครั้งเราต้องการจัดเก็บคอลเล็กชันของค่าในเอกสาร ประเภทของหนังสือเป็นตัวอย่างที่ดี เช่น หนังสืออย่าง The Hitchhiker's Guide to the Galaxy อาจอยู่ในหลายหมวดหมู่ ในกรณีนี้คือ "Sci-Fi" และ "Comedy"

ใน Cloud Firestore เราสามารถสร้างโมเดลนี้โดยใช้อาร์เรย์ของค่า ซึ่งรองรับประเภทที่เข้ารหัสได้ (เช่น String, Int ฯลฯ) ตัวอย่างต่อไปนี้แสดงวิธีเพิ่มอาร์เรย์ของประเภทลงในโมเดล Book
public struct BookWithGenre: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var genres: [String]
}
เนื่องจากวิธีนี้ใช้ได้กับประเภทที่เข้ารหัสได้ทุกประเภท เราจึงใช้ประเภทที่กำหนดเองได้ด้วย สมมติว่าเราต้องการจัดเก็บรายการแท็กสำหรับหนังสือแต่ละเล่ม นอกจากชื่อแท็กแล้ว เรายังต้องการจัดเก็บสีของแท็กด้วย เช่น
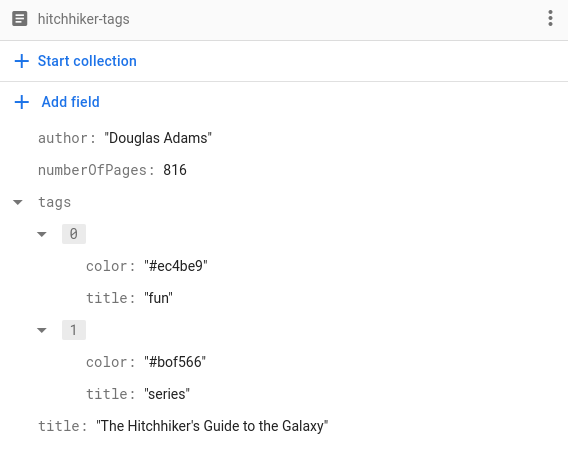
หากต้องการจัดเก็บแท็กด้วยวิธีนี้ สิ่งที่เราต้องทำคือติดตั้งใช้งานโครงสร้าง Tag เพื่อแสดงแท็กและทำให้แท็กเข้ารหัสได้
struct Tag: Codable, Hashable {
var title: String
var color: String
}
เพียงเท่านี้ เราก็สามารถจัดเก็บอาร์เรย์ของ Tags ในเอกสาร Book ได้แล้ว
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
หมายเหตุสั้นๆ เกี่ยวกับการแมปรหัสเอกสาร
ก่อนที่จะพูดถึงการแมปประเภทอื่นๆ เรามาพูดถึงการแมปรหัสเอกสารกันสักครู่
เราใช้ตัวห่อพร็อพเพอร์ตี้ @DocumentID ในตัวอย่างก่อนหน้านี้บางตัวอย่าง
เพื่อแมปรหัสเอกสารของเอกสาร Cloud Firestore กับพร็อพเพอร์ตี้ id ของประเภท Swift ซึ่งมีความสำคัญด้วยเหตุผลหลายประการดังนี้
- ช่วยให้เรารู้ว่าต้องอัปเดตเอกสารใดในกรณีที่ผู้ใช้ทำการเปลี่ยนแปลงในเครื่อง
Listของ SwiftUI กำหนดให้องค์ประกอบเป็นIdentifiableเพื่อป้องกันไม่ให้องค์ประกอบกระโดดไปมาเมื่อมีการแทรก
โปรดทราบว่าตัวเข้ารหัสของ Cloud Firestore จะไม่
เข้ารหัสแอตทริบิวต์ที่ทำเครื่องหมายเป็น @DocumentID เมื่อเขียนเอกสารกลับ เนื่องจากรหัสเอกสารไม่ใช่แอตทริบิวต์ของเอกสารเอง ดังนั้นการเขียนรหัสเอกสารลงในเอกสารจึงเป็นข้อผิดพลาด
เมื่อทำงานกับประเภทที่ซ้อนกัน (เช่น อาร์เรย์ของแท็กใน Book ในตัวอย่างก่อนหน้านี้ในคู่มือนี้) คุณไม่จำเป็นต้องเพิ่มพร็อพเพอร์ตี้ @DocumentID เนื่องจากพร็อพเพอร์ตี้ที่ซ้อนกันเป็นส่วนหนึ่งของเอกสาร Cloud Firestore และไม่ได้ประกอบขึ้นเป็นเอกสารแยกต่างหาก ดังนั้นจึงไม่จำเป็นต้องมีรหัสเอกสาร
วันที่และเวลา
Cloud Firestore มีข้อมูลประเภทในตัวสำหรับการจัดการวันที่และเวลา และ การรองรับ Codable ของ Cloud Firestore ทำให้การใช้งานข้อมูลประเภทเหล่านี้เป็นเรื่องง่าย
มาดูเอกสารนี้ซึ่งแสดงถึงภาษาโปรแกรม Ada ซึ่งเป็นภาษาโปรแกรมภาษาแรกของโลกที่คิดค้นขึ้นในปี 1843

ประเภท Swift สำหรับการแมปเอกสารนี้อาจมีลักษณะดังนี้
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
}
เราไม่สามารถพูดถึงวันที่และเวลาโดยไม่พูดถึง @ServerTimestamp ได้ ตัวห่อพร็อพเพอร์ตี้นี้มีประสิทธิภาพมากเมื่อต้องจัดการกับไทม์สแตมป์ในแอป
ในระบบแบบกระจาย มีโอกาสที่นาฬิกาในระบบแต่ละระบบจะไม่ซิงค์กันอย่างสมบูรณ์ตลอดเวลา คุณอาจคิดว่าเรื่องนี้ไม่ใช่เรื่องใหญ่ แต่ลองนึกถึงผลกระทบที่อาจเกิดขึ้นหากนาฬิกาทำงานไม่ซิงค์กันเล็กน้อยในระบบการซื้อขายหุ้น แม้แต่ความคลาดเคลื่อนเพียงมิลลิวินาทีก็อาจส่งผลให้เกิดความแตกต่างหลายล้านดอลลาร์เมื่อทำการซื้อขาย
Cloud Firestore จะจัดการแอตทริบิวต์ที่ทำเครื่องหมายด้วย @ServerTimestamp ดังนี้ หากแอตทริบิวต์เป็น nil เมื่อคุณจัดเก็บแอตทริบิวต์ (เช่น ใช้ addDocument()) Cloud Firestore จะป้อนข้อมูลฟิลด์ด้วยไทม์สแตมป์ของเซิร์ฟเวอร์ปัจจุบันในขณะที่เขียนลงในฐานข้อมูล หากฟิลด์ไม่ใช่ nil
เมื่อคุณเรียก addDocument() หรือ updateData() Cloud Firestore จะไม่เปลี่ยนแปลง
ค่าแอตทริบิวต์ วิธีนี้ทำให้ติดตั้งใช้งานฟิลด์ต่างๆ เช่น createdAt และ lastUpdatedAt ได้ง่าย
จุดทางภูมิศาสตร์
ตำแหน่งทางภูมิศาสตร์มีอยู่ทุกหนทุกแห่งในแอปของเรา การจัดเก็บตำแหน่งทางภูมิศาสตร์ทำให้เกิดฟีเจอร์ที่น่าตื่นเต้นมากมาย ตัวอย่างเช่น การจัดเก็บตำแหน่งสำหรับงานอาจมีประโยชน์เพื่อให้แอปช่วยเตือนคุณเกี่ยวกับงานเมื่อคุณไปถึงปลายทาง
Cloud Firestore มีข้อมูลประเภทในตัว GeoPoint ซึ่งจัดเก็บ
ลองจิจูดและละติจูดของตำแหน่งใดก็ได้ หากต้องการแมปตำแหน่งจาก/ไปยังเอกสาร
Cloud Firestore เราสามารถใช้ประเภท GeoPoint ได้ดังนี้
struct Office: Codable {
@DocumentID var id: String?
var name: String
var location: GeoPoint
}
ประเภทที่เกี่ยวข้องใน Swift คือ CLLocationCoordinate2D และเราสามารถแมประหว่างข้อมูลประเภททั้ง 2 นี้ได้ด้วยการดำเนินการต่อไปนี้
CLLocationCoordinate2D(latitude: office.location.latitude,
longitude: office.location.longitude)
ดูข้อมูลเพิ่มเติมเกี่ยวกับการค้นหาเอกสารตามตำแหน่งทางกายภาพได้ใน คู่มือโซลูชันนี้
enum
enum อาจเป็นฟีเจอร์ภาษาที่ถูกประเมินต่ำที่สุดอย่างหนึ่งใน Swift เนื่องจาก enum มีอะไรมากกว่าที่เห็น กรณีการใช้งานทั่วไปสำหรับ enum คือการสร้างโมเดลสถานะที่ไม่ต่อเนื่องของสิ่งใดสิ่งหนึ่ง ตัวอย่างเช่น เราอาจเขียนแอปสำหรับการจัดการบทความ หากต้องการติดตามสถานะของบทความ เราอาจต้องการใช้ enum Status ดังนี้
enum Status: String, Codable {
case draft
case inReview
case approved
case published
}
Cloud Firestore ไม่รองรับ enum โดยกำเนิด (กล่าวคือ ไม่สามารถบังคับใช้
ชุดค่าได้) แต่เรายังคงใช้ประโยชน์จากข้อเท็จจริงที่ว่า enum สามารถพิมพ์ได้
และเลือกประเภทที่เข้ารหัสได้ ในตัวอย่างนี้ เราเลือก String ซึ่งหมายความว่า
ค่า enum ทั้งหมดจะแมปเป็น/จากสตริงเมื่อจัดเก็บไว้ใน
Cloud Firestore เอกสาร
และเนื่องจาก Swift รองรับค่าดิบที่กำหนดเอง เราจึงกำหนดค่าที่อ้างอิงถึงเคส enum ใดได้ด้วย ตัวอย่างเช่น หากเราตัดสินใจจัดเก็บเคส Status.inReview เป็น "in review" เราก็เพียงแค่อัปเดต enum ด้านบนดังนี้
enum Status: String, Codable {
case draft
case inReview = "in review"
case approved
case published
}
การปรับแต่งการแมป
บางครั้งชื่อแอตทริบิวต์ของเอกสาร Cloud Firestore ที่เราต้องการ แมปไม่ตรงกับชื่อพร็อพเพอร์ตี้ในโมเดลข้อมูลของเราใน Swift ตัวอย่างเช่น เพื่อนร่วมงานคนหนึ่งของเราอาจเป็นนักพัฒนาซอฟต์แวร์ Python และตัดสินใจเลือก snake_case สำหรับชื่อแอตทริบิวต์ทั้งหมด
ไม่ต้องกังวล Codable ช่วยคุณได้
สำหรับกรณีเช่นนี้ เราสามารถใช้ CodingKeys ได้ ซึ่งเป็น enum ที่เราสามารถเพิ่มลงในโครงสร้างที่เข้ารหัสได้เพื่อระบุวิธีแมปแอตทริบิวต์บางรายการ
ลองดูเอกสารนี้

หากต้องการแมปเอกสารนี้กับโครงสร้างที่มีพร็อพเพอร์ตี้ชื่อประเภท String เราต้องเพิ่ม enum CodingKeys ลงในโครงสร้าง ProgrammingLanguage และระบุชื่อแอตทริบิวต์ในเอกสาร
struct ProgrammingLanguage: Codable {
@DocumentID var id: String?
var name: String
var year: Date
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
โดยค่าเริ่มต้น Codable API จะใช้ชื่อพร็อพเพอร์ตี้ของประเภท Swift เพื่อ
กำหนดชื่อแอตทริบิวต์ในเอกสาร Cloud Firestore ที่เราพยายาม
แมป ดังนั้นตราบใดที่ชื่อแอตทริบิวต์ตรงกัน ก็ไม่จำเป็นต้องเพิ่ม CodingKeys ลงในประเภทที่เข้ารหัสได้ อย่างไรก็ตาม เมื่อเราใช้ CodingKeys สำหรับประเภทใดประเภทหนึ่ง เราต้องเพิ่มชื่อพร็อพเพอร์ตี้ทั้งหมดที่ต้องการแมป
ในข้อมูลโค้ดด้านบน เราได้กำหนดพร็อพเพอร์ตี้ id ซึ่งเราอาจต้องการใช้เป็นตัวระบุในมุมมอง List ของ SwiftUI หากเราไม่ได้ระบุไว้ใน CodingKeys ระบบจะไม่แมปพร็อพเพอร์ตี้นี้เมื่อดึงข้อมูล และพร็อพเพอร์ตี้นี้จะกลายเป็น nil
ซึ่งจะส่งผลให้มุมมอง List เต็มไปด้วยเอกสารแรก
ระบบจะละเว้นพร็อพเพอร์ตี้ที่ไม่ได้ระบุไว้เป็นเคสใน enum CodingKeys ที่เกี่ยวข้องในระหว่างกระบวนการแมป ซึ่งอาจสะดวกหากเราต้องการยกเว้นพร็อพเพอร์ตี้บางรายการจากการแมปโดยเฉพาะ
ตัวอย่างเช่น หากเราต้องการยกเว้นพร็อพเพอร์ตี้ reasonWhyILoveThis จากการแมป สิ่งที่เราต้องทำคือนำพร็อพเพอร์ตี้นี้ออกจาก enum CodingKeys
struct ProgrammingLanguage: Identifiable, Codable {
@DocumentID var id: String?
var name: String
var year: Date
var reasonWhyILoveThis: String = ""
enum CodingKeys: String, CodingKey {
case id
case name = "language_name"
case year
}
}
บางครั้งเราอาจต้องการเขียนแอตทริบิวต์ที่ว่างเปล่ากลับลงใน
Cloud Firestore เอกสาร Swift มีแนวคิดเกี่ยวกับตัวเลือกเพื่อระบุว่าไม่มีค่า
และ Cloud Firestore ก็รองรับค่า null ด้วย
อย่างไรก็ตาม ลักษณะการทำงานเริ่มต้นสำหรับการเข้ารหัสตัวเลือกที่มีค่า nil คือการละเว้นตัวเลือกเหล่านั้น @ExplicitNull ช่วยให้เราควบคุมวิธีจัดการตัวเลือก Swift
เมื่อเข้ารหัสตัวเลือกเหล่านั้นได้ กล่าวคือ การทำเครื่องหมายพร็อพเพอร์ตี้ตัวเลือกเป็น
@ExplicitNull จะบอก Cloud Firestore ให้เขียนพร็อพเพอร์ตี้นี้ลงใน
เอกสารด้วยค่า null หากพร็อพเพอร์ตี้นี้มีค่า nil
การใช้ตัวเข้ารหัสและตัวถอดรหัสที่กำหนดเองสำหรับการแมปสี
หัวข้อสุดท้ายในการครอบคลุมการแมปข้อมูลด้วย Codable คือการแนะนำตัวเข้ารหัสและตัวถอดรหัสที่กำหนดเอง ส่วนนี้ไม่ได้ครอบคลุมข้อมูลประเภท Cloud Firestoreโดยกำเนิด แต่ตัวเข้ารหัสและตัวถอดรหัสที่กำหนดเองมีประโยชน์อย่างมาก ในแอปCloud Firestore
"ฉันจะแมปสีได้อย่างไร" เป็นหนึ่งในคำถามที่นักพัฒนาซอฟต์แวร์ถามบ่อยที่สุด ไม่ใช่แค่สำหรับ Cloud Firestore เท่านั้น แต่ยังรวมถึงการแมประหว่าง Swift กับ JSON ด้วย มีโซลูชันมากมาย แต่ส่วนใหญ่เน้นที่ JSON และเกือบทั้งหมดจะแมปสีเป็นพจนานุกรมที่ซ้อนกันซึ่งประกอบด้วยคอมโพเนนต์ RGB
ดูเหมือนว่าควรมีโซลูชันที่ดีกว่าและง่ายกว่า ทำไมเราไม่ใช้สีเว็บ (หรือพูดให้เจาะจงมากขึ้นคือสัญกรณ์สีฐานสิบหกของ CSS) เนื่องจากสีเว็บใช้งานง่าย (โดยพื้นฐานแล้วเป็นเพียงสตริง) และยังรองรับความโปร่งใสด้วย
หากต้องการแมป Color ของ Swift กับค่าฐานสิบหก เราต้องสร้างส่วนขยาย Swift ที่เพิ่ม Codable ลงใน Color
extension Color {
init(hex: String) {
let rgba = hex.toRGBA()
self.init(.sRGB,
red: Double(rgba.r),
green: Double(rgba.g),
blue: Double(rgba.b),
opacity: Double(rgba.alpha))
}
//... (code for translating between hex and RGBA omitted for brevity)
}
extension Color: Codable {
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let hex = try container.decode(String.self)
self.init(hex: hex)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(toHex)
}
}
การใช้ decoder.singleValueContainer() ช่วยให้เราถอดรหัส String เป็น Color ที่เทียบเท่าได้โดยไม่ต้องซ้อนคอมโพเนนต์ RGBA นอกจากนี้ คุณยังใช้ค่าเหล่านี้ใน UI เว็บของแอปได้โดยไม่ต้องแปลงค่าก่อน
เมื่อใช้ค่าเหล่านี้ เราจะอัปเดตโค้ดสำหรับการแมปแท็กได้ ซึ่งจะทำให้จัดการสีแท็กได้ง่ายขึ้นโดยตรงแทนที่จะต้องแมปสีด้วยตนเองในโค้ด UI ของแอป
struct Tag: Codable, Hashable {
var title: String
var color: Color
}
struct BookWithTags: Codable {
@DocumentID var id: String?
var title: String
var numberOfPages: Int
var author: String
var tags: [Tag]
}
การจัดการข้อผิดพลาด
ในข้อมูลโค้ดด้านบน เราจงใจจัดการข้อผิดพลาดให้น้อยที่สุด แต่ในแอปที่ใช้งานจริง คุณจะต้องจัดการข้อผิดพลาดอย่างเหมาะสม
ข้อมูลโค้ดต่อไปนี้แสดงวิธีจัดการสถานการณ์ข้อผิดพลาดที่คุณอาจพบ
class MappingSimpleTypesViewModel: ObservableObject {
@Published var book: Book = .empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
func fetchAndMap() {
fetchBook(documentId: "hitchhiker")
}
func fetchAndMapNonExisting() {
fetchBook(documentId: "does-not-exist")
}
func fetchAndTryMappingInvalidData() {
fetchBook(documentId: "invalid-data")
}
private func fetchBook(documentId: String) {
let docRef = db.collection("books").document(documentId)
docRef.getDocument(as: Book.self) { result in
switch result {
case .success(let book):
// A Book value was successfully initialized from the DocumentSnapshot.
self.book = book
self.errorMessage = nil
case .failure(let error):
// A Book value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self.errorMessage = "\(error.localizedDescription): \(key)"
default:
self.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
}
}
}
}
การจัดการข้อผิดพลาดในการอัปเดตแบบสด
ข้อมูลโค้ดก่อนหน้านี้แสดงวิธีจัดการข้อผิดพลาดเมื่อดึงข้อมูลเอกสารเดียว นอกจากการดึงข้อมูลเพียงครั้งเดียวแล้ว Cloud Firestore ยัง รองรับการส่งการอัปเดตไปยังแอปของคุณเมื่อมีการอัปเดตเกิดขึ้นโดยใช้สิ่งที่เรียกว่า Listener สแนปชอต กล่าวคือ เราสามารถลงทะเบียน Listener สแนปชอตในคอลเล็กชัน (หรือการค้นหา) และ Cloud Firestore จะเรียก Listener ของเราทุกครั้งที่มีการอัปเดต
ข้อมูลโค้ดต่อไปนี้แสดงวิธีลงทะเบียน Listener สแนปชอต แมปข้อมูลโดยใช้ Codable และจัดการข้อผิดพลาดที่อาจเกิดขึ้น นอกจากนี้ยังแสดงวิธีเพิ่มเอกสารใหม่ลงในคอลเล็กชันด้วย อย่างที่คุณเห็น ไม่จำเป็นต้องอัปเดตอาร์เรย์ในเครื่องที่เก็บเอกสารที่แมปด้วยตนเอง เนื่องจากโค้ดใน Listener สแนปชอตจะจัดการให้
class MappingColorsViewModel: ObservableObject {
@Published var colorEntries = [ColorEntry]()
@Published var newColor = ColorEntry.empty
@Published var errorMessage: String?
private var db = Firestore.firestore()
private var listenerRegistration: ListenerRegistration?
public func unsubscribe() {
if listenerRegistration != nil {
listenerRegistration?.remove()
listenerRegistration = nil
}
}
func subscribe() {
if listenerRegistration == nil {
listenerRegistration = db.collection("colors")
.addSnapshotListener { [weak self] (querySnapshot, error) in
guard let documents = querySnapshot?.documents else {
self?.errorMessage = "No documents in 'colors' collection"
return
}
self?.colorEntries = documents.compactMap { queryDocumentSnapshot in
let result = Result { try queryDocumentSnapshot.data(as: ColorEntry.self) }
switch result {
case .success(let colorEntry):
if let colorEntry = colorEntry {
// A ColorEntry value was successfully initialized from the DocumentSnapshot.
self?.errorMessage = nil
return colorEntry
}
else {
// A nil value was successfully initialized from the DocumentSnapshot,
// or the DocumentSnapshot was nil.
self?.errorMessage = "Document doesn't exist."
return nil
}
case .failure(let error):
// A ColorEntry value could not be initialized from the DocumentSnapshot.
switch error {
case DecodingError.typeMismatch(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.valueNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.keyNotFound(_, let context):
self?.errorMessage = "\(error.localizedDescription): \(context.debugDescription)"
case DecodingError.dataCorrupted(let key):
self?.errorMessage = "\(error.localizedDescription): \(key)"
default:
self?.errorMessage = "Error decoding document: \(error.localizedDescription)"
}
return nil
}
}
}
}
}
func addColorEntry() {
let collectionRef = db.collection("colors")
do {
let newDocReference = try collectionRef.addDocument(from: newColor)
print("ColorEntry stored with new document reference: \(newDocReference)")
}
catch {
print(error)
}
}
}
ข้อมูลโค้ดทั้งหมดที่ใช้ในโพสต์นี้เป็นส่วนหนึ่งของแอปพลิเคชันตัวอย่างที่คุณ ดาวน์โหลดได้จาก ที่เก็บ GitHub นี้
ไปใช้ Codable กันเลย
Codable API ของ Swift เป็นวิธีที่มีประสิทธิภาพและยืดหยุ่นในการแมปข้อมูลจากรูปแบบที่ซีเรียลไลซ์ไปยังและจากโมเดลข้อมูลของแอปพลิเคชัน ในคู่มือนี้ คุณได้เห็นแล้วว่าการใช้งานในแอปที่ใช้ Cloud Firestore เป็น Datastore นั้นง่ายเพียงใด
เราเริ่มจากตัวอย่างพื้นฐานที่มีข้อมูลประเภทอย่างง่าย จากนั้นค่อยๆ เพิ่มความซับซ้อนของโมเดลข้อมูล โดยที่ยังคงใช้ Codable และการติดตั้งใช้งานของ Firebase เพื่อทำการแมปให้เราได้
ดูรายละเอียดเพิ่มเติมเกี่ยวกับ Codable ได้จากแหล่งข้อมูลต่อไปนี้
- John Sundell มีบทความดีๆ เกี่ยวกับ พื้นฐานของ Codable
- หากคุณชอบหนังสือมากกว่า โปรดดูคู่มือ Flight School Guide to Swift Codable ของ Mattt
- และสุดท้าย Donny Wals มีซีรีส์ทั้งหมดเกี่ยวกับ Codable
แม้ว่าเราจะพยายามอย่างสุดความสามารถในการรวบรวมคู่มือที่ครอบคลุมสำหรับการแมป Cloud Firestore เอกสาร แต่คู่มือนี้ก็ไม่ได้ครอบคลุมทุกอย่าง และคุณอาจใช้ กลยุทธ์อื่นๆ ในการแมปประเภทของคุณ โปรดแจ้งให้เราทราบกลยุทธ์ที่คุณใช้ในการแมปข้อมูลประเภทอื่นๆ หรือแสดงข้อมูลใน Swift โดยใช้ปุ่มส่งความคิดเห็น ด้านล่าง Cloud Firestore
ไม่มีเหตุผลใดเลยที่จะไม่ใช้การรองรับ Codable ของ Cloud Firestore